Резервное копирование и восстановление работы ETCD
Создать резервную копию ETCD
В платформе “Штурвал” вы можете создать резервную копию ETCD с помощью объекта NCI. Резервное копирование данных кластера ETCD может понадобиться для восстановления кластера. Рекомендуется выполнять резервное копирования в период наименьшей нагрузки на кластер.
- Подготовьте скрипт для резервного копирования, например, с именем
etcdbackup.sh.
Пример скрипта etcdbackup.sh
#!/bin/sh
# Проверка запуска из-под root
if [[ $EUID -ne 0 ]]; then
echo "This script must berun as root"
exit 1
fi
# Проверка установки etcdctl для выполнения резервного копирования
if which etcdctl > /dev/null; then
echo etcdctl found
else
fi
function usage {
echo 'Path to backup dir required: ./cluster-backup.sh <path-to-backup-dir>'
exit 1
}
# If the first argument is missing, or it is an existing file, then print usage and exit
if [ -z "$1" ] || [ -f "$1" ]; then
usage
fi
# Проверка существования манифестов
function checkManifests {
echo 'No manifsts found in /etc/kubernetes/manifests'
exit 1
}
if [ -z "$(ls /etc/kubernetes/manifests/)" ];then
checkManifests
fi
function checkStatus () {
status=$?
if test $status -eq 0
then
echo "passed $1"
else
echo "failed $1"
exit 1
fi
}
# Объявление переменных
archive="$(hostname)-$(date '+%F_%H%M%S').tar.gz" # Имя резервной копии ETCD
backupdate="$1/backup/" # Расположение резервной копии ETCD
mkdir -p $backupdate/manifests # Директория для резервной копии манифестов ETCD
mkdir -p $backupdate/etcd # Директория для резервной копии ETCD
# Получение данных для подключения и создание резервной копии (snapshot)
ETCDCTL_API=3 \
ETCDCTL_CACERT='/etc/kubernetes/pki/etcd/ca.crt' \
