Модуль графического отображения метрик (Grafana)
Внешний модуль мониторинга (не поставляется в составе Платформы) обеспечивает сбор и отображение:
- системных метрик узлов кластера;
- метрик системных компонентов кластера;
- метрик контейнеров.
Вся информация отображается на информационных панелях (Dashboards). Для интерактивной визуализации, мониторинга и анализа данных используется платформа Grafana.
Для настройки модуля графического отображения метрик в графическом интерфейса кластера в боковом меню откройте раздел Сервисы и репозитории и перейдите на страницу Установленные сервисы, нажмите Управлять.
Если модуль не отображается, в боковом меню откройте раздел Сервисы и репозитории и перейдите на страницу Доступные чарты, найдите чарт “shturval-dashboards” и нажмите “Установить”. Модуль на основе Grafana Dashboards предоставляет возможность визуализации и анализа данных, используемых для мониторинга.
Для изменения конфигурации сервиса в блоке Спецификация сервиса пропишите необходимые параметры.
Пример customvalues
adminPassword: <ваше значение параметра>
adminUser: <ваше значение параметра>
grafana.ini:
auth.generic_oauth:
api_url: <ваше значение параметра>
auth_url: <ваше значение параметра>
client_id: grafana
client_secret: <ваше значение параметра>
token_url: <ваше значение параметра>
server:
root_url: <ваше значение параметра>
ingress:
enabled: true
hosts:
- <ваше значение параметра>
| Параметр | Описание | Тип данных | Пример |
|---|---|---|---|
adminPassword |
Пароль учетной записи для подключения к Grafana | string | password |
adminUser |
Имя пользователя учетной записи для подключения к Grafana | string | admin |
auth.generic_oauth.api_url |
URL для получения информации о пользователе провайдера OAuth2 | string | http://auth.admin-manual.shturval.tech/oauth/user_info |
auth.generic_oauth.auth_url |
URL авторизации провайдера OAuth2 | string | http://auth.admin-manual.shturval.tech/oauth/authorize |
auth.generic_oauth.client_secret |
Ключ секрета клиента, предоставленный провайдером OAuth2 | string | HG0rxJMKopmAGSasDxDtkJYQH |
auth.generic_oauth.token_url |
URL для получения токена доступа OAuth2 | string | http://auth.admin-manual.shturval.tech/oauth/token |
server.root_url |
URL доступа к Grafana из веб-браузера | string | dashboards.admin-manual.shturval.tech |
ingress.hosts |
Список хостов Ingress | array | dashboards.admin-manual.shturval.tech |
Интерфейс Grafana
Интерфейс Grafana доступен по префиксу dashboards в домене кластера. Например: dashboards.apps.ip-XX-XX-XX-XX.shturval.link.
Данные для входа генерируются при разворачивании кластера и их можно посмотреть в Secret shturval-dashboards в неймспейсе monitoring кластера управления.
Команды
$ kubectl -n monitoring get secret shturval-dashboards -o go-template='{{ index .data "admin-user" | base64decode }}'
admin
$ kubectl -n monitoring get secret shturval-dashboards -o go-template='{{ index .data "admin-password" | base64decode }}'
admin
При выборе пункта меню Browse открывается перечень всех метрик. По клику на названии метрики открываются информационные панели с данными, которые изменяются в режиме реального времени.
Некоторые информационные блоки снабжены подсказками. Они отображаются при наведении курсора к значку i
Для просмотра дашборда мониторинга на странице Дашборд кластера нажмите на кнопку Посмотреть статистику. После перехода для авторизации в системе нажмите Sign in with shturval authn.
С дополнительной информацией можно ознакомиться на официальном сайте. В текущем релизе используется Grafana версии 11.4.1.
При переходе из платформы “Штурвал” к дашбордам Grafana может возникнуть ошибка 401. Такое поведение связано с особенностью работы Grafana с token. Чтобы получить доступ к дашбордам, перезайдите повторно в интерфейс Grafana.
Описание доступных дашбордов Grafana
Обратите внимание! Если вам необходимо добавить кастомный дашборд в интерфейс Grafana, воспользуйтесь инструкцией.
Services
Alertmanager/Общая информация
Описание
Данный дашборд предназначен для мониторинга состояния Alertmanager, обеспечивая визуализацию данных о полученных и отправленных уведомлениях. Основные возможности дашборда включают отображение общего количества уведомлений, интенсивности их получения и отправки, а также метрики задержки обработки уведомлений. Пользователи могут фильтровать данные по неймспейсу, сервисам и интеграциям для глубокого анализа.
Скриншот
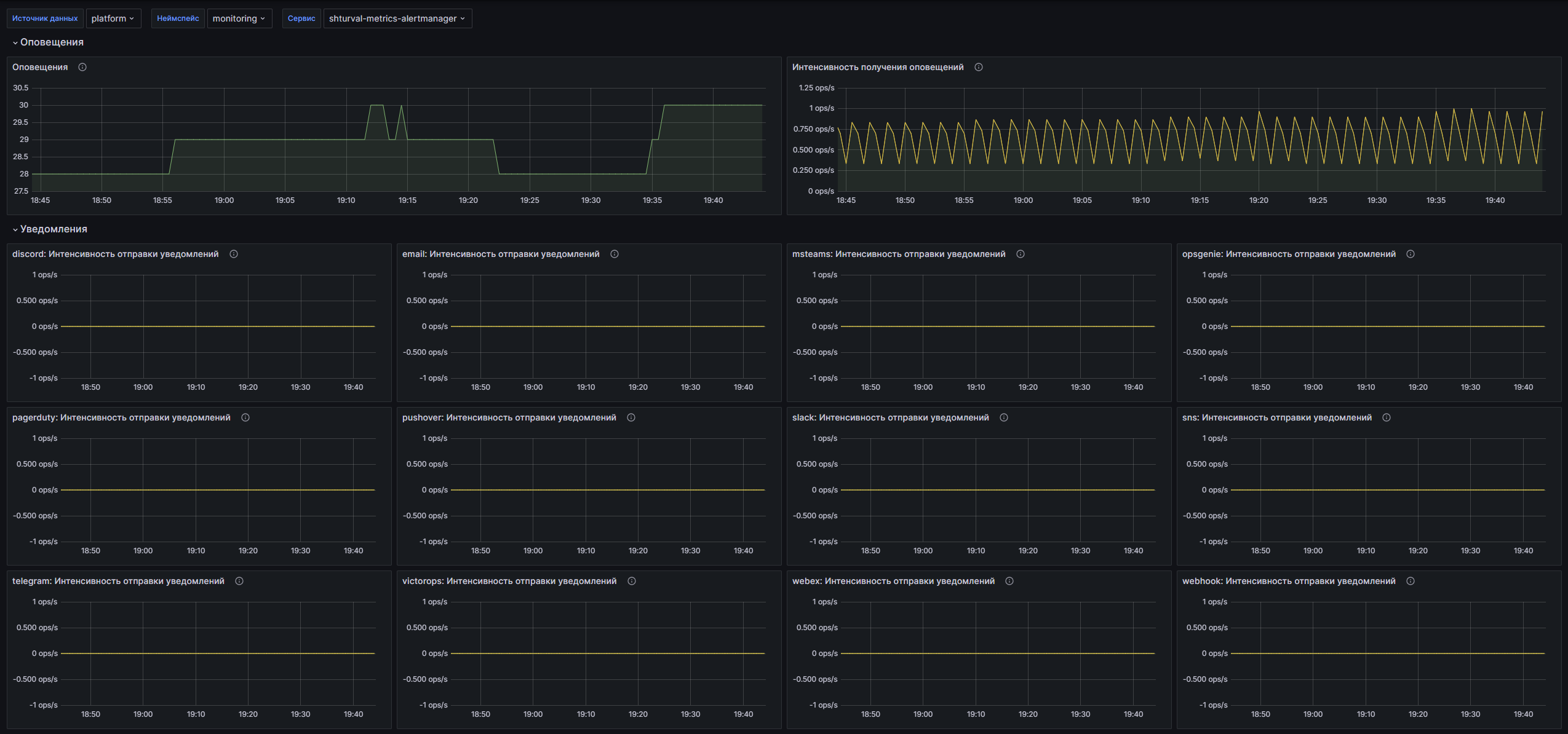
Структура дашборда
-
Оповещения
- Оповещения: Общее количество оповещений, полученных Alertmanager.
- Интенсивность получения оповещений: Метрики, показывающие количество успешно полученных и недействительных уведомлений.
-
Уведомления
- $integration: Интенсивность отправки уведомлений: Интенсивность отправки уведомлений, включая успешные и неудачные отправки, для выбранной интеграции.
- $integration: Длительность уведомлений: Метрики задержки отправки уведомлений, отображающие 99-й процентиль, медиану и среднее время отправки уведомлений.
Настраиваемые параметры
- datasource: Обеспечивает выбор источника данных для отображения на дашборде.
- namespace: Позволяет фильтровать метрики по неймспейсу, отображая только данные для выбранного неймспейса.
- service: Позволяет пользователю выбрать конкретный сервис для анализа метрик уведомлений.
- integration: Предоставляет возможность выбора интеграции для анализа интенсивности отправки уведомлений и задержек.
Certificates Expiration
Описание
Данный дашборд предназначен для мониторинга состояния сертификатов, предоставляя обширную информацию о сроках их действия. Включает в себя данные по Kubernetes Secrets, сертификатам на узлах, а также на любых серверах. Основные возможности дашборда позволяют пользователю быстро оценить количество сертификатов, выявить просроченные и те, срок действия которых истекает в ближайшее время, а также проанализировать ошибки загрузчиков сертификатов.
Скриншот
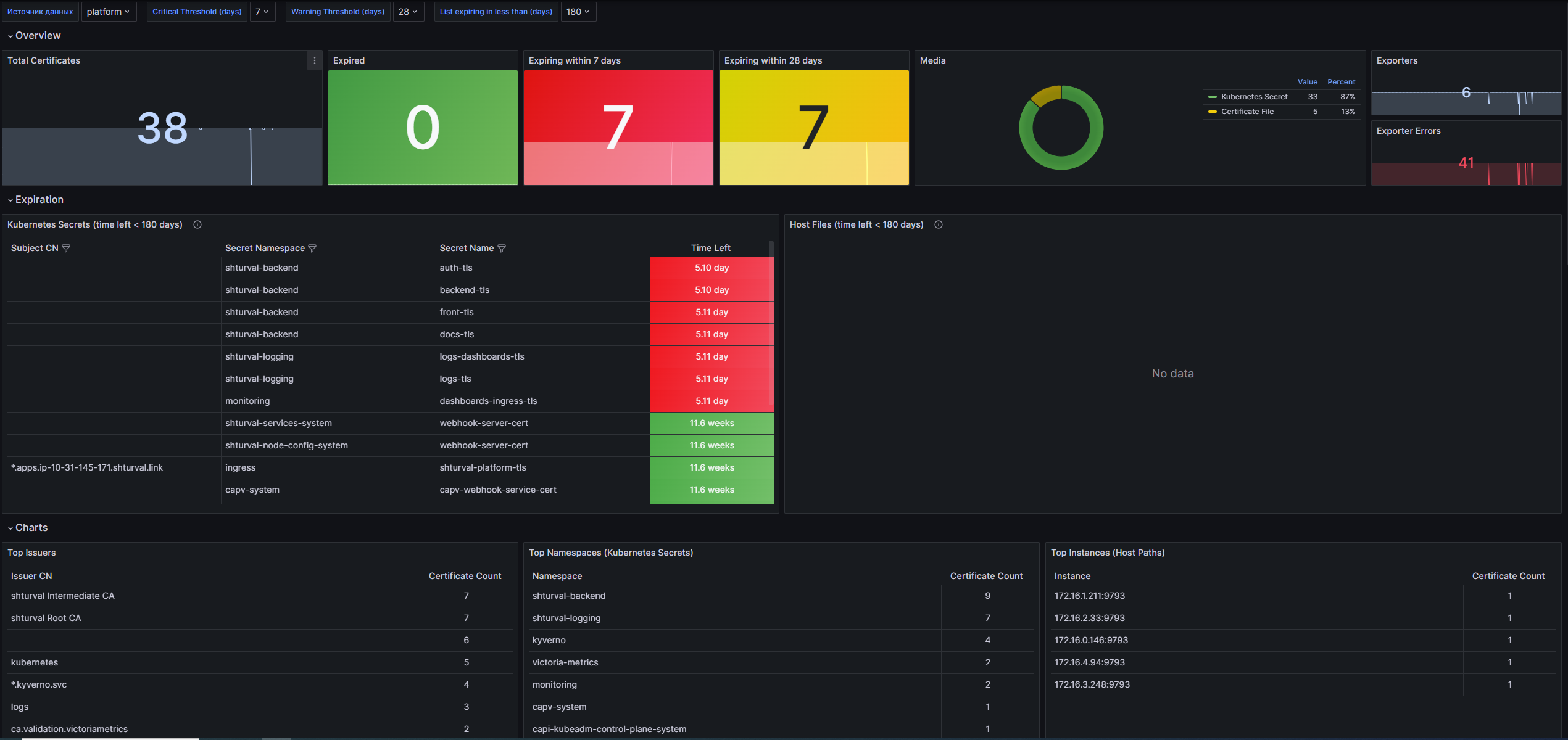
Структура дашборда
-
Overview
- Total Certificates: Отображает общее количество сертификатов, подсчитываемое на основе метрики
x509_cert_not_after. - Expired: Показывает количество сертификатов, срок действия которых истек.
