Анализ состояния в платформе Штурвал
Для осуществления непрерывного анализа состояния работы компонентов и приложений в составе платформы поставляются:
- модуль локального сбора логов;
- модуль централизованного хранения логов;
- модуль графического отображения логов;
- модуль локального сбора метрик;
- внешний модуль графического отображения метрик.
Мониторинг
Для сбора метрик в составе платформы поставляется Prometheus. Он входит в состав рекомендуемых системных сервисов при инсталляции клиентского кластера. Prometheus по умолчанию собирает метрики системных компонентов и перенаправляет их в кластер Victoria Metrics, размещенный в кластере управления.
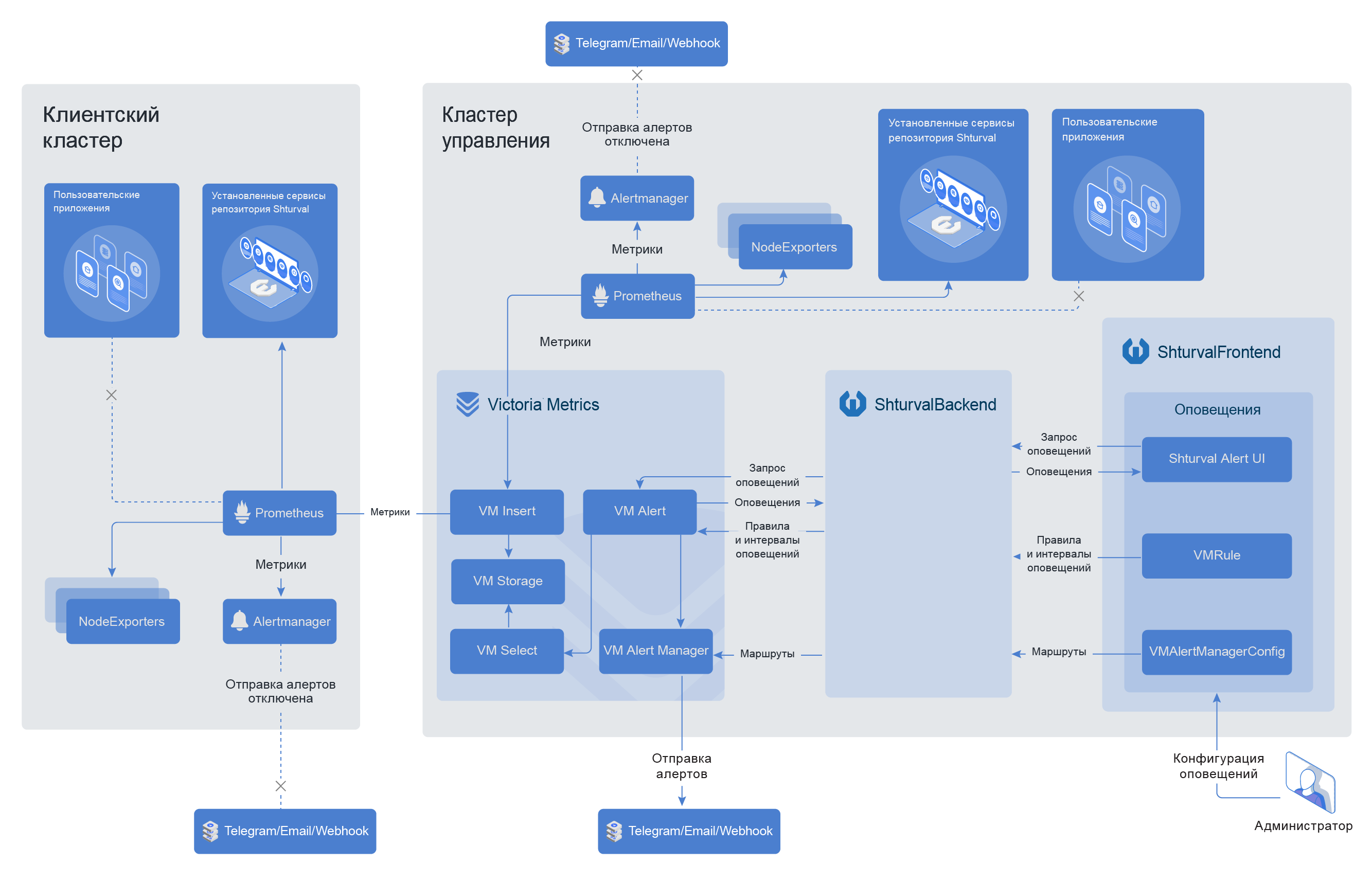
Собранные метрики доступны для просмотра в предварительно настроенных дашбордах Grafana .
Описание доступных дашбордов Grafana
Overview
- Global CPU Usage, CPU Usage
- Global RAM Usage, RAM Usage
- Количество узлов
- Количество неймспейсов
- Количество запущенных подов
- Количество ресурсов Kubernetes
Resources
- Cluster CPU Utilization
- CPU Utilization by namespace
- CPU Utilization by node
- CPU Throttled seconds by namespace
- CPU Core Throttled by node
- Cluster Memory Utilization
- Memory Utilization by namespace
- Memory Utilization by node
Kubernetes
- Kubernetes Pods QoS classes
- Kubernetes Pods Status Reason
- OOM Events by namespace
- Container Restarts by namespace
Network
- Global Network Utilization by device
- Network Saturation - Packets dropped
- Network Received by namespace
- Total Network Received (with all virtual devices) by node
- Network Received (without loopback) by node
- Network Received (loopback only) by node
Есть возможность дополнительной настройки конфигурации установленных сервисов, перенаправления метрик из Prometheus, а также замены сервисов на корпоративные.
Алертинг
На основе полученных метрик в кластере Victoria Metrics формируются алерты. Отчет об алертах доступен в интерфейсе клиентского кластера.
Для настройки правил оповещения и агрегации в составе платформы поставляется VM Alert Manager .
Дополнительно есть возможность настройки отправки алертов по различным каналам:
Логирование
Для сбора логов в клиентских кластерах и кластере управления поставляется Fluentbit . Ведется запись логов:
- аутентификации;
- backend;
- аудита;
- всех системных компонентов;
- приложений пользовательской нагрузки.

Собранные логи маршрутизируются в кластер управления в модуль централизованного хранения логов - OpenSearch. Есть возможность настроить перенаправление логов до или после доставки в OpenSearch .
В случае потери доступности кластера управления буфер хранения логов по умолчанию = 100 МБ для каждого узла.
Переход в OpenSearch доступен из дашборда клиентского кластера и кластера управления. Переход осуществляется по SSO с сохранением прав доступа пользователей.
По умолчанию в OpenSearch будут созданы индексы для кластера и Kube-Audit логов, а также настроена политика ротации логов .