ETCDCTL_CERT='/etc/kubernetes/pki/etcd/server.crt' \
ETCDCTL_KEY='/etc/kubernetes/pki/etcd/server.key' \
ETCDCTL_ENDPOINTS='https://XX.XX.XX.XX:2379' \
/usr/local/bin/etcdctl snapshot save $backupdate/etcd/etcd.snapshot ;
checkStatus "etcd backup"
cp -r /etc/kubernetes/manifests/* $backupdate/manifests/
checkStatus "Create copies of static manifests"
echo "Manifests saved at $backupdate/manifests"
# Бэкапирование secrets_encryption.yaml необходимо для кластеров с расширенными параметрами безопасности (secure=true)
cp /etc/kubernetes/secrets_encryption.yaml $backupdate/etcd/ >/dev/null 2>&1
echo "Create copies of secrets_encryption.yaml"
echo "Archiving backup...."
tar -zcf $1/$archive $backupdate 2> /dev/null
checkStatus "archiving file"
echo "Backup archiving finished"
chmod 666 $1/$archive
echo "Backup archive is located in $1/archive"
# Удаление архивов с резервной копией старше 3-х дней
find /tmp/ -name "*.tar.gz" -mtime +3 -delete
checkStatus "removing old backups"
echo Backup finished
exit 0
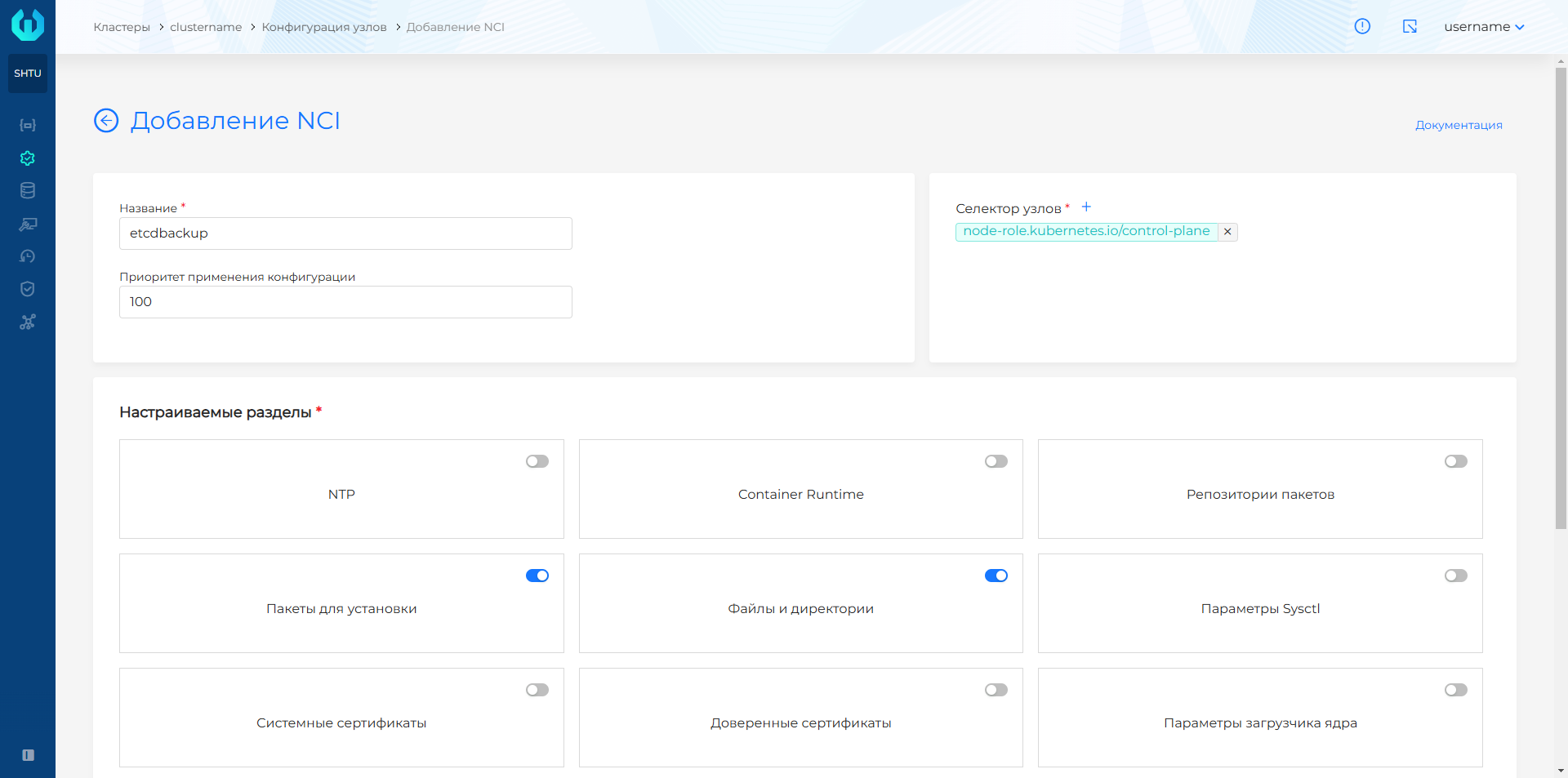
- В графическом интерфейсе кластера откройте страницу Конфигурация узлов раздела Администрирование, нажмите + Добавить NCI. На странице добавления NCI:
- Задайте имя, например, etcdbackup и в селекторе узлов из выпадающего списка выберите ключ лейбла node-role.kubernetes.io/control-plane. Значение для лейбла не устанавливайте.
- В блоке Настраиваемые разделы выберите Файлы и директории и Пакеты для установки, нажмите Продолжить.
Скриншот
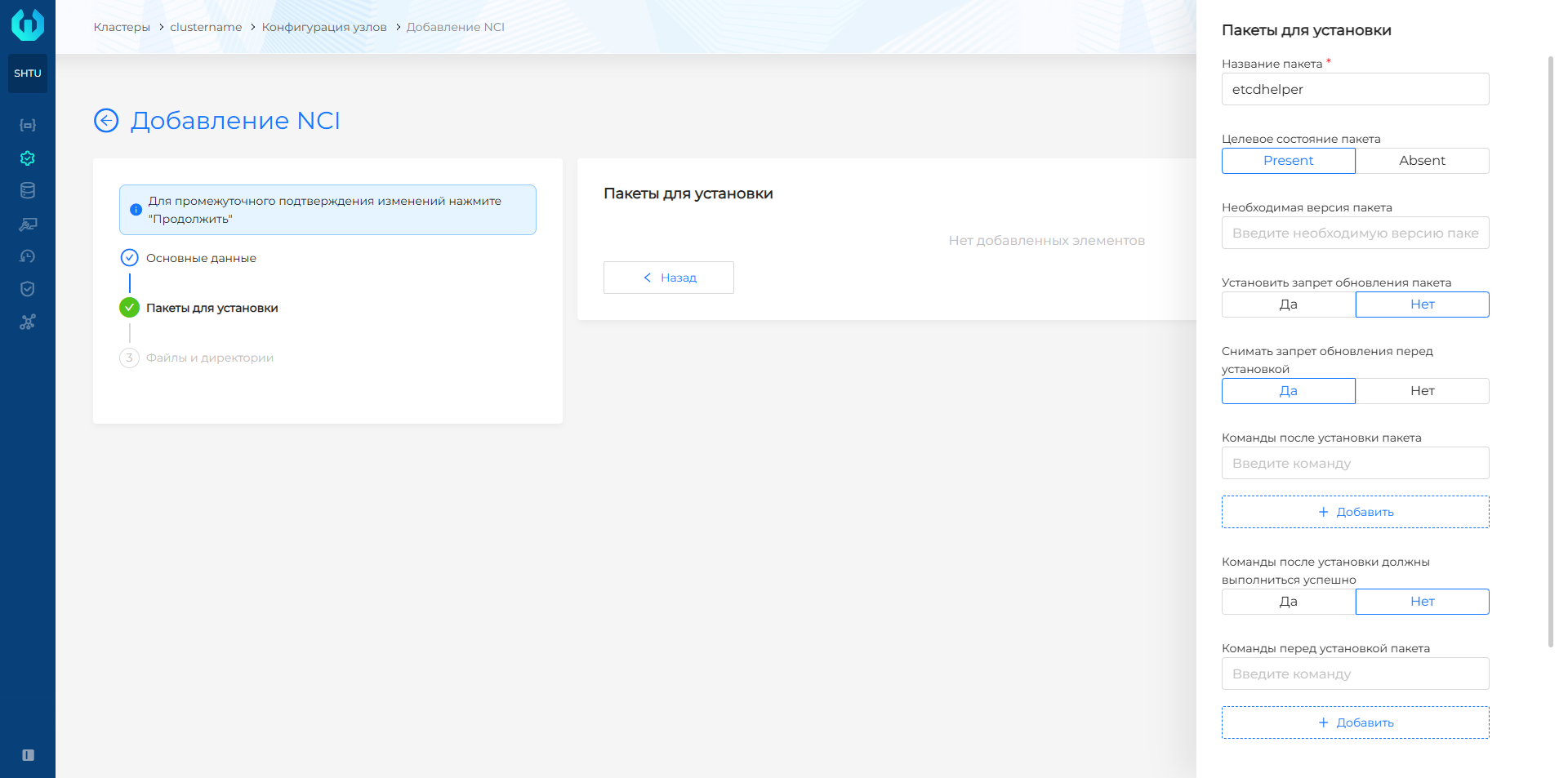
- В открывшемся окне на шаге конфигурации раздела Пакеты для установки нажмите + и укажите пакет
etcdhelper, выберите целевое состояние пакета Present.