- Expiring within $critical_threshold days: Отображает число сертификатов, срок действия которых истекает в течение критического порога, заданного пользователем.
- Expiring within $warning_threshold days: Показывает число сертификатов, срок действия которых истекает в пределах порога предупреждения.
- Media: Пироговая диаграмма, показывающая распределение сертификатов по типам: Kubernetes Secret, Kubeconfig Embedded и Certificate File.
- Exporters: Показывает общее количество ошибок загрузчиков сертификатов.
- Exporter Errors: Отображает сумму ошибок загрузчиков сертификатов.
- Total Certificates: Отображает общее количество сертификатов, подсчитываемое на основе метрики
-
Expiration
- Kubernetes Secrets (time left < $list_threshold days): Таблица, отображающая Kubernetes Secrets, срок действия которых истекает меньше чем за заданное количество дней. Обратите внимание, что для окраски столбца Time Left необходимо вручную настраивать пороги в параметрах переопределения этого виджета.
- Host Files (time left < $list_threshold days): Таблица, аналогичная предыдущей, но для сертификатов файлохранителей.
-
Charts
- Top Issuers: Таблица, показывающая 10 наиболее распространённых удостоверяющих компаний (issuer) на основании количества сертификатов.
- Top Namespaces (Kubernetes Secrets): Таблица, отображающая 10 неймспейсов, в которых находятся Kubernetes Secrets, с наибольшим количеством сертификатов.
- Top Instances (Host Paths): Таблица, показывающая 10 экземпляров (instance) с наибольшим количеством сертификатов файлового хранилища.
- Kubernetes Secrets : Shortest Validity Period: Таблица, отображающая 10 Kubernetes Secrets с наименьшим оставшимся сроком действия.
- Host Paths : Shortest Validity Period: Таблица, показывающая 10 файловых пути с наименьшим оставшимся сроком действия.
- Kubernetes Secrets : Longest Validity Period: Таблица, отображающая 10 Kubernetes Secrets с наибольшим сроком действия.
- Host Paths : Longest Validity Period: Таблица, показывающая 10 файловых пути с наибольшим сроком действия.
-
Exporters
- Reporting Exporters: График, показывающий количество ошибок загрузчиков.
- Exporters with Errors: График, отображающий количество загрузчиков с ошибками.
- Error Rate: График, показывающий частоту ошибок в загрузчиках за последние 15 минут.
- Cumulative Errors: График, показывающий общее количество ошибок на сегодняшний день.
- Top Exporters by Error Rate: Таблица с 10 загрузчиками с наивысшим уровнем ошибок.
- Top Exporters by Cumulative Errors: Таблица, показывающая 10 загрузчиков с наибольшим числом накопленных ошибок.
Настраиваемые параметры
- datasource: Исходник данных для дашборда, позволяющий выбрать источник данных Prometheus.
- critical_threshold: Критический порог (в днях), определяющий, когда сертификаты должны быть отмечены как требующие внимания.
- warning_threshold: Порог предупреждения (в днях), устанавливающий временные рамки для раннего оповещения о сертификатах.
- list_threshold: Параметр, определяющий список сертификатов, срок действия которых истекает менее чем через заданное количество дней.
Cilium Agent
Описание
Данный дашборд предназначен для мониторинга метрик агента Cilium версии 1.12. Он предоставляет возможность отслеживать различные показатели производительности, такие как использование ресурсов, задержки API, управление политикам и сетевую активность в кластере Kubernetes. Набор панелей позволяет администраторам приложения быстро идентифицировать проблемы и оптимизировать работу сетевых компонентов приложения.
Скриншот
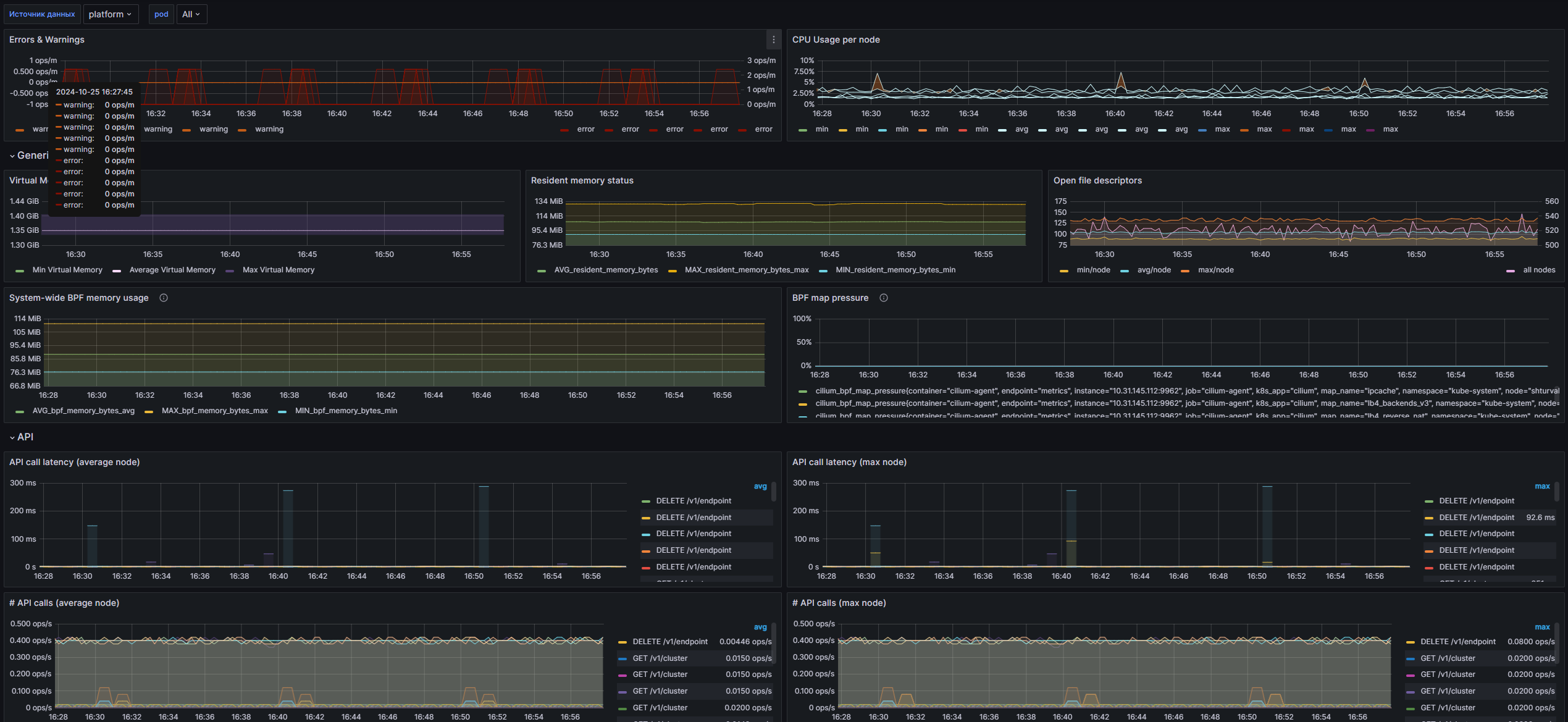
Структура дашборда
-
Errors & Warnings
- Errors & Warnings: Отображает количество ошибок и предупреждений, возникших в кластере Cilium, с разбивкой по уровням.
-
CPU Usage per node
- CPU Usage per node: Отображает использование CPU на каждом узле, включая минимальные, средние и максимальные значения.
-
Virtual Memory Bytes
- Virtual Memory Bytes: Показатели виртуальной памяти, включая минимальные, средние и максимальные значения для каждого пода.
-
Resident memory status
- Resident memory status: Статус резидентной памяти с минимальными, средними и максимальными значениями.
-
Open file descriptors
- Open file descriptors: Использование открытых дескрипторов файлов в кластере с минимальными, средними и максимальными значениями.
-
System-wide BPF memory usage
- System-wide BPF memory usage: Использование памяти BPF в системе, включая минимальные, средние и максимальные значения.
-
BPF map pressure
- BPF map pressure: Процент заполнения карт BPF, помеченных по имени карты.
-
API
- API call latency (average node): Среднее время ожидания вызовов API по каждому узлу.
- API call latency (max node): Максимальное время ожидания вызовов API по каждому узлу.
- # API calls (average node): Среднее количество вызовов API по каждому узлу.
- # API calls (max node): Максимальное количество вызовов API по каждому узлу.
- API return codes (average node): Среднее количество кодов возврата вызовов API по каждому узлу.
- API return codes (sum all nodes): Суммарное количество кодов возврата вызовов API по всем узлам.
-
BPF
- # system calls (average node): Среднее количество системных вызовов по каждому узлу.
- # system calls (max node): Максимальное количество системных вызовов по каждому узлу.
- system call latency (avg node): Средняя задержка системных вызовов по каждому узлу.
- system call latency (max node): Максимальная задержка системных вызовов по каждому узлу.
- map ops (average node): Средние операции с картами BPF по каждому узлу.
- map ops (max node): Максимальные операции с картами BPF по каждому узлу.
- map ops (sum failures): Суммарное количество операций с картами BPF, завершившихся неудачно.
-
kvstore
- # operations (sum all nodes): Суммарное количество операций с хранилищем по всем узлам.
- # operations (max node): Максимальное количество операций с хранилищем по каждому узлу.
- latency (average node): Средняя задержка операций с хранилищем по каждому узлу.
- latency (max node): Максимальная задержка операций с хранилищем по каждому узлу.
- Events received (average node): Среднее количество полученных событий по каждому узлу.
-
Cilium network information
- Forwarded Packets: Отображает количество пересланных пакетов по направлениям.
- Forwarded Traffic: Отображает объем пересланного трафика по направлениям.
- IPv4 Conntrack TCP: Статистика TCP соединений для IPv4.
- IPv6 Conntrack TCP: Статистика TCP соединений для IPv6.
- IPv4 Conntrack Non-TCP: Статистика не-TCP соединений для IPv4.
- IPv6 Conntrack Non-TCP: Статистика не-TCP соединений для IPv6.
- Allocated Addresses: Отображает количество выделенных IP-адресов.
- Datapath Conntrack Dump Resets: Статистика сбросов похищения контракта.
- Service Updates: Частота обновлений сервисов со средними значениями по действиям.
- Connectivity Health: Статус доступности узлов и конечных точек здоровья.
- Dropped Egress Packets: Количество сброшенных пакетов маршрутизации.
- Node Events: Количество событий на узлах со средними значениями по типам событий.
- Dropped Egress Traffic: Объем сброшенного исходящего трафика.
- Nodes: Количество узлов в кластере с минимальными, средними и максимальными значениями.
-
Policy
- L7 forwarded request: Количество пересланных, полученных и отклоненных запросов на уровне L7.
- Cilium drops Ingress: Количество сброшенных входящих пакетов с разбивкой по причинам.
-
Endpoints
- Endpoint regeneration time (90th percentile): Время регенерации конечных точек (90-й процентиль).
- Endpoint regeneration time (99th percentile): Время регенерации конечных точек (99-й процентиль).
- Endpoint regenerations: Общее количество регенераций конечных точек с разбивкой по итоговому результату.
- Cilium endpoint state: Статус конечных точек в кластере с разбивкой по состояниям.
-
Controllers
- Controllers: Мониторинг выполнения контроллеров и число возникающих ошибок.
- Controller Durations: Средняя продолжительность выполнения контроллеров с разбивкой по статусам.
-
Kubernetes integration
- apiserver latency (average node): Средняя задержка API сервера для каждого узла.
- apiserver latency (max node): Максимальная задержка API сервера для каждого узла.
- apiserver #calls (sum all nodes): Общее количество вызовов API сервера для всех узлов.
- apiserver calls (sum all nodes): Общее количество вызовов API сервера по всем узлам.
- Valid, Unnecessary K8s Events Received: Количество валидных, но ненужных событий Kubernetes.
- Invalid, Unnecessary K8s Events Received: Количество недопустимых и ненужных событий Kubernetes.
- Valid, Necessary K8s Events Received: Количество валидных и необходимых событий Kubernetes.
- Invalid, Necessary K8s Events Received: Количество недопустимых, но необходимых событий Kubernetes.
- CiliumNetworkPolicy Events: Количество событий, связанных с политиками CiliumNetworkPolicy.
- NetworkPolicy Events: Количество событий, связанных с политиками NetworkPolicy.
- Pod Events: События, связанные с подами.
- Node Events: События, связанные с узлами.
- Service Events: События, связанные с сервисами.
- Endpoints Events: События, связанные с конечными точками.
- Namespace Events: События, связанные с неймспейсами.
Настраиваемые параметры
- datasource: Используемый источник данных, основанный на VM Agent.
- pod: Позволяет выбирать отдельные поды для мониторинга на дашборде.
Cilium Operator
Описание
Данный дашборд предназначен для мониторинга метрик оператора Cilium версии 1.12, который использует наблюдение за сетевыми взаимодействиями, управлением IP-адресами и производительностью. Он предоставляет информацию о таких метриках, как использование CPU, статус резидентной памяти, взаимодействия с API EC2 и создание интерфейсов, что позволяет администратору отслеживать здоровье и производительность системы в реальном времени.
Скриншот

Структура дашборда
-
CPU Usage per node Панель отображает использование CPU для каждого узла, представлено в процентах и включает минимальные, средние и максимальные значения метрик.
-
Resident memory status Панель показывает статус резидентной памяти для оператора, включая средние, максимальные и минимальные значения в байтах.
-
IP Addresses Панель отображает среднее количество IP-адресов по типу, обеспечивая информацию о распределении адресов.
-
EC2 API Interactions Панель визуализирует взаимодействия с EC2 API, отображая время отклика для различных операций и кодов ответов.
-
Number of nodes Панель показывает текущее количество узлов, управляемых оператором, с метриками по категориям.
-
Interfaces with addresses available Панель отображает количество интерфейсов, к которым доступны адреса, что помогает в управлении IP-адресами.
-
Metadata Resync Operations Панель отображает частоту операций синхронизации метаданных, подсчитывая количество операций за минуту.
-
EC2 client side rate limiting Панель показывает показатели ограничения на стороне клиента EC2, отображая среднее время реакции на операции.
-
Interface Creation Панель визуализирует операции создания интерфейсов, отображая среднее количество операций по статусу и идентификатору подсети.
Настраиваемые параметры
- datasource: Параметр, позволяющий выбрать источник данных для метрик. В данном случае используется VM Agent.
etcd
Описание
Данный дашборд предназначен для мониторинга и анализа состояния системы хранения данных etcd, используя возможности мониторинга, предоставляемые VM Agent и Grafana. Он предоставляет информацию о ключевых показателях работы etcd, таких как активные сессии, интенсивность запросов, сетевой трафик, использование памяти и состояние диска. Дашборд способствует выявлению проблем и оптимизации производительности системы хранения.
Скриншот

Структура дашборда
- Запущено
-
Запущено: Показывает общее количество запущенных экземпляров etcd с указанием кластера и неймспейса.
-
Интенсивность Удаленных вызовов процедур (RPC): Отображает скорость запросов и количество неудачных RPC.
-
Активные сессии RPC: Демонстрирует количество активных двунаправленных потоков для разных служб RPC, таких как Watch и Lease.
-
Размер базы данных: Предоставляет информацию о размере базы данных в байтах для каждого пода кластера.
-
Общее время синхронизации диска: Выводит данные о времени синхронизации записей WAL и данных на диске для каждого пода.
-
Объем используемой памяти: Показывает объем используемой резидентной памяти для каждого пода в кластере.
-
Клиентский трафик на входе: Измеряет объем трафика, получаемого от клиентов.
-
Клиентский трафик на выходе: Измеряет объем трафика, отправляемого клиентам.
-
Пиринговый трафик на входе: Отображает объем трафика, получаемого от других участников кластера.
-
Пиринговый трафик на выходе: Отображает объем трафика, отправляемого другим участникам кластера.
-
Raft заявки: Показывает количество изменений лидеров в кластере за день.
-
Всего выборов лидеров в день: Отображает общее количество выборов лидеров в день.
-
Время согласованного пиров: Предоставляет данные о времени обратного маршрута для пиров, отображая влияние сети на производительность кластера.
-
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных, используемый для получения метрик.
- cluster: Позволяет выбрать конкретный кластер etcd для мониторинга.
Kyverno
Описание
Дашборд Kyverno предназначен для мониторинга политики управления Kubernetes и обеспечивает визуализацию ключевых метрик, связанных с выполнением политик, их состоянием и эффективность работы. Пользователи могут отслеживать актуальные результаты выполнения политик, уровень успешности проверок, а также использование ресурсов (ЦПУ и памяти) как по запросам, так и по лимитам. Данный дашборд позволяет администраторам Kubernetes быстро идентифицировать проблемы с политиками и оптимизировать ресурсы кластера.
Скриншот
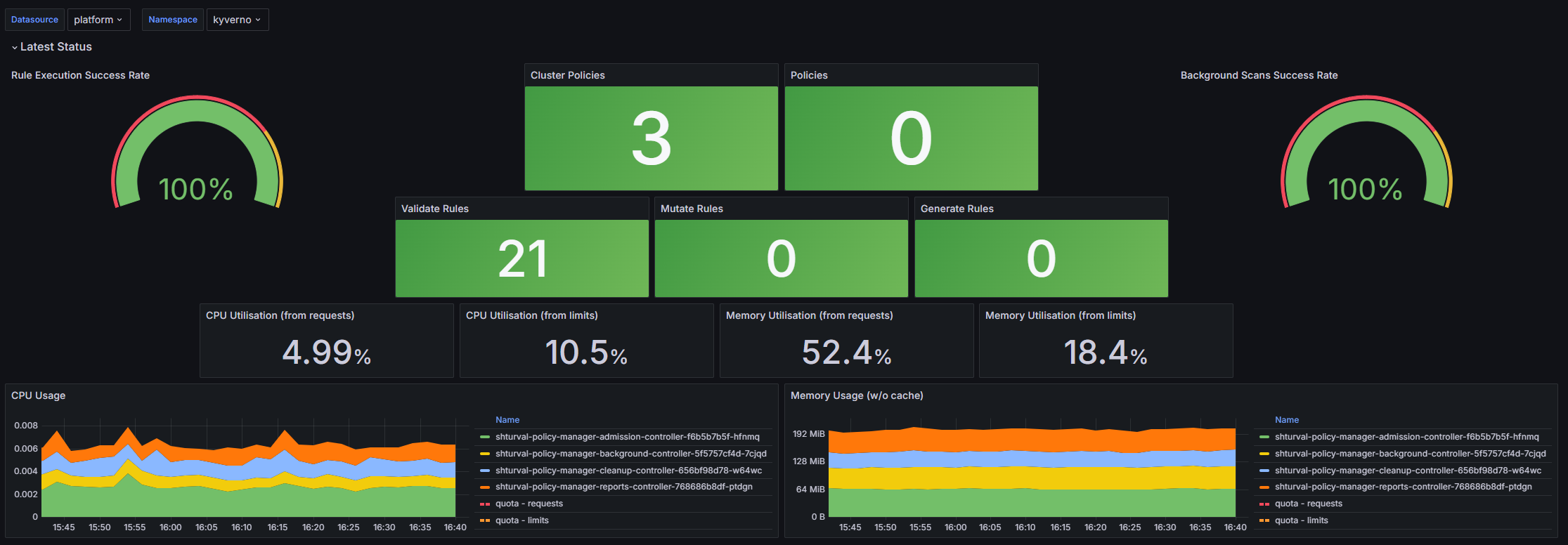
Структура дашборда
-
Latest Status
- Rule Execution Success Rate: Отображает процент успешного выполнения правил политик.
- Cluster Policies: Показывает количество активных кластерных политик.
- Policies: Показывает количество активных политик с неймспейсами.
- Background Scans Success Rate: Отображает уровень успешности фоновых проверок политик.
- Validate Rules: Информация о количестве правил верификации.
- Mutate Rules: Информация о количестве правил изменения.
- Generate Rules: Информация о количестве правил генерации.
- CPU Utilisation (from requests): Использование ЦПУ по запросам политик, в пределах заданного неймспейса.
- CPU Utilisation (from limits): Использование ЦПУ по лимитам политик, в пределах заданного неймспейса.
- Memory Utilisation (from requests): Использование памяти по запросам политик, в пределах заданного неймспейса.
- Memory Utilisation (from limits): Использование памяти по лимитам политик, в пределах заданного неймспейса.
- CPU Usage: Использование ЦПУ по подам, с учетом запросов и лимитов.
- Memory Usage (w/o cache): Использование памяти по подам без кэша.
-
Policy-Rule Results
- Admission Review Results (per-rule): Результаты проверки запросов на основе каждого правила.
- Background Scan Results (per-rule): Результаты фоновых проверок на основе каждого правила.
- Policy Failures: Количество сбоев политик, сгруппированных по типу.
- Admission Review Results (per-policy): Результаты проверки запросов на основе каждой политики.
- Background Scan Results (per-policy): Результаты фоновых проверок на основе каждой политики.
- Cluster Policies and Namespaces w/Failed: Информация о кластерных политиках и неймспейсах, где произошли сбои.
-
Policy-Rule Info
- Active Policies (by policy type): Количество активных политик, сгруппированных по типу.
- Active Policies (by policy validation action): Количество активных политик, сгруппированных по действию проверки.
- Active Policies running in background mode: Количество активных политик, работающих в фоновом режиме.
- Active Namespaced Policies (by namespaces): Количество активных пространственно-зависимых политик, сгруппированных по неймспейсу.
- Active Rules (by rule type): Количество активных правил, сгруппированных по типу.
-
Policy-Rule Execution Latency
- Average Rule Execution Latency: Средняя задержка выполнения правил.
- Average Policy Execution Latency: Средняя задержка выполнения политик.
- Overall Average Rule Execution Latency: Общее среднее значение задержки выполнения правил.
- Overall Average Policy Execution Latency: Общее среднее значение задержки выполнения политик.
-
Admission Review Latency
- Avg - Admission Review Duration (by operation): Средняя продолжительность проверки admission по операциям.
- Avg - Admission Review Duration (by resource kind): Средняя продолжительность проверки admission по видам ресурсов.
- Rate - Incoming Admission Requests (last 5m): Скорость входящих запросов на admission за последние 5 минут.
- Avg - Overall Admission Review Duration: Средняя продолжительность всех проверок admission.
-
Policy Changes
- Policy Changes (by change type): Изменения политик, сгруппированные по типу изменений.
- Policy Changes (by policy type): Изменения политик, сгруппированные по типу политики.
- Total Policy Changes: Общее количество изменений политик.
- Rate - Policy Changes Happening (last 5m): Скорость изменений политик за последние 5 минут.
-
Admission Requests
- Admission Requests (by operation): Количество запросов на admission по операциям.
- Admission Requests (by resource kind): Количество запросов на admission по видам ресурсов.
- Total Admission Requests: Общее количество запросов на admission.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для метрик, поддерживает выбор из нескольких источников.
- namespace: Позволяет фильтровать метрики по определенному неймспейсу в Kubernetes, используя значения метки
kube_namespace_status_phase.
Go Runtime Exporter
Описание
Данный дашборд предназначен для мониторинга параметров производительности приложений, написанных на языке Go. Он позволяет отслеживать использование памяти, количество объектов в памяти и характеристики сборщика мусора в реальном времени. Дашборд предлагает предварительно сконфигурированные графики и правила оповещения для быстрого анализа и диагностики работы приложений, что делает его полезным инструментом для разработчиков и администраторов.
Скриншот
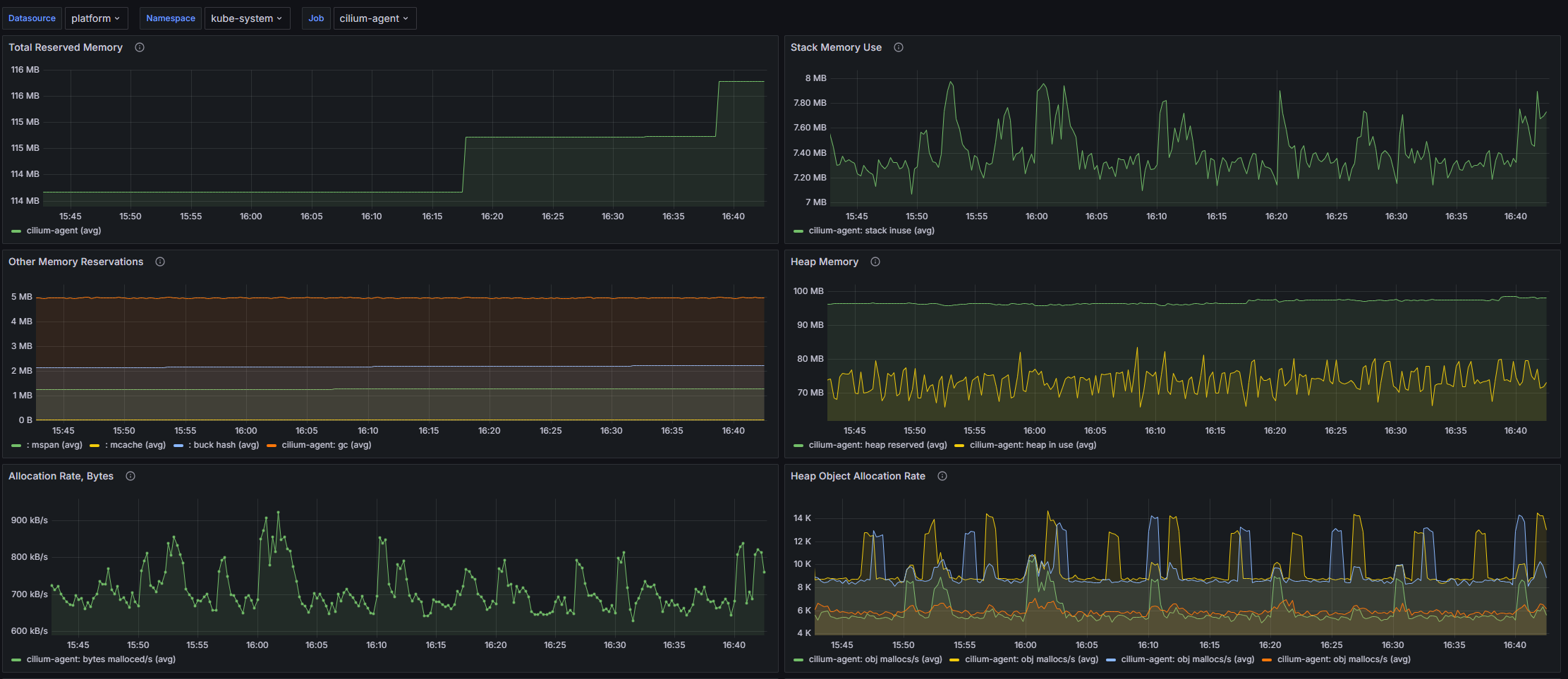
Структура дашборда
- Total Reserved Memory: Среднее значение общего объема зарезервированной памяти во всех неймспейсах приложения.