Скриншот
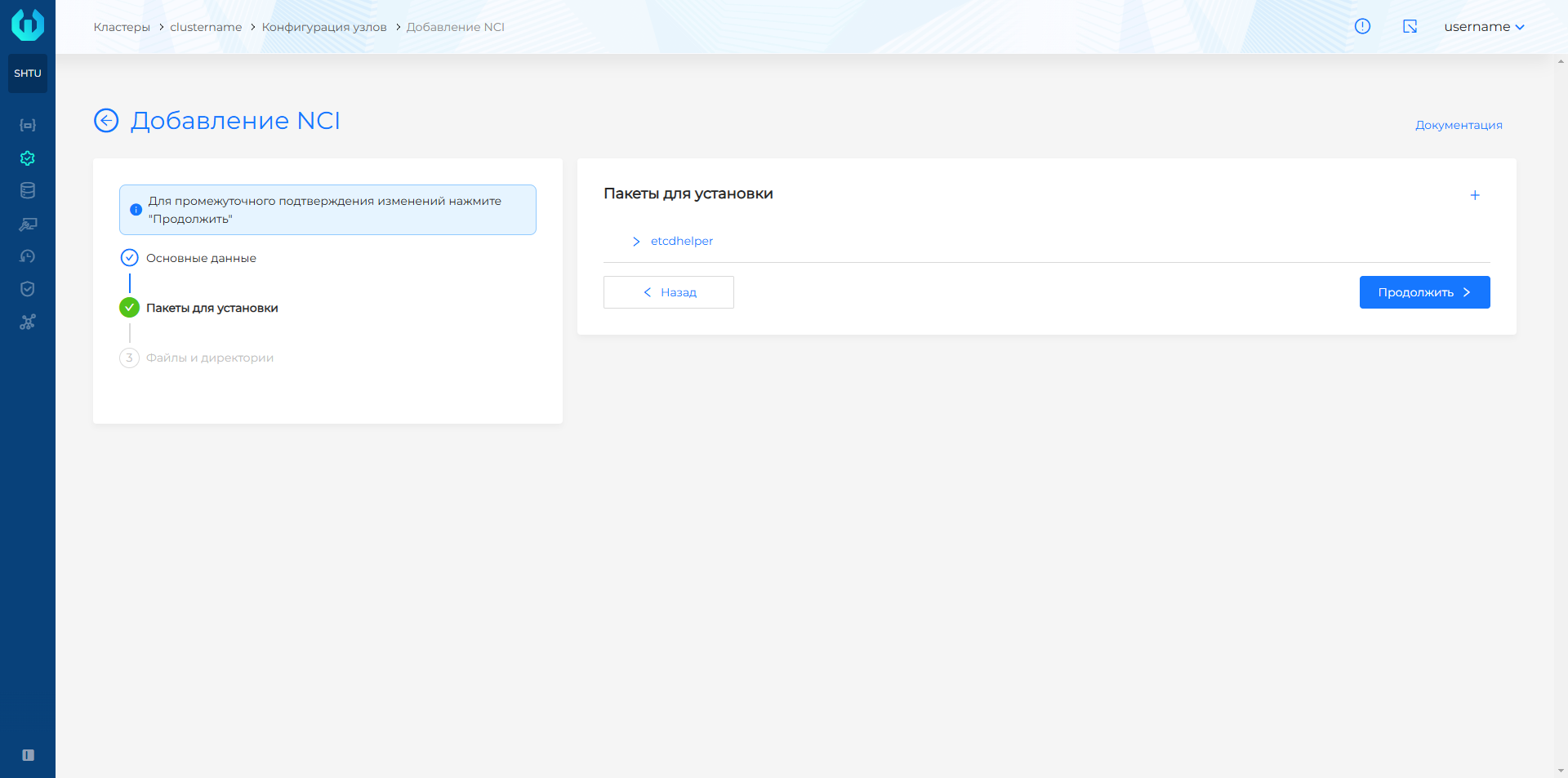
- Нажмите Добавить и затем Продолжить, чтобы перейти к разделу Файлы и директории.