- Stack Memory Use: Среднее значение использования стековой памяти во всех неймспейсах приложения.
- Other Memory Reservations: Среднее значение резервирования памяти для других нужд, не включая стек и кучу, во всех неймспейсах приложения.
- Heap Memory: Средние значения, связанные с памятью кучи, включая зарезервированную, используемую и выделенную память.
- Allocation Rate, Bytes: Средняя скорость выделения памяти в байтах в секунду во всех неймспейсах приложения.
- Heap Object Allocation Rate: Средняя скорость выделения объектов в куче во всех неймспейсах приложения.
- Number of Live Objects: Среднее количество живых объектов в памяти во всех неймспейсах приложения.
- Goroutines: Среднее количество Go-рутин во всех неймспейсах приложения.
- GC min & max duration: Средняя минимальная и максимальная длительность сборки мусора (GC).
- Next GC, Bytes: Среднее количество байт, используемых до следующей сборки мусора.
Настраиваемые параметры
- datasource: Управляет выбором источника данных для использования в дашборде.
- namespace: Позволяет фильтровать графики по неймспейсу, отображая только данные, относящиеся к заданному неймспейсу.
- job: Позволяет выбирать конкретную задачу, по которой будут отображаться метрики, фильтруя результаты согласно выбранной задаче и неймспейсу.
Обзор Grafana
Описание
Данный дашборд предназначен для мониторинга и анализа данных, связанных с производительностью и работоспособностью системы Grafana. Он позволяет отслеживать метрики, такие как количество предупреждений, общее количество дашбордов, информацию о сборках, запросах к Grafana и их продолжительности. Этот дашборд является полезным инструментом для разработчиков и администраторов, который помогает в быстрой идентификации проблем в работе приложения и оптимизации производительности.
Скриншот
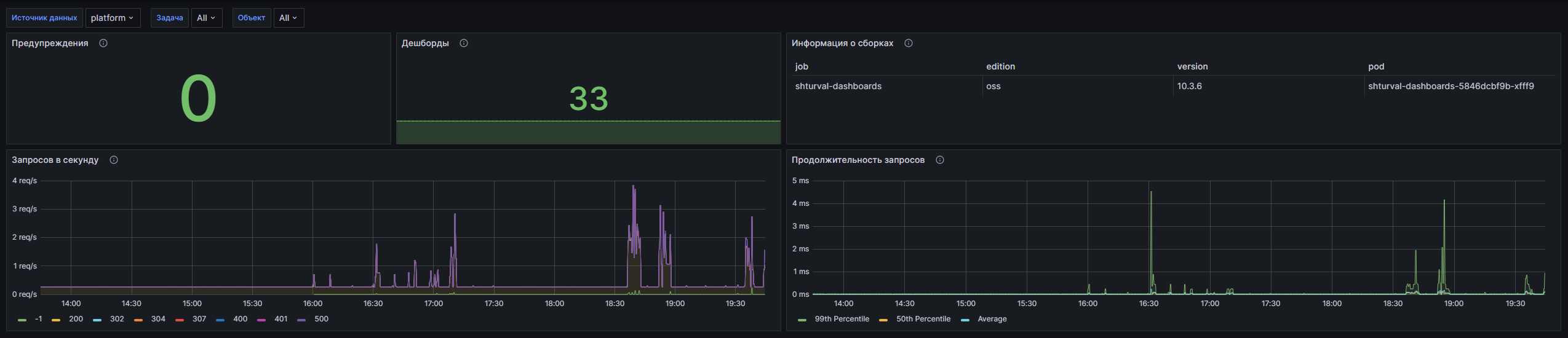
Структура дашборда
- Предупреждения
- Предупреждения: Суммарное количество всех предупреждений в системе в текущий момент.
- Дешборды: Суммарное количество дашбордов, доступных в системе.
- Информация о сборках: Сводная информация о сборках Grafana, включая ключевые метрики.
- Запросов в секунду: Суммарное количество запросов к Grafana в секунду, что помогает отслеживать нагрузку на систему в реальном времени.
- Продолжительность запросов: Метрики, показывающие процентильные значения (99-й и 50-й) продолжительности HTTP-запросов к Grafana, а также среднее время выполнения запросов.
Настраиваемые параметры
- datasource: Источник данных, который позволяет пользователям выбирать между различными источниками для отображения информации.
- job: Параметр, позволяющий фильтровать метрики по заданной задаче, что упрощает анализ данных, относящихся к конкретным задачам.
- pod: Параметр, который позволяет пользователям выбирать конкретный объект (pod) для более точного мониторинга и анализа данных.
CoreDNS
Описание
Данный дашборд предназначен для мониторинга DNS-сервера CoreDNS и отображает актуальные метрики для версии 1.7.0 и выше. Он основан на дашборде CoreDNS 1.7.0+, разработанном ejkinger. Пользователи могут отслеживать различные аспекты работы сервера, такие как количество запросов, время задержки ответов, распределение размеров запросов и статус здоровья подов.
Скриншот
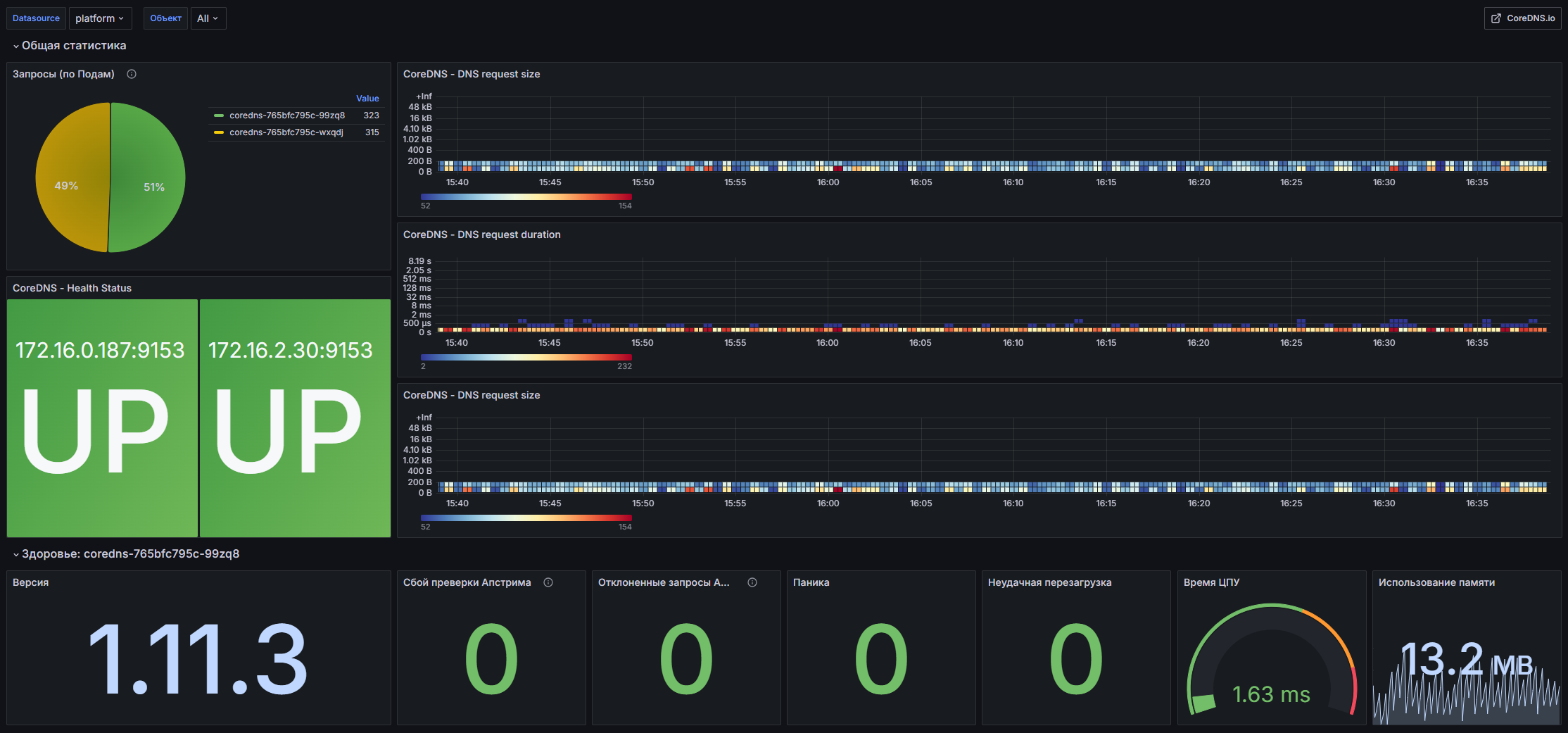
Структура дашборда
-
Общая статистика
- Запросы (по Подам): Суммарное число запросов к CoreDNS, представлено в виде круговой диаграммы.
- CoreDNS - DNS request size: Тепловая карта, отображающая размер DNS запросов.
- CoreDNS - DNS request duration: Тепловая карта, показывающая время обработки DNS запросов.
- CoreDNS - Health Status: Показатель состояния здоровья подов.
- CoreDNS - DNS request size: Повторяющаяся тепловая карта для анализа размера DNS запросов.
-
Здоровье: $pod
- Версия: Отображает информацию о версии CoreDNS, работающей на выбранном поде.
- Сбой проверки Апстрима: Статистическая панель, показывающая количество сбоев проверки состояния upstream.
- Отклоненные запросы Апстрима: Статистическая панель, отображающая количество отклоненных запросов к upstream.
- Паника: Показатель количества паник в CoreDNS.
- Неудаляемая перезагрузка: Статистическая панель для отслеживания количества неудачных перезагрузок.
- Время ЦПУ: Измеряет использование процессора в CoreDNS.
- Использование памяти: Показатель объема выделенной памяти для CoreDNS.
-
Локальные
- Запросы (всего): Временной ряд, отображающий общее количество запросов.
- Запросы (зоны): Временной ряд, показывающий запросы к DNS по зонам.
- Ответы (задержка, интернет зоны): Временной ряд с квантилями времени ответа на запросы.
- Запросы (типы): Временной ряд, отображающий распределение запросов по типам.
- Кеш (хитрейд): Зависимость частоты попадания в кэш запросов.
- Запросы (DNSSEC, зоны): Временной ряд, отображающий запросы с использованием DNSSEC.
-
Апстрим
- Запросы (всего): Временной ряд для запросов к upstream.
- Кеш (хитрейд): Показатель попаданий и промахов в кэше для запросов к upstream.
- Ответы (задержка): Временной ряд с квантилями времени ответа на запросы к upstream.
- Запросы (апстримы): Круговая диаграмма, показывающая распределение запросов по upstream.
- Ответы (коды): Круговая диаграмма, показывающая коды ответов для запросов к upstream.
Настраиваемые параметры
- datasource: Выбор источника данных для запроса.
- pod: Фильтрация метрик по конкретному объекту (поду), получая значения метрик для выбранного пода.
Kubernetes
Kubernetes/API-сервер
Описание
Данный дашборд предназначен для мониторинга состояния API-серверов в окружении Kubernetes. Он предоставляет возможности отслеживания доступности и производительности запросов к API, позволяя анализировать как входящие (читающие) так и исходящие (записывающие) операции. С помощью этого инструмента можно оперативно выявлять ошибки и аномалии в работе сервисов, что критически важно для обеспечения устойчивости и надежности приложений.
Скриншот
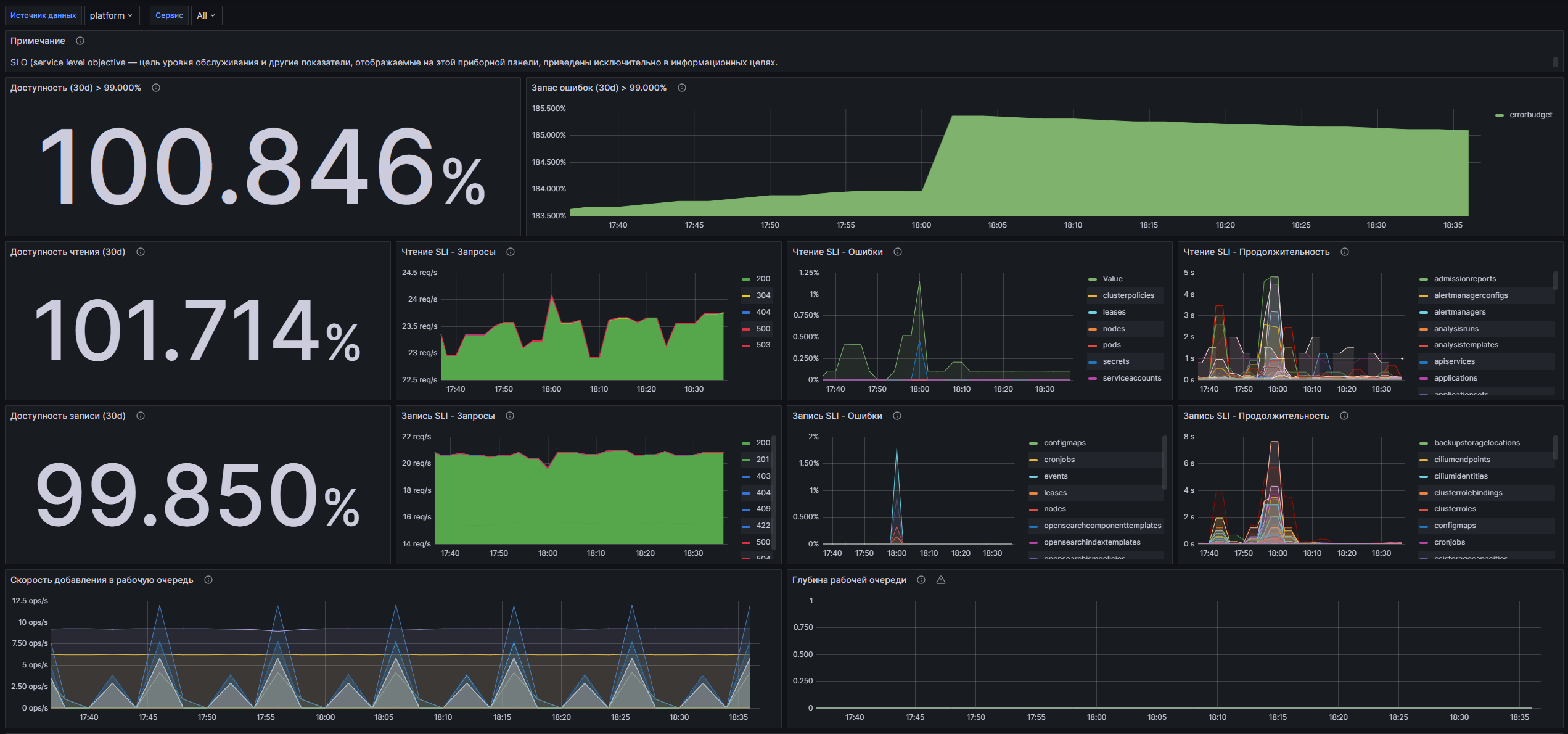
Структура дашборда
-
Ряд
- Доступность (30d) > 99.000%: Отображает процент успешных запросов к API за последние 30 дней.
- Запас ошибок (30d) > 99.000%: График, показывающий запас по ошибкам, остающимся при гарантии доступности 0,990%.
-
Ряд
- Доступность чтения (30d): Отображает процент успешных запросов на чтение (LIST, GET) за последние 30 дней.
- Чтение SLI - Запросы: График, показывающий количество запросов на чтение (LIST, GET) в секунду по кодам ответов.
- Чтение SLI - Ошибки: График, отображающий процент ошибок (5xx) среди запросов на чтение.
- Чтение SLI - Продолжительность: График, показывающий 99-й процентиль времени выполнения запросов на чтение.
-
Ряд
- Доступность записи (30d): Отображает процент успешных запросов на запись (POST, PUT, PATCH, DELETE) за последние 30 дней.
- Запись SLI - Запросы: График, показывающий количество запросов на запись в секунду по кодам ответов.
- Запись SLI - Ошибки: График, показывающий процент ошибок (5xx) среди запросов на запись.
- Запись SLI - Продолжительность: График, показывающий 99-й процентиль времени выполнения запросов на запись.
-
Ряд
- Скорость добавления в рабочую очередь: График, отображающий общее количество добавлений в рабочую очередь в секунду.
- Глубина рабочей очереди: График, показывающий количество операций ввода-вывода, обрабатываемых одновременно в очереди.
- Задержка в рабочей очереди: График, показывающий, сколько времени в секундах элемент остается в очереди перед обработкой.
-
Ряд
- Использование памяти: График, отображающий объем используемой памяти (в байтах) для API-серверов.
- Использование ЦП: График, показывающий, какое время процесс использовал в последнюю единицу времени.
- Go-рутины: График, отображающий количество активных Go-рутинов.
Настраиваемые параметры
- datasource: Название источника данных, используемого для отображения метрик, в данном случае VM Agent.
- cluster: Выбор кластера для фильтрации метрик по конкретному кластеру API-сервера.
- service: Включает все сервисы или фильтрует метрики по выбранному сервису в зависимости от выбранного кластера.
Kubernetes/Controller Manager
Описание
Данный дашборд предназначен для мониторинга Kubernetes Controller Manager и предоставляет пользователям возможность отслеживать состояние и производительность компонентов системы. С его помощью можно наблюдать важные метрики, такие как количество запущенных процессов, интенсивность добавлений в рабочую очередь, задержки запросов Kube API и использование системных ресурсов. Период обновления данных составляет 10 секунд, что позволяет получать актуальную информацию о работе кластеров в режиме реального времени.
Скриншот
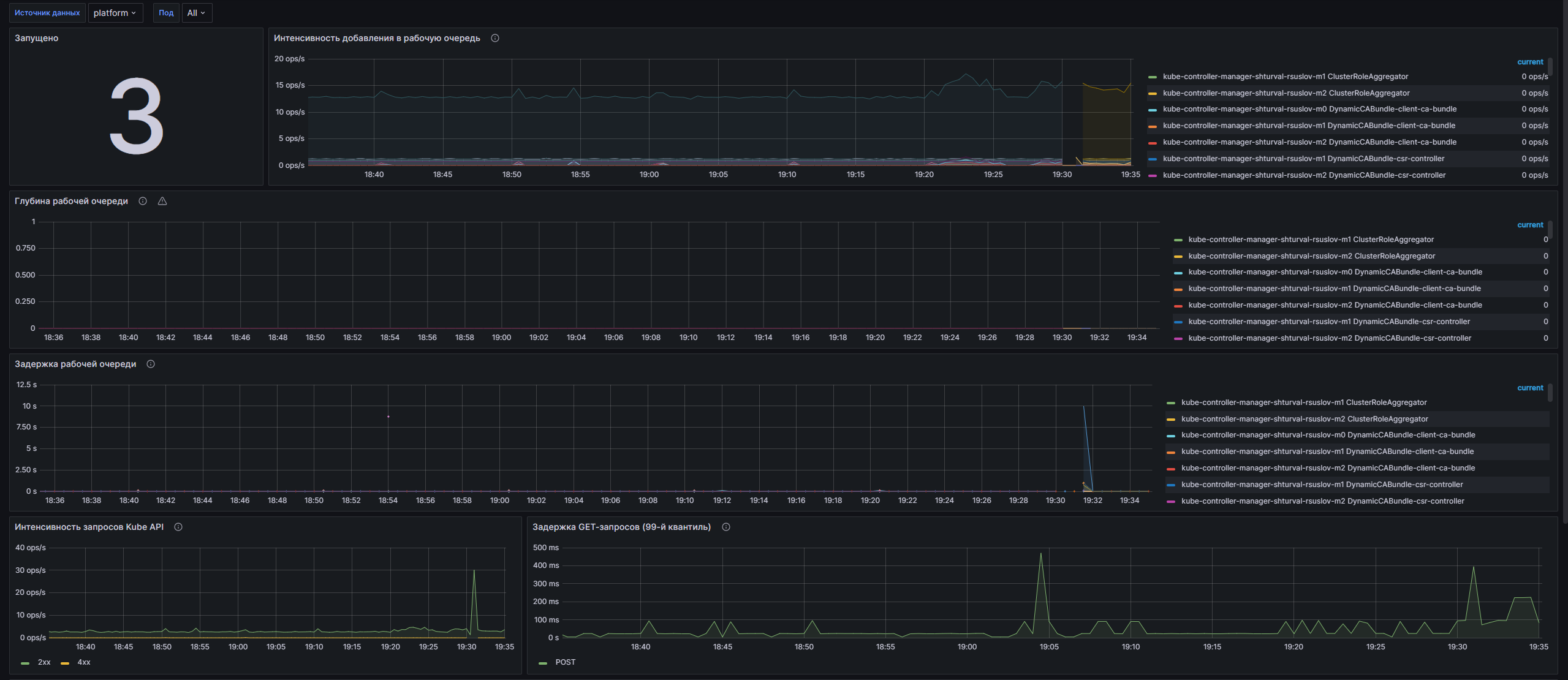
Структура дашборда
-
Ряд
- Запущено: Отображает общее количество запущенных экземпляров Kube Controller Manager на выбранном кластере.
- Интенсивность добавления в рабочую очередь: График, показывающий суммарное количество добавлений в рабочую очередь с разбивкой по кластеру и подам.
-
Ряд
- Глубина рабочей очереди: График, отображающий количество операций ввода-вывода, которые могут одновременно обрабатываться системой.
-
Ряд
- Задержка рабочей очереди: График, который показывает время, в течение которого элемент остается в рабочей очереди перед его обработкой.
-
Ряд
- Интенсивность запросов Kube API: График, который отображает общее количество клиентских запросов к Kube API с разбивкой по коду ответа.
- Задержка GET-запросов (99-й квантиль): График, показывающий задержку GET-запросов в секундах, с разбивкой по типу запроса и URL.
-
Ряд
- Задержка POST-запросов (99-й квантиль): График, отображающий задержку POST-запросов в секундах с разбивкой по типу запроса и URL.
-
Ряд
- Использование памяти: График, показывающий объем используемой памяти (в байтах) для каждого пода Kube Controller Manager.
- Использование ЦП: График, отображающий процессорное время, использованное последним объектом каждого пода за единицу времени.
- Go-рутины: График, показывающий количество активных Go-рутин в каждом поде.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для настройки дашборда.
- cluster: Используется для выбора конкретного кластера для мониторинга, основанный на значениях метки
up{job="kube-controller-manager"}. - pod: Предоставляет возможность выбора конкретного пода для мониторинга, учитывая все поды на выбранном кластере.
Kubernetes/ETCD Cluster Health
Описание
Данный дашборд предназначен для мониторинга здоровья кластера ETCD в окружении Kubernetes. Он интегрирован с системой сбора метрик VM Agent и предоставляет подробную информацию о работе ETCD, включая статус лидерства, количество изменений лидеров, размер базы данных, пропускную способность и различные метрики производительности. Пользователи могут отслеживать ключевые показатели эффективности и настраивать оповещения для повышения надежности и стабильности кластера.
Скриншот
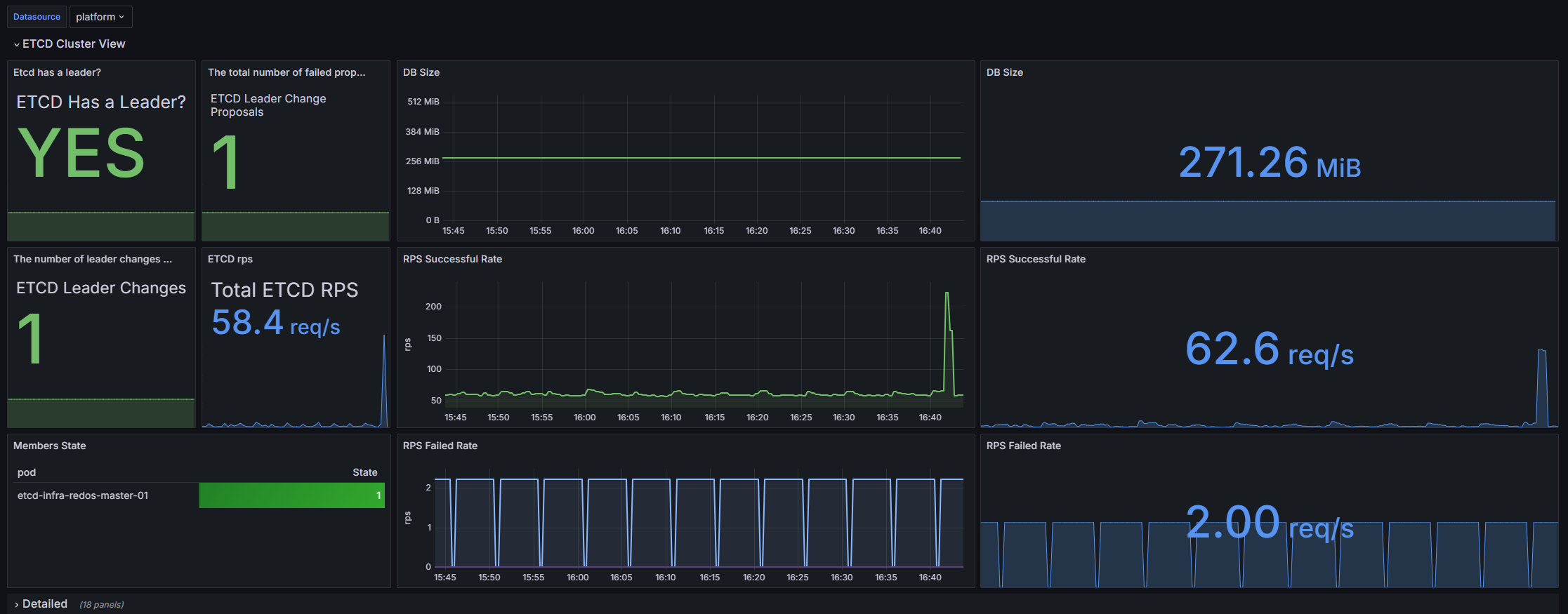
Структура дашборда
-
ETCD Cluster View
- Etcd has a leader?: Отображает информацию о наличии лидера в кластере ETCD.