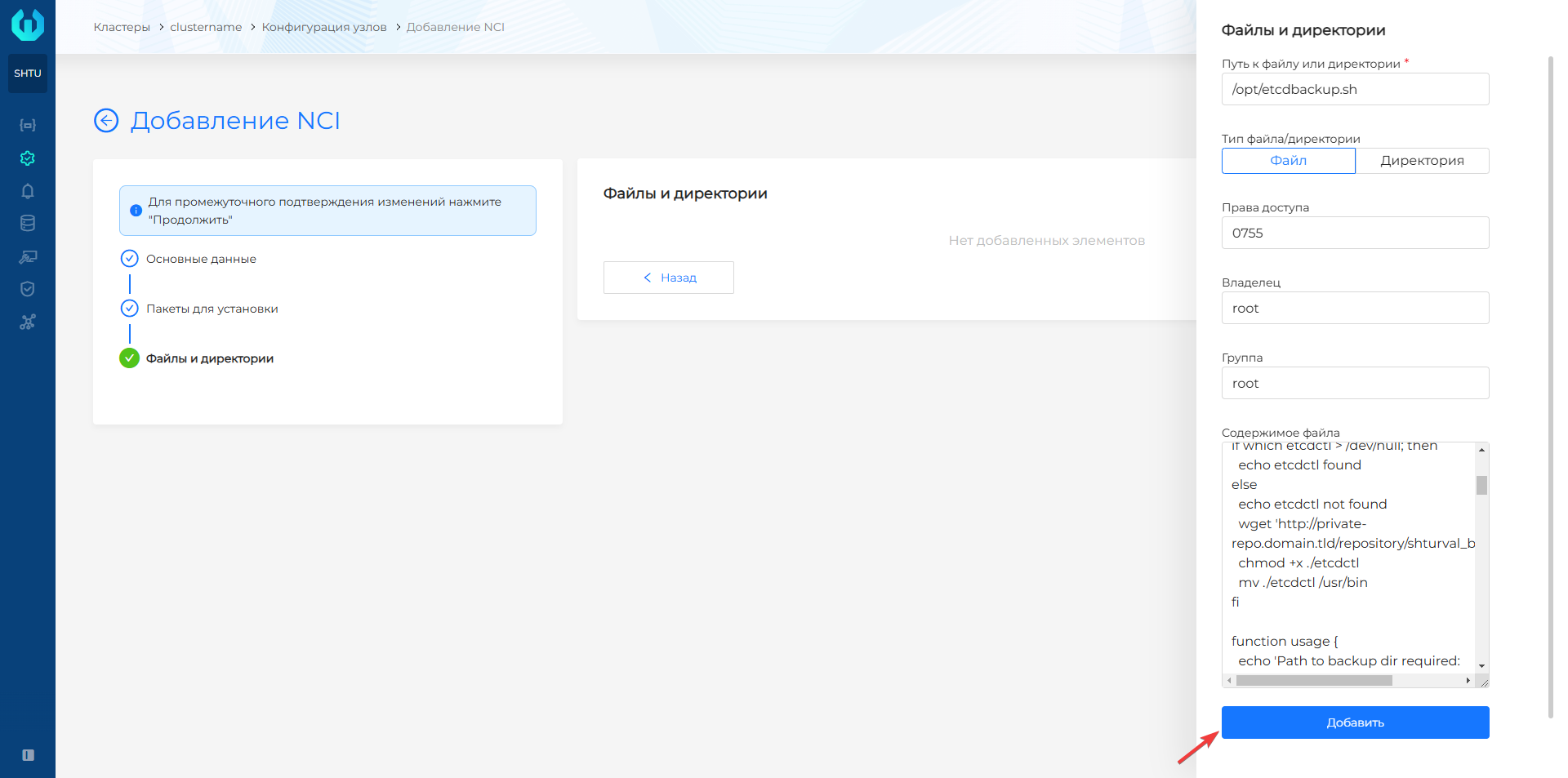
- На шаге Файлы и директории нажмите + и в поле Путь к файлу или директории пропишите путь до создаваемого файла со скриптом резервного копирования. В типе файла/директории должно быть выбрано Файл.
- В поле права доступа укажите необходимые права, например, 0755, что обеспечит владельцу полный доступ к файлу, группе владельца другим пользователям доступ на чтение и выполнение. Владелец и группа должны быть root.
- В поле Содержимое файла вставьте содержимое подготовленного скрипта из файла
etcdbackup.sh, нажмите Добавить.
Скриншот
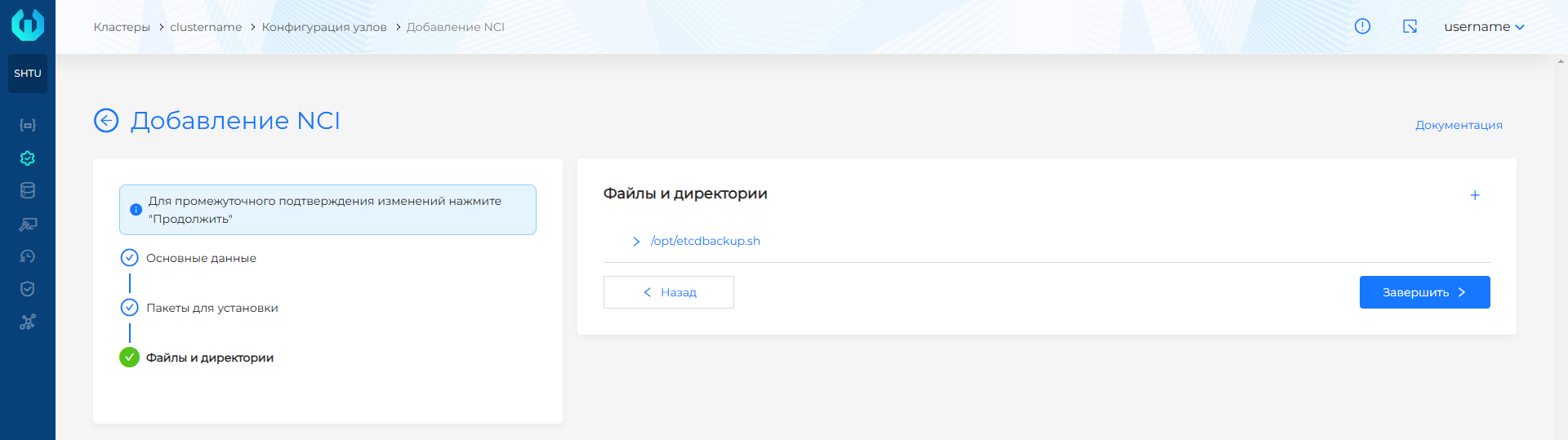
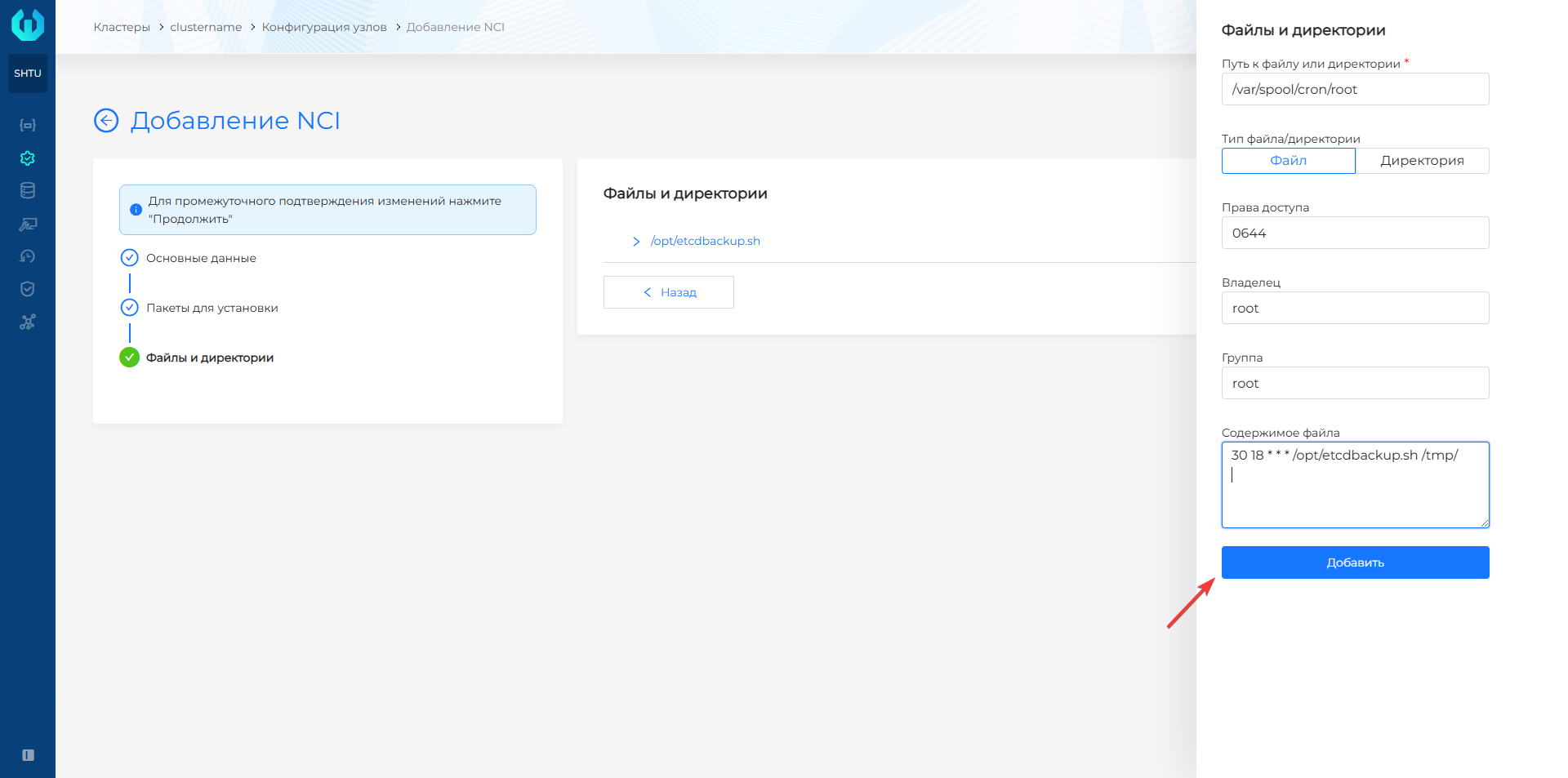
- Нажмите + и в поле Путь к файлу или директории пропишите путь до файла с расписанием запуска резервного копирования.
- В поле права доступа укажите необходимые права, например, 0600, что обеспечит правами только владельца файла на чтение и запись. Владелец и группа должны быть root.
- В поле Содержимое файла укажите конфигурацию запуска резервного копирования: расписание в cron формате, путь до файла со скриптом и путь до создаваемой резервной копии ETCD. В поле Содержимое файла после записи конфигурации запуска требуется выполнить перенос строки.
- Нажмите Добавить. Обратите внимание! Рекомендуется хранить резервную копию ETCD в сетевой файловой системе не на Master-узлах, а, например,
/nfs/share. Это может быть полезным в случае недоступности Master-узлов.