- The total number of failed proposals seen: Показывает общее количество неудачных предложений в кластере.
- DB Size: Оценка общего размера базы данных, представлена как граф и статистика.
- The number of leader changes seen: Количество изменений лидеров в кластере.
- ETCD rps: Показывает количество запросов в секунду к ETCD.
- RPS Successful Rate: Успешные запросы в секунду, представлены как граф и статистика.
- Members State: Таблица состояния членов кластера, показывает, кто из них является лидером.
- RPS Failed Rate: Невыполненные запросы в секунду, представлены как граф и статистика.
-
Detailed
- Memory: График, отображающий использование памяти процессом пода ETCD.
- RPS Failed Rate: График неудачных запросов в секунду по подам.
- Disk Sync Duration: Продолжительность синхронизации на диске, представлена как график с 99-ым процентилем.
- Disk Compact Duration: Время сжатия на диске, показано дважды; один из графиков - с 99-ым процентилем.
- Heartbeat Failures: График, показывающий количество сбоев отправки heartbeat.
- Raft Proposals: Отображает общие метрики предложений Raft, включая уровень успешных и неудачных предложений.
- Proposals pending: График, показывающий количество ожидающих предложений.
- The total number of consensus proposals committed: Общее количество предложений, согласованных в кластере.
- Client Traffic In: График входящего трафика от клиентов.
- Client Traffic Out: График исходящего трафика к клиентам.
- Total Leader Elections Per Day: Общее количество выборов лидеров в день.
- Peer Traffic In: Входящий трафик между узлами кластера.
- Peer Traffic Out: Исходящий трафик между узлами кластера.
- Disks operations: График операций с дисками.
- Network: Графики общего трафика клиентов, как входящего, так и исходящего.
- Snapshot duration: Длительность снимков, устанавливает возможные проблемы с диском.
-
Alerts
- ETCD disk io latency alerts: Оповещения по задержкам ввода-вывода на диске ETCD.
- alert if 99th percentile of round trips take 150ms: Оповещения при превышении 150 мс для 99-го процентиля времени обратного движения.
- ETCD Status: Статус системы ETCD, показывает общий статус подов.
- ETCD Leader Changes Alert: Предупреждения об изменениях лидера в кластере.
- Disk Compact Duration: Оповещения по времени сжатия на диске.
- Disk Sync Duration: Оповещения по времени синхронизации на диске.
Настраиваемые параметры
- datasource: Переключатель источника данных для метрик, позволяет пользователю выбрать источник данных для получения информации.
Kubernetes/Ingress
Описание
Данный дашборд предназначен для мониторинга операторов NGINX Ingress в Kubernetes. Он позволяет пользователям отслеживать различные метрики, такие как объем запросов, коэффициенты успешности, нагрузки на сеть и использование ресурсов, а также осуществлять аналитику производительности Ingress-контроллеров. Благодаря графическому представлению данных и настраиваемым параметрам, пользователи могут легко отслеживать состояние своих приложений и выявлять потенциальные проблемы с производительностью.
Скриншот
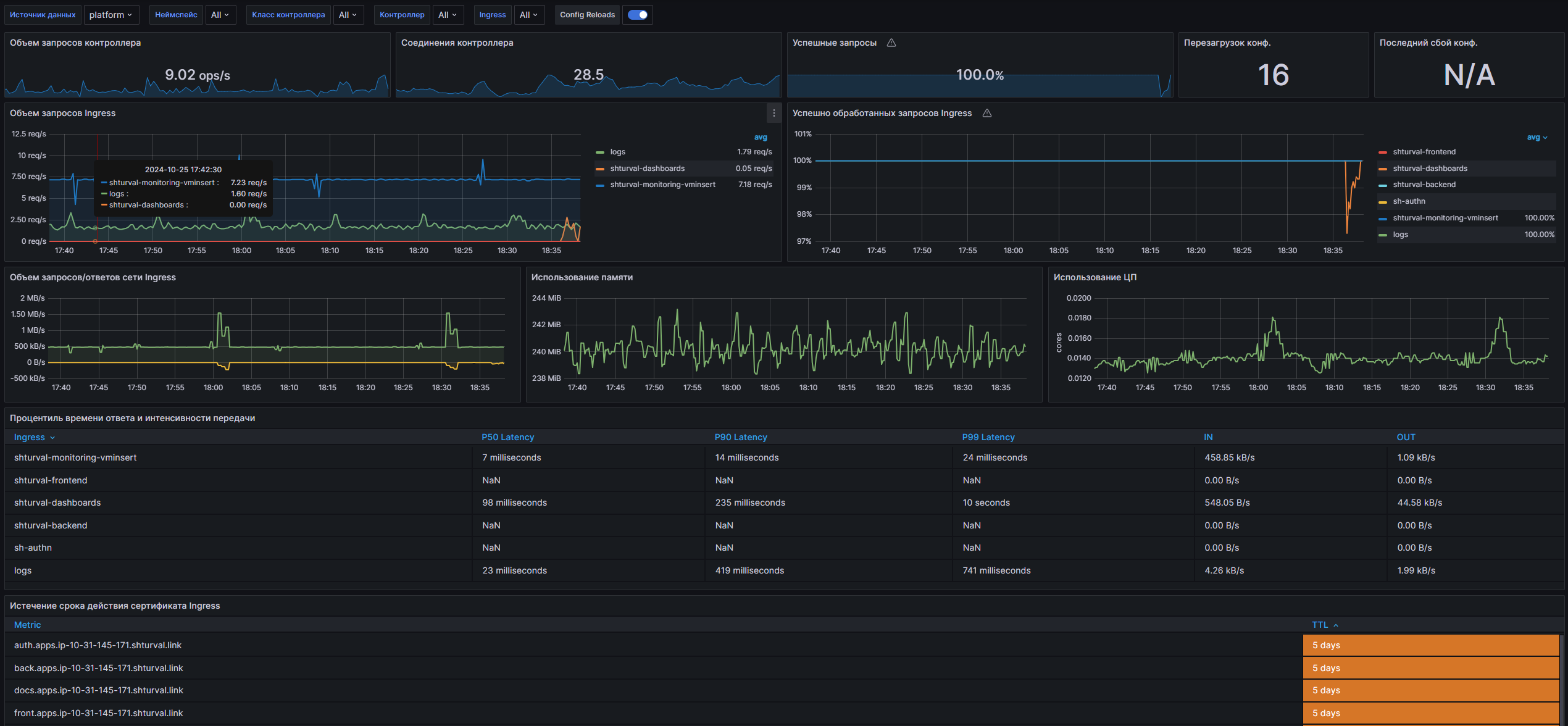
Структура дашборда
- Панели
- Controller Request Volume: Отображает объем запросов, обработанных контроллером Ingress.
- Controller Connections: Показывает количество активных соединений контроллера NGINX.
- Controller Success Rate (non-4|5xx responses): График, отображающий процент успешных ответов (коды ответов не 4xx и не 5xx).
- Config Reloads: Метрика, показывающая частоту перезагрузки конфигурации контроллера.
- Last Config Failed: Отображает количество неудачных попыток перезагрузки последней конфигурации.
- Ingress Request Volume: Временной ряд, показывающий объем запросов к определенному Ingress.
- Ingress Success Rate (non-4|5xx responses): Процент успешных ответов для конкретного Ingress.
- Network I/O pressure: Графики, показывающие входящее и исходящее сетевое давление.
- Average Memory Usage: Среднее значение потребляемой памяти контроллером NGINX.
- Average CPU Usage: Среднее значение загрузки ЦП контроллером NGINX.
- Ingress Percentile Response Times and Transfer Rates: Таблица, отображающая процентильные времена ответа и объем передаваемых данных для Ingress.
- Ingress Percentile Response Times (Ingress Namespaces): Временные ряды процентов по времени ответа для различных Ingress.
- Ingress Request Latency Heatmap (Ingress Namespaces): Тепловая карта, показывающая задержку по запросам для Ingress.
- Ingress Certificate Expiry: Таблица с информацией о времени истечения сертификатов для Ingress.
Настраиваемые параметры
- datasource: Назначение – выбор источника данных для визуализации данных мониторинга.
- namespace: Назначение – выбор неймспейса, в котором работает контроллер Ingress.
- controller_class: Назначение – выбор класса контроллера для фильтрации метрик.
- controller: Назначение – выбор конкретного пода контроллера для отслеживания метрик.
- exported_namespace: Назначение – выбор неймспейса Ingress для анализа запросов.
- ingress: Назначение – выбор конкретного Ingress для мониторинга его метрик.
Kubernetes/Kubelet
Описание
Данный дашборд предназначен для мониторинга состояния кластеров Kubernetes с использованием данных, получаемых через Kubelet. Он отображает ключевые метрики, такие как количество запущенных контейнеров, подов, а также время выполнения операций, что позволяет администраторам и DevOps-командам эффективно управлять ресурсами и реагировать на потенциальные проблемы.
Скриншот
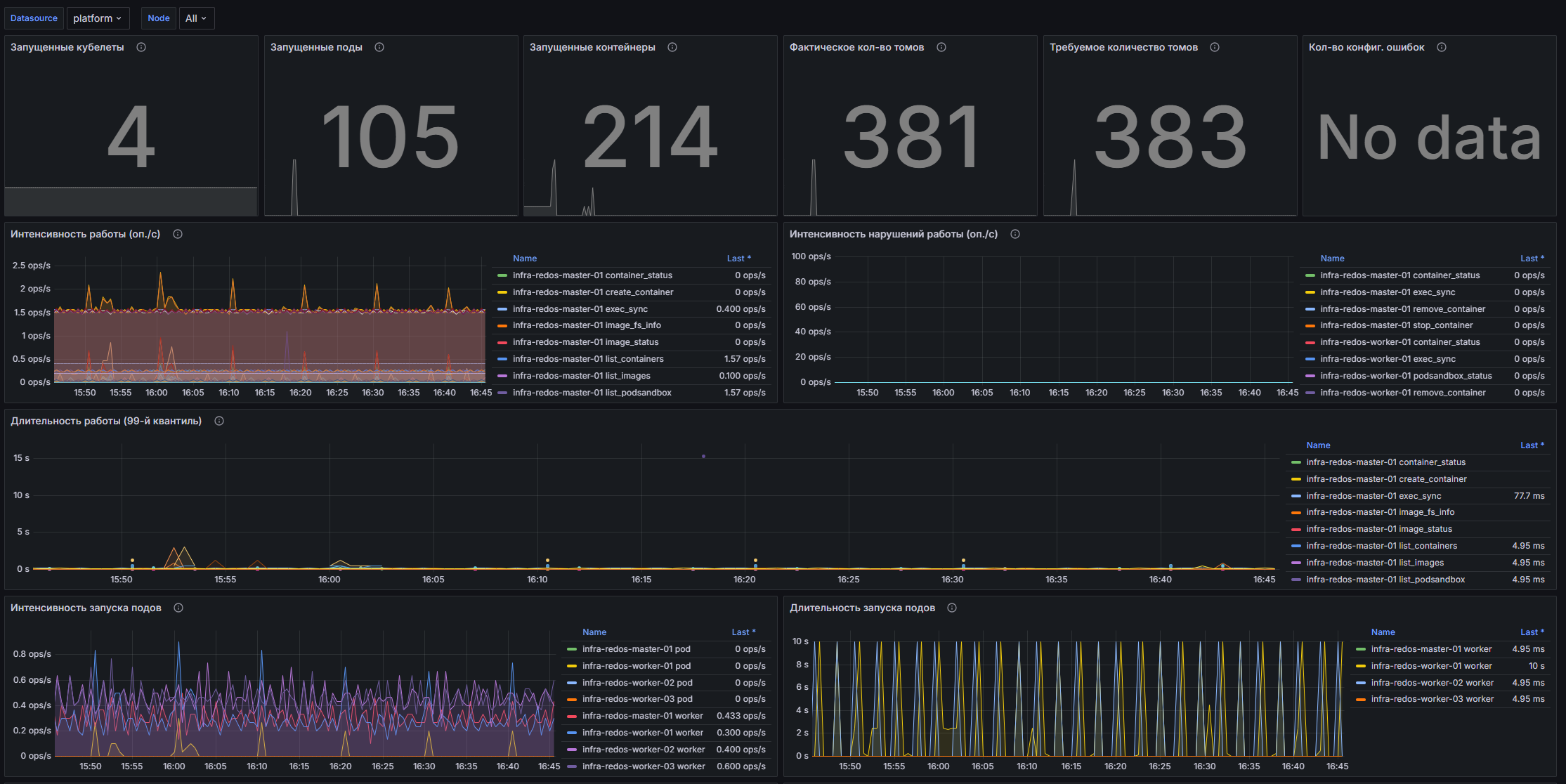
Структура дашборда
- Запущенные Kubelet: Суммарное количество всех запущенных Kubelet.
- Запущенные поды: Суммарное количество всех запущенных подов с разделением по узлам.
- Запущенные контейнеры: Суммарное количество всех запущенных контейнеров с разделением по узлам.
- Фактическое кол-во томов: Суммарное количество всех используемых томов.
- Требуемое количество томов: Суммарное количество необходимых для исправной работы томов.
- Кол-во конфиг. ошибок: Суммарное количество конфигурационных ошибок Kubelet.
- Интенсивность работы (оп./с): Количество операций в секунду по выполнению операций различных типов.
- Интенсивность нарушений работы (оп./с): Количество операций в секунду, затраченных на отдельные задачами кубелета.
- Длительность работы (99-й квантиль): 99-й квантиль количества операций в секунду некорректной работы кубелета.
- Интенсивность запуска подов (оп./с): Время, затрачиваемое на запуск подов с разделением по узлам.
- Длительность запуска подов (99-й квантиль): 99-й квантиль длительности запуска подов.
- Интенсивность работы хранилища (оп./с): Количество операций в секунду, затраченных на выполнение операций с хранилищами.
- Интенсивность нарушений работы хранилища (оп./с): Количество операций в секунду некорректной работы хранилища.
- Продолжительность работы хранилища (99-й квантиль): 99-й квантиль времени выполнения операций с хранилищем.
- Интенсивность обновления PLEG (оп./с): Количество операций в секунду, выполняемых генератором событий PLEG.
- Период обновления списка PLEG (99-й квантиль): 99-й квантиль времени обновления списка PLEG.
- Продолжительность обновления списка PLEG (99-й квантиль): 99-й квантиль времени обновления списка PLEG.
- Интенсивность удаленных вызовов (RPC): Суммарное количество удаленных клиентских запросов в секунду, распределенных по кодам ответа.
- Длительность запросов (99-й квантиль): 99-й квантиль продолжительности запросов к API.
- Память: Объем памяти, использованной кубелетом.
- Использование ЦП: Процессорное время, затраченное кубелетом.
- Go-рутины: Количество горутин, используемых кубелетом.
Настраиваемые параметры
- datasource: Источник данных для метрик.
- cluster: Выбор кластера для мониторинга.
- role: Выбор роли узлов в кластере, доступные роли могут включать в себя все роли узлов.
- node: Выбор конкретного узла для мониторинга, доступные узлы берутся из данных кластера.
Kubernetes/Networking/Cluster
Описание
Данный дашборд предназначен для мониторинга сетевой активности кластеров Kubernetes. Он предоставляет детальную информацию о передаче и получении данных, а также о состоянии сети в рамках кластеров. С помощью этого дашборда пользователи могут отслеживать ключевые метрики, такие как скорость передачи байтов, количество переданных и полученных пакетов, а также количество потерянных пакетов, что является важной частью обеспечения стабильности и производительности приложений, работающих в контейнерах.
Скриншот
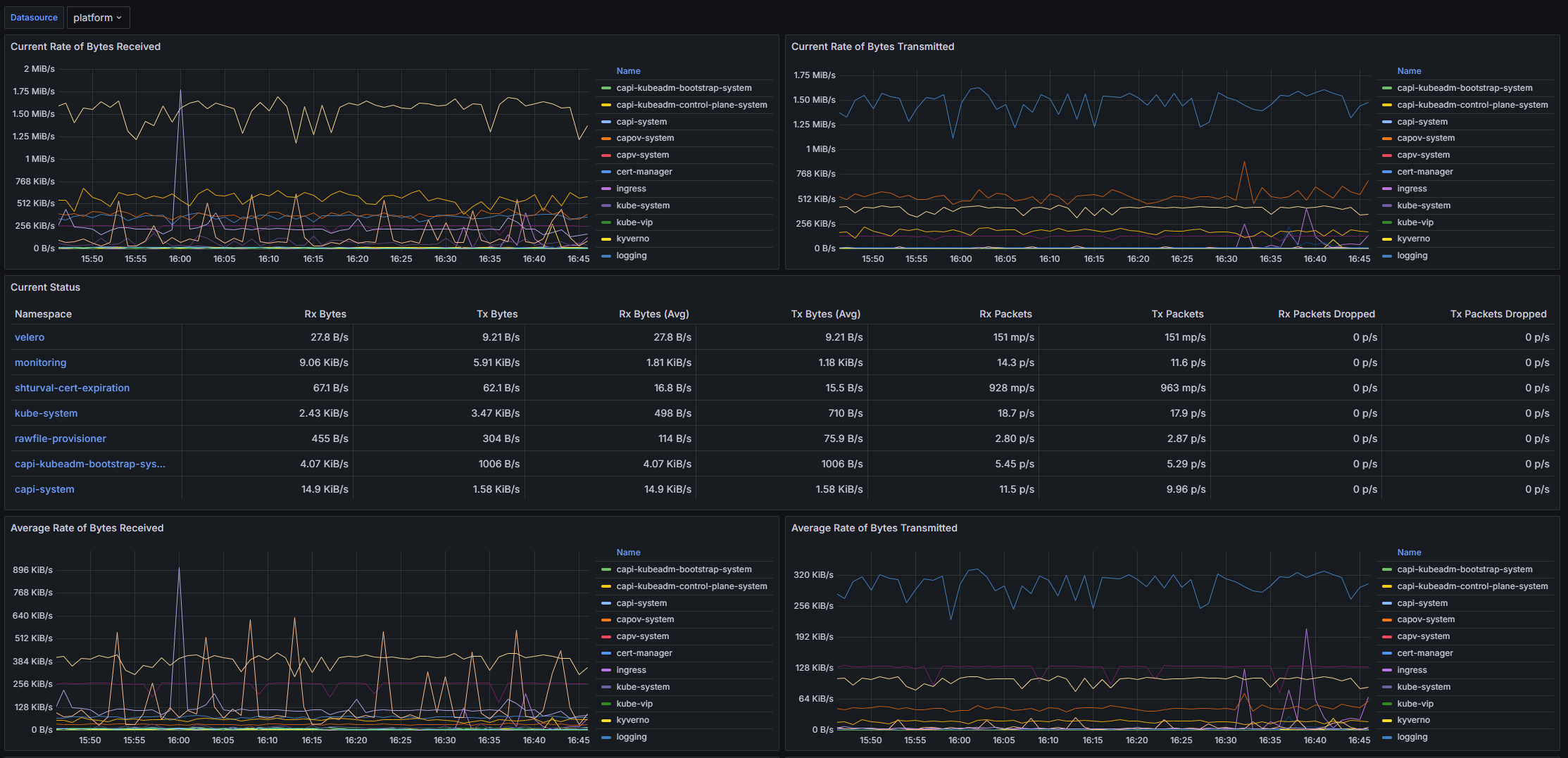
Структура дашборда
- Current Rate of Bytes Received: Панель отображает текущую скорость получения байтов по неймспейсу в кластере.
- Current Rate of Bytes Transmitted: Панель показывает текущую скорость передачи байтов по неймспейсу.
- Current Status: Таблица, в которой отображаются текущие метрики по полученным и переданным байтам, средние значения, а также количество принятых и переданных пакетов и число потерянных пакетов.
- Average Rate of Bytes Received: Панель, отображающая среднюю скорость получения байтов по неймспейсу.
- Average Rate of Bytes Transmitted: Панель, показывающая среднюю скорость передачи байтов по неймспейсу.
- Receive Bandwidth: Панель, отображающая полосу пропускания для получения трафика по неймспейсу.
- Transmit Bandwidth: Панель, показывающая полосу пропускания для передачи трафика по неймспейсу.
- Rate of Received Packets: Панель, отображающая скорость получения пакетов по неймспейсу.
- Rate of Transmitted Packets: Панель, показывающая скорость передачи пакетов по неймспейсу.
- Rate of Received Packets Dropped: Панель, отображающая скорость потерянных пакетов при получении по неймспейсу.
- Rate of Transmitted Packets Dropped: Панель, показывающая скорость потерянных пакетов при передаче по неймспейсу.
- Rate of TCP Retransmits out of all sent segments: Панель, отображающая скорость повторной передачи TCP сегментов из всех отправленных сегментов.
- Rate of TCP SYN Retransmits out of all retransmits: Панель, показывающая скорость повторной передачи TCP SYN из всех повторных передач.
Настраиваемые параметры
- datasource: Позволяет пользователю выбрать источник данных для дашборда; по умолчанию установлен на VM Agent.
- cluster: Позволяет пользователю выбрать конкретный кластер, данные о котором будут отображаться на дашборде, извлекая значения метки из данных, получаемых от kubelet.
Kubernetes/Networking/Namespace (Pods)
Описание
Данный дашборд предназначен для мониторинга сетевой активности подов в кластере Kubernetes. Он предоставляет визуализацию различных метрик, связанных с передачей и приемом сетевых данных, а также количеством переданных и потерянных пакетов. Дашборд позволяет администраторам и разработчикам отслеживать состояние сетевой активности в реальном времени, что критически важно для оптимизации производительности приложений и обеспечения стабильности работы контейнеризованных сервисов.
Скриншот
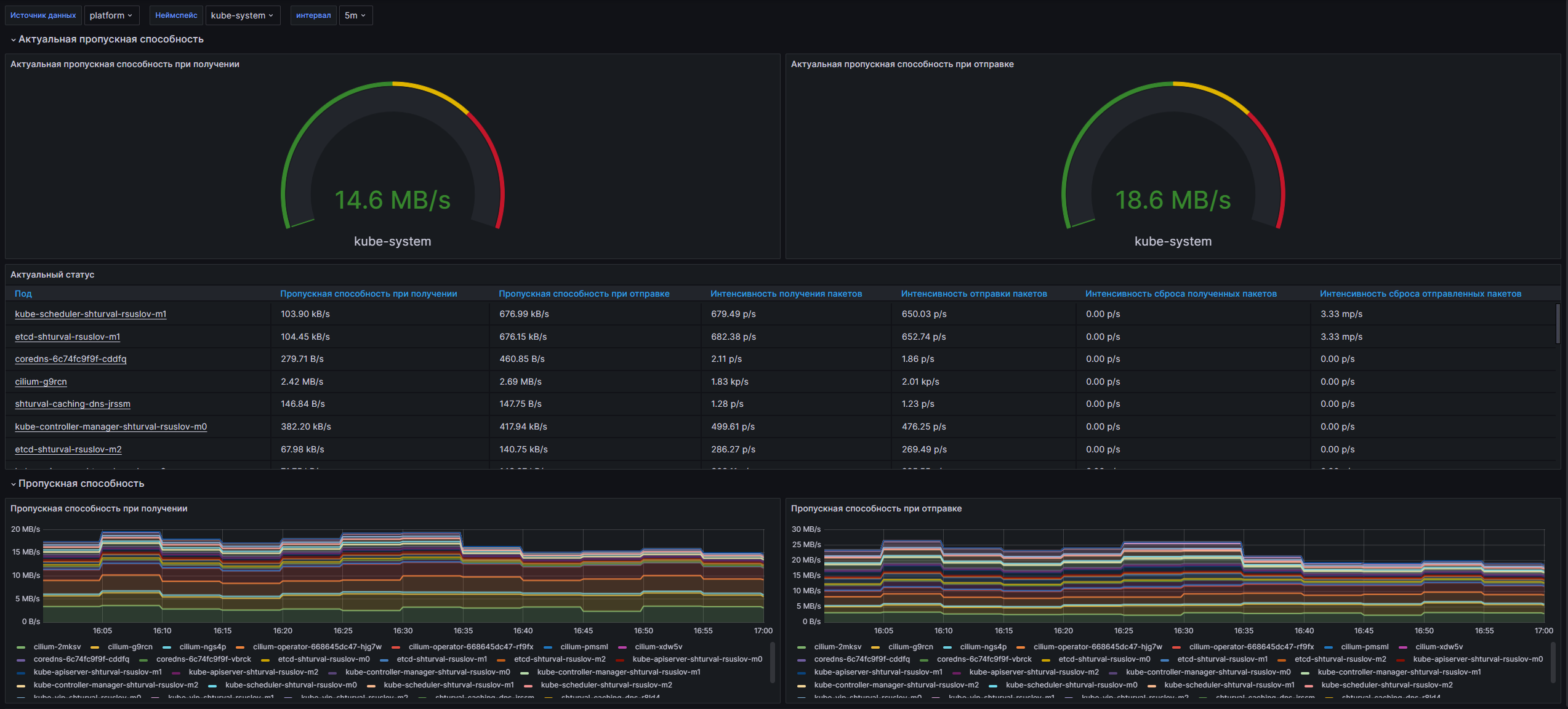
Структура дашборда
- Current Rate of Bytes Received: Панель отображает текущую скорость приема байт от подов в выбранном кластере и неймспейсе.