Пример конфигурации запуска
30 18 * * * /opt/etcdbackup.sh /tmp/
Скриншот
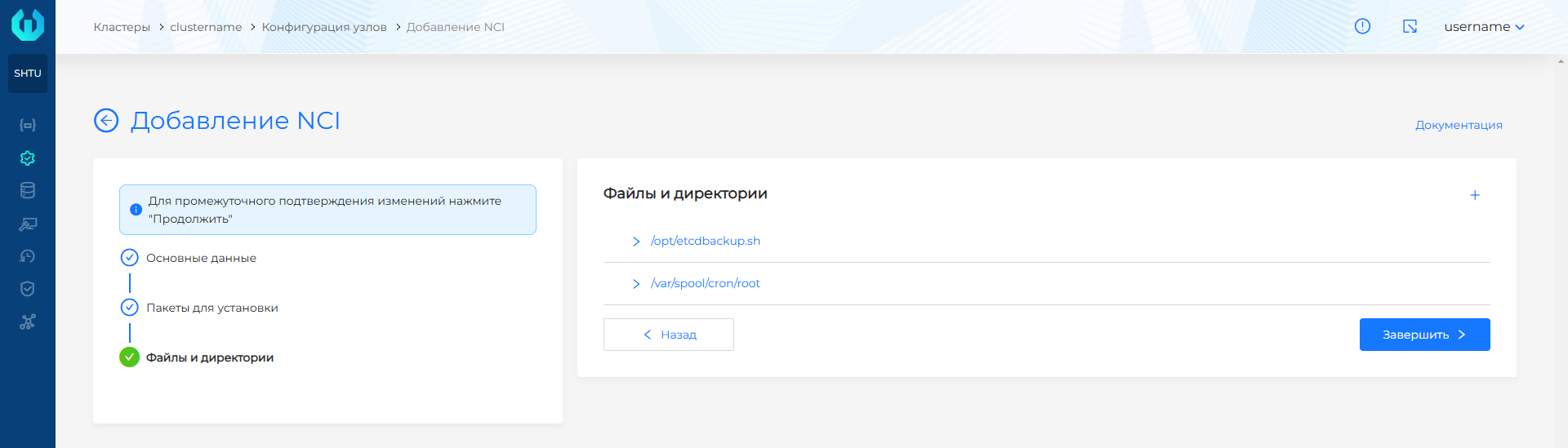
- Нажмите Завершить.
Пример NCI
apiVersion: node.shturval.tech/v1beta2
kind: NodeConfigItem
metadata:
annotations:
shturval.tech/name: etcdbackup
finalizers:
- node.shturval.tech/finalizer
name: etcdbackup
spec:
packages:
- name: etcdhelper
state: present
files:
- content: |
#!/bin/sh
if [[ $EUID -ne 0 ]]; then
echo "This script must berun as root"
exit 1
fi
if which etcdctl > /dev/null; then
echo etcdctl found
else
echo etcdctl not found
fi
function usage {
echo 'Path to backup dir required: ./cluster-backup.sh <path-to-backup-dir>'
exit 1
}
# If the first argument is missing, or it is an existing file, then print usage and exit
if [ -z "$1" ] || [ -f "$1" ]; then
usage
fi
function checkManifests {
echo 'No manifsts found in /etc/kubernetes/manifests'
exit 1
}
if [ -z "$(ls /etc/kubernetes/manifests/)" ];then
checkManifests
fi
function checkStatus () {
status=$?
if test $status -eq 0
then
echo "passed $1"
else
echo "failed $1"
exit 1
fi
}
archive="$(hostname)-$(date '+%F_%H%M%S').tar.gz"
backupdate="$1/backup/"
mkdir -p $backupdate/manifests
mkdir -p $backupdate/etcd
ETCDCTL_API=3 \
ETCDCTL_CACERT='/etc/kubernetes/pki/etcd/ca.crt' \
ETCDCTL_CERT='/etc/kubernetes/pki/etcd/server.crt' \
ETCDCTL_KEY='/etc/kubernetes/pki/etcd/server.key' \
ETCDCTL_ENDPOINTS='https://XX.XX.XX.XX:2379' \
/usr/local/bin/etcdctl snapshot save $backupdate/etcd/etcd.snapshot ;
checkStatus "etcd backup"
cp -r /etc/kubernetes/manifests/* $backupdate/manifests/
checkStatus "Create copies of static manifests"
echo "Manifests saved at $backupdate/manifests"
cp /etc/kubernetes/secrets_encryption.yaml $backupdate/etcd/ >/dev/null 2>&1
echo "Create copies of secrets_encryption.yaml"
echo "Archiving backup...."
tar -zcf $1/$archive $backupdate 2> /dev/null
checkStatus "archiving file"
echo "Backup archiving finished"
chmod 666 $1/$archive
echo "Backup archive is located in $1/archive"
find /tmp/ -name "*.tar.gz" -mtime +3 -delete
checkStatus "removing old backups"
echo Backup finished
exit 0
group: root
mode: "0755"
owner: root
path: /opt/etcdbackup.sh
type: file
- content: "30 18 * * * /opt/etcdbackup.sh /tmp/"
group: root
mode: "0600"
owner: root
path: /var/spool/cron/root
type: file
nodeconfigselector:
node-role.kubernetes.io/control-plane: ""
priority: 100
В результате успешного выполнения скрипта по расписанию для каждого Master-узла будет создана резервная копия ETCD.
Восстановить резервную копию ETCD
Чтобы восстановить из резервной копии ETCD, для каждого Master-узла необходимо выполнить restore.
- На Master-узле переместите манифест пода с менем файла
kube-apiserver.yamlизetc/kubernetes/manifests/в другую папку, например,/root, чтобы остановить работу API-сервера. После перемещения необходимо дождаться удаления пода.
Команда
# Перемещение пода в папку /root/
mv /etc/kubernetes/manifests/kube-apiserver.yaml /root/
# Получение информации о поде API-сервера
crictl ps | grep api
Скриншот

- Выполните восстановление из резервной копии ETCD.
Команда
export ETCDCTL_API=3
/usr/local/bin/etcdctl --data-dir /var/lib/etcd snapshot restore /tmp/backup/etcd/etcd.snapshot
Где вместо /var/lib/etcd укажите каталог, который будет создан в процессе восстановления резервной копии ETCD, а вместо /tmp/backup/etcd/etcd.snapshot путь до резервной копии. Обратите внимание! Если вы указываете каталог /var/lib/etcd, удалите его до выполнения восстановления из резервной копии ETCD.
Скриншот

Обратите внимание! В случае восстановления ETCD на Master-узлах нового созданного кластера, необходимо восстановить secrets_encryption.yaml из архива. Сохранение secrets_encryption.yaml требуется для кластеров с расширенными параметрами безопасности (secure=true).