- Current Rate of Bytes Transmitted: Панель показывает текущую скорость передачи байт от подов.
- Current Network Usage: Таблица, в которой представлены метрики по сетевому использованию для каждого пода, включая скорость получения и передачи байт, скорость получения и передачи пакетов, а также количество потерянных пакетов.
- Receive Bandwidth: Временной ряд, отображающий скорость приема байт по подам.
- Transmit Bandwidth: Временной ряд, показывающий скорость передачи байт по подам.
- Rate of Received Packets: Временной ряд для мониторинга скорости получения пакетов по подам.
- Rate of Transmitted Packets: Временной ряд для мониторинга скорости передачи пакетов по подам.
- Rate of Received Packets Dropped: Временной ряд, показывающий скорость потерь пакетов при получении, сгруппированных по неймспейсу.
- Rate of Transmitted Packets Dropped: Временной ряд, отображающий скорость потерь пакетов при передаче по подам.
Настраиваемые параметры
- datasource: Параметр для выбора источника данных, который будет использоваться для отображения метрик.
- cluster: Параметр, позволяющий выбрать конкретный кластер Kubernetes для мониторинга.
- namespace: Параметр, позволяющий отфильтровать данные по неймспейсу, что дает возможность сосредоточиться на определенных подах в выбранном кластере.
Kubernetes/Networking/Namespace (Workload)
Описание
Данный дашборд предназначен для мониторинга сетевой активности контейнеров в окружении Kubernetes. Он предоставляет пользователю возможность отслеживать различные метрики, связанные с получением и передачей данных, а также состоянием сетевых ресурсов на уровне неймспейсов. Дашборд помогает оперативно выявлять проблемы и оптимизировать сетевую производительность путем анализа входящего и исходящего трафика, а также статистики по потерянным пакетам.
Скриншот
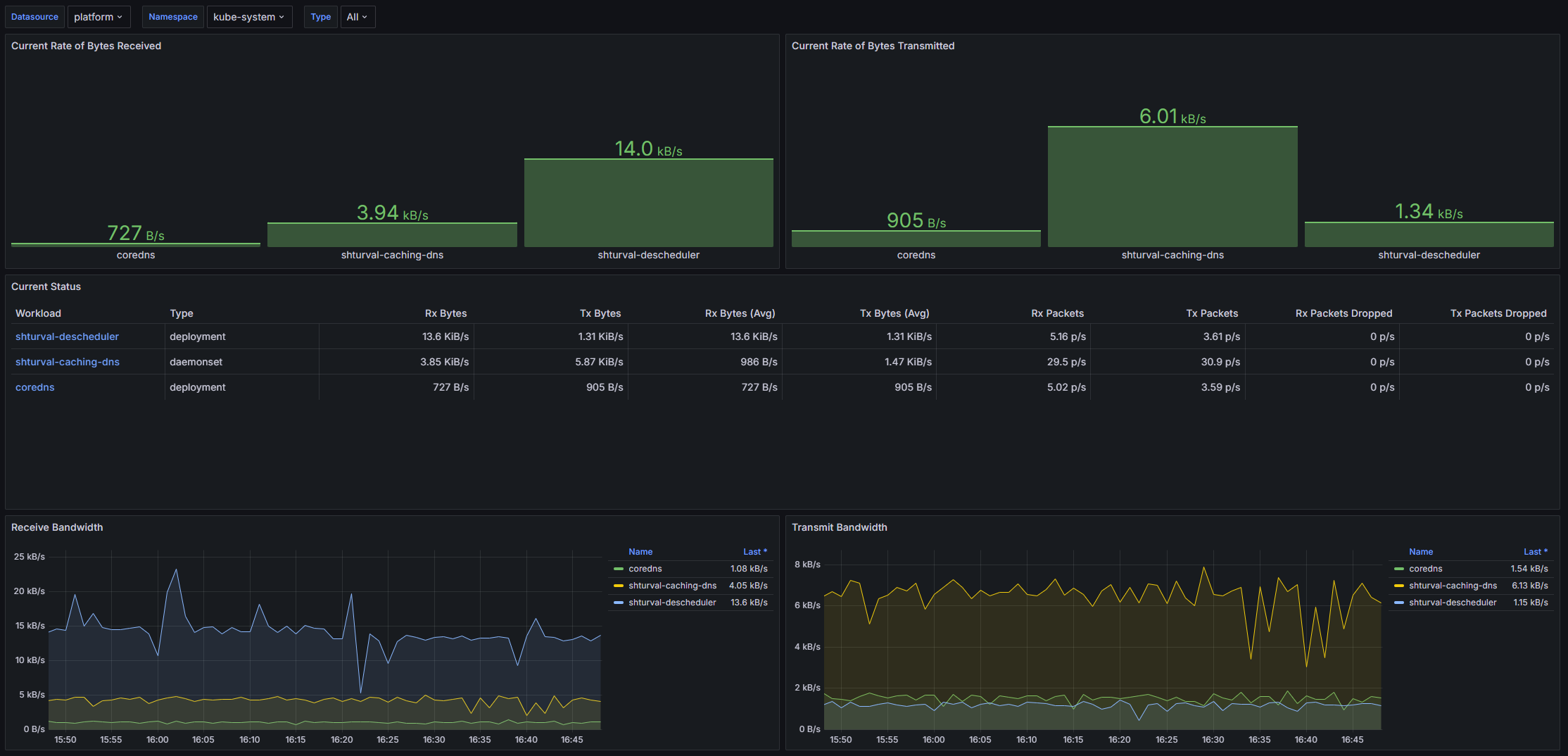
Структура дашборда
- Current Rate of Bytes Received
- Current Rate of Bytes Received: Отображает текущую скорость получения байтов в контейнерах, по различным рабочим нагрузкам.
- Current Rate of Bytes Transmitted: Отображает текущую скорость передачи байтов из контейнеров.
- Current Status: Сводная таблица состояния, показывающая количество полученных и переданных байтов, а также пакетную активность (количество принятых и переданных пакетов).
- Receive Bandwidth: График временных рядов, отображающий объем полученного трафика в байтах.
- Transmit Bandwidth: График временных рядов, показывающий объем переданного трафика в байтах.
- Average Container Bandwidth by Workload: Received: Средняя скорость получения данных контейнерами по рабочим нагрузкам.
- Average Container Bandwidth by Workload: Transmitted: Средняя скорость передачи данных контейнерами по рабочим нагрузкам.
- Rate of Received Packets: График временных рядов, показывающий скорость получения пакетов.
- Rate of Transmitted Packets: График временных рядов, показывающий скорость передачи пакетов.
- Rate of Received Packets Dropped: График, отображающий скорость потерянных пакетов при получении.
- Rate of Transmitted Packets Dropped: График, отображающий скорость потерянных пакетов при передаче.
Настраиваемые параметры
- datasource: Определяет источник данных для запроса метрик, заданный в формате VM Agent.
- cluster: Позволяет выбрать конкретный кластер Kubernetes для анализа метрик.
- namespace: Позволяет отфильтровать метрики по определенному неймспейсу в кластере.
- type: Дает возможность выбора типа рабочей нагрузки, что позволяет более точно настроить отображаемые метрики.
Kubernetes/Networking/Pod
Описание
Данный дашборд предназначен для мониторинга сетевых показателей в среде Kubernetes. Он предоставляет пользователю возможность отслеживать текущие параметры сети, такие как скорость получения и передачи данных, а также количество пакетов, полученных и отправленных контейнерами. Дашборд использует данные из VM Agent для визуализации метрик, что позволяет быстро выявлять проблемы с сетью и анализировать производительность приложений.
Скриншот
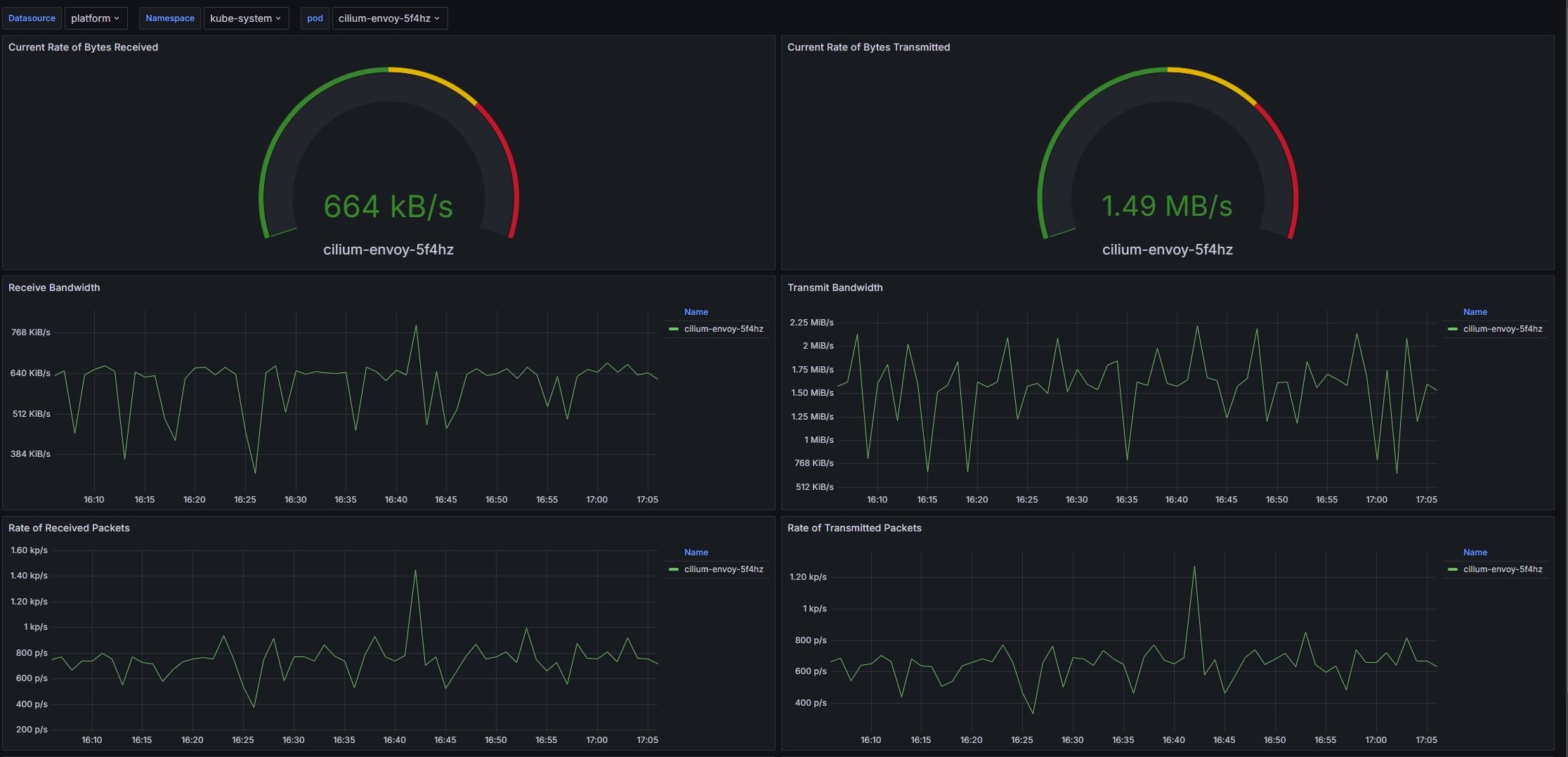
Структура дашборда
- Current Rate of Bytes Received: Панель отображает текущую скорость получения байтов по указанному кластеру, неймспейсу и поду.
- Current Rate of Bytes Transmitted: Панель показывает текущую скорость передачи байтов для заданных параметров.
- Receive Bandwidth: Панель представляет собой временной ряд, отображающий скорость получения данных для каждого пода на протяжении времени.
- Transmit Bandwidth: Эта панель отображает временной ряд, показывающий скорость передачи данных для каждого пода.
- Rate of Received Packets: Панель визуализирует скорость получения пакетов сети, сгруппированных по подам.
- Rate of Transmitted Packets: Панель показывает скорость передачи пакетов в сети для каждого пода.
- Rate of Received Packets Dropped: Эта панель отображает скорость потерянных пакетов, полученных по сети, для каждого пода.
- Rate of Transmitted Packets Dropped: Панель визуализирует скорость потерянных пакетов на уровне передачи для каждого пода.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для запросов, используемый в панелях дашборда.
- cluster: Позволяет выбрать кластер Kubernetes для фильтрации метрик.
- namespace: Возможность выбора неймспейса, для которого будут отображаться метрики.
- pod: Позволяет выбирать конкретный под для анализа сетевых показателей.
Kubernetes/Networking/Workload
Описание
Данный дашборд предназначен для мониторинга сетевых показателей в средах Kubernetes. Он предоставляет пользователям возможность отслеживать текущие и средние скорости приема и передачи байтов, а также количество полученных и переданных пакетов. Это особенно полезно для администраторов и разработчиков, ответственных за производительность и надежность приложений, работающих в кластерах Kubernetes. Дашборд освещает критические метрики, которые помогают выявлять узкие места в сетевом взаимодействии рабочих нагрузок.
Скриншот