Команда
cp status/backup/etcd/secrets_encryption.yaml /etc/kubernetes/
Где вместо status/backup/etcd/secrets_encryption.yaml укажите путь, до сохраненного файла secrets_encryption.yaml.
- Перезапустите под API-сервера, переместив файл
kube-apiserver.yamlобратно вetc/kubernetes/manifests/на узле.
Команда
mv /root/kube-apiserver.yaml /etc/kubernetes/manifests/
# Получение информации о поде API-сервера
crictl ps | grep api
Скриншот

Рекомендуется:
- Перезапустить
kube-scheduler,kube-controller-managerна Master-узлах. Поочередно переместите файлы с манифестами в папку root. Проверьте, что под удален, после чего верните манифест обратно в/etc/kubernetes/manifests/.
Команда перезапуска kube-scheduler
# Перемещение пода в папку /root/
mv /etc/kubernetes/manifests/kube-scheduler.yaml /root/
# Получение информации о поде kube-scheduler. Дождитесь удаления пода
crictl ps | grep scheduler
# Возвращение пода kube-scheduler
mv /root/kube-scheduler.yaml /etc/kubernetes/manifests/
Команда перезапуска kube-controller-manager
# Перемещение пода в папку /root/
mv /etc/kubernetes/manifests/kube-controller-manager.yaml /root/
# Получение информации о поде kube-controller-manager. Дождитесь удаления пода
crictl ps | grep controller
# Возвращение пода kube-controller-manager
mv /root/kube-controller-manager.yaml /etc/kubernetes/manifests/
- Перезапустить
kubelet.
Команда перезапуска kubelet
sudo systemctl restart kubelet
sudo systemctl status kubelet
Восстановление работы кластера ETCD с помощью etcd-helper
Восстановить работу кластера ETCD с помощью модуля etcd-helper возможно только в высокодоступном кластере (HA).
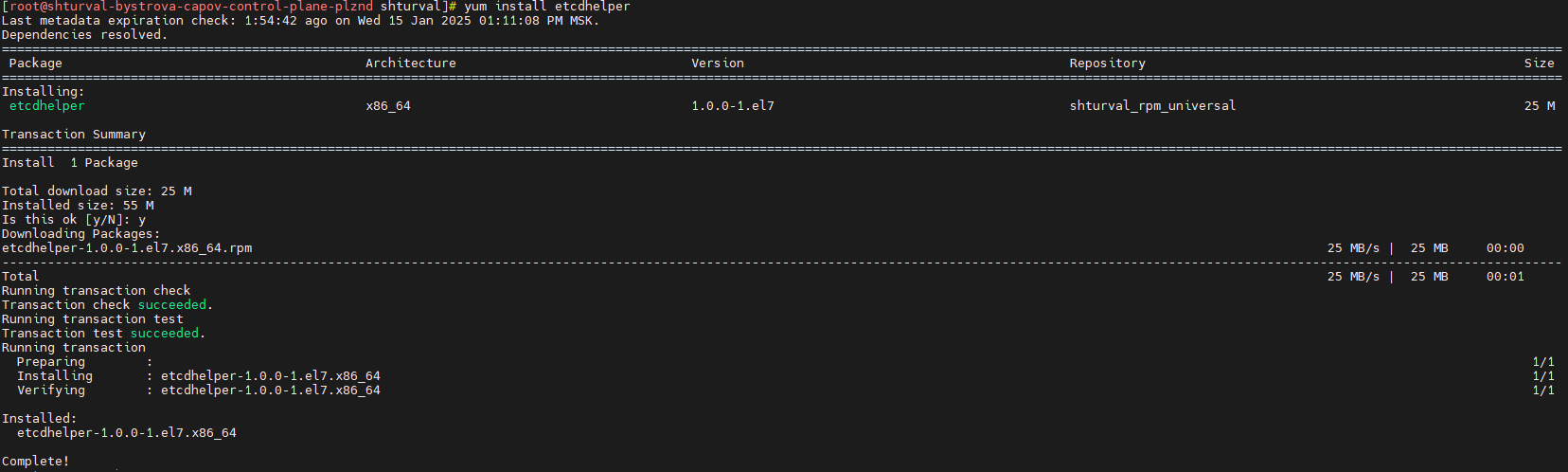
- Установите пакет с модулем
etcd-helper, содержащий утилитыedtcdctl,etcdutl,etcdhelper.
Команда
yum install etcdhelper
Модуль etcd-helper будет загружен в /usr/local/bin.
Скриншот
- Чтобы выполнить запрос к кластеру ETCD, запустите
etcdctlс необходимыми параметрами, с помощью командыetcdhelper exec. Требуемые параметры будут получены из/etc/kubernetes/manifests/etcd.yaml.
Команда
/usr/local/bin/etcdhelper exec -- member list -w table
Где параметр -- необходим для корректной передачи ключей в скрипте.
Скриншот

Восстановление недоступного узла кластера ETCD
Если IP-адрес и имя API-сервера не изменились, но на Master-узле повреждены данные, пересоздайте узел в кластере ETCD, выполнив команду etcdhelper rejoin.
Команда
/usr/local/bin/etcdhelper rejoin
Скриншот

Обратите внимание! Если контейнер ETCD на узле в статусе Running, то команда etcdhelper rejoin не может быть выполнена.
В результате выполнения команды произойдет:
- Удаление нерабочего узла из кластера ETCD.
- Остановка kubelet.
- Удаление контейнера ETCD.
- Переименование каталога с данными ETCD.
- Добавление нового узла в кластер ETCD.
- Запуск kubelet.
Восстановление при изменении IP-адреса Master-узла
Если IP-адрес одного из Master-узлов изменен, то восстановите работу кластера ETCD, использовав команду etcdhelper ip.
Команда
/usr/local/bin/etcdhelper ip --nodeip=10.11.16.11
Где вместо 10.11.16.11 укажите новый IP-адрес узла.
Скриншот
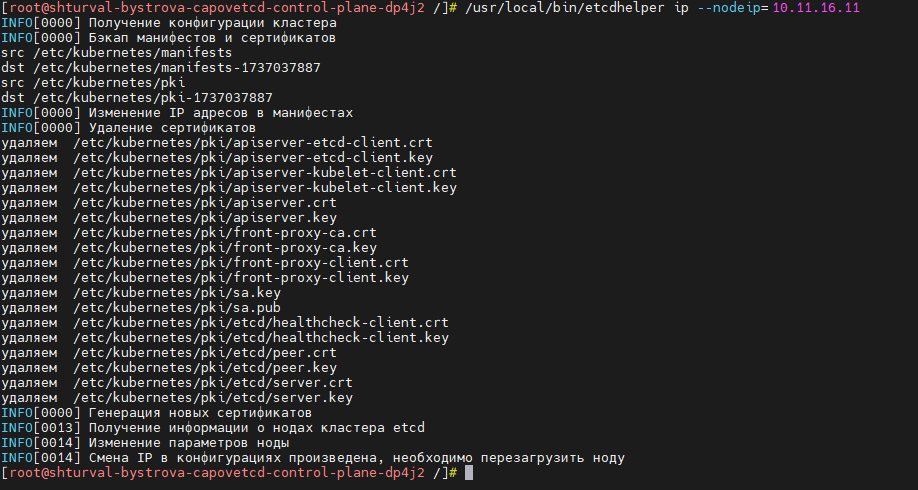
В результате команды будет выполнено:
- Резервное копирование манифестов и сертификатов.
- Изменен IP-адрес узла в манифестах.
- Удалены сертификаты ETCD, за исключением сертификата CA.
- Сгенерированы сертификаты, в том числе для API-сервера.
- Изменен IP-адрес узла в кластере ETCD.
Восстановление при изменении IP-адресов всех Master-узлов
Для восстановления работоспособности кластера etcd выполните последовательно действия:
- На первом Master-узле выполните команду для подготовки конфигурации после смены IP:
Команда
etcdhelper prepare --nodeip=НОВЫЙ IP адрес
-
Добавьте опцию
--force-new-clusterв манифест/etc/kubernetes/manifests/etcd.yaml. -
Перезагрузите первый узел.
-
Отредактируйте запись об узле в кластере etcd.
Пример команд
# Посмотреть ID узла
/usr/local/bin/etcdhelper exec -- member list -w table
# Обновить запись об узле
/usr/local/bin/etcdhelper exec -- member update ВВЕДИТЕ-ID-УЗЛА --peer-urls=https://ВВЕДИТЕ-НОВЫЙ-IP-АДРЕС-УЗЛА:2380
-
Удалите опцию
--force-new-clusterиз манифеста/etc/kubernetes/manifests/etcd.yaml. -
Перезагрузите первый узел.
-
Убедитесь, что кластер kubernetes работает.
-
При восстановлении кластера управления убедитесь, что все поды в неймспейсе
shturval-backendзапущены. Еслиshturval-backend-redisилиshturval-backend-valkeyне запущены, выполните принудительное удаление для перезапуска. -
При восстановлении кластера (клиентского, управления) с провайдером Shturval v2, подготовьте новые хосты и добавьте их в экземпляр провайдера.
-
В графическом интерфейсе кластера откройте раздел Администрирование и перейдите на страницу Управление узлами, нажмите на Конфигурация группы Control Plane. На вкладке Конфигурация ClusterAPI установите 1 в поле Запрошено реплик.
Примеры команд для применения в интерфейсе командной строки
# Изменить количество реплик в KubeadmControlPlane
kubectl edit KubeadmControlPlane -n ИМЯ-КЛАСТЕРА ИМЯ-КЛАСТЕРА-control-plane
В spec KubeadmControlPlane установите значение 1 для параметра `replicas.
- Вернитесь на страницу Управление узлами и скопируйте имена узлов в статусе
NotReady.
Пример команды для применения в интерфейсе командной строки
# Получить имена узлов кластера
kubectl get node
- Получите список Machines и удалите Machines, соответствующие Master-узлам в статусе
NotReady.
Примеры команд
# Получить все Machines кластера
kubectl get machines -n ИМЯ-КЛАСТЕРА
# Удалить поочередно Machines, соответствующие Master-узлам в статусе `NotReady`
kubectl delete machines -n ИМЯ-КЛАСТЕРА ИМЯ-MACHINE
Удаление занимает некоторое время. В результате будут удалены Machines, узлы и ВМ, если кластер развернут с провайдером отличным от Shturval v2.
Обратите внимание! В случае длительного удаления, например, более 15 минут, вы можете удалить Machines ручным способом:
- Отредактируйте удаляемый ресурс Machine, удалив finalizer.
- Удалите узел из кластера и ВМ в платформе виртуализации.
- Когда удалены все Machines, в графическом интерфейсе кластера откройте раздел Администрирование и перейдите на страницу Управление узлами, нажмите на Конфигурация группы Control Plane. На вкладке Конфигурация ClusterAPI установите 3 в поле Запрошено реплик.
Примеры команд для применения в интерфейсе командной строки
# Изменить количество реплик в KubeadmControlPlane
kubectl edit KubeadmControlPlane -n ИМЯ-КЛАСТЕРА ИМЯ-КЛАСТЕРА-control-plane
В spec KubeadmControlPlane установите значение 3 для параметра `replicas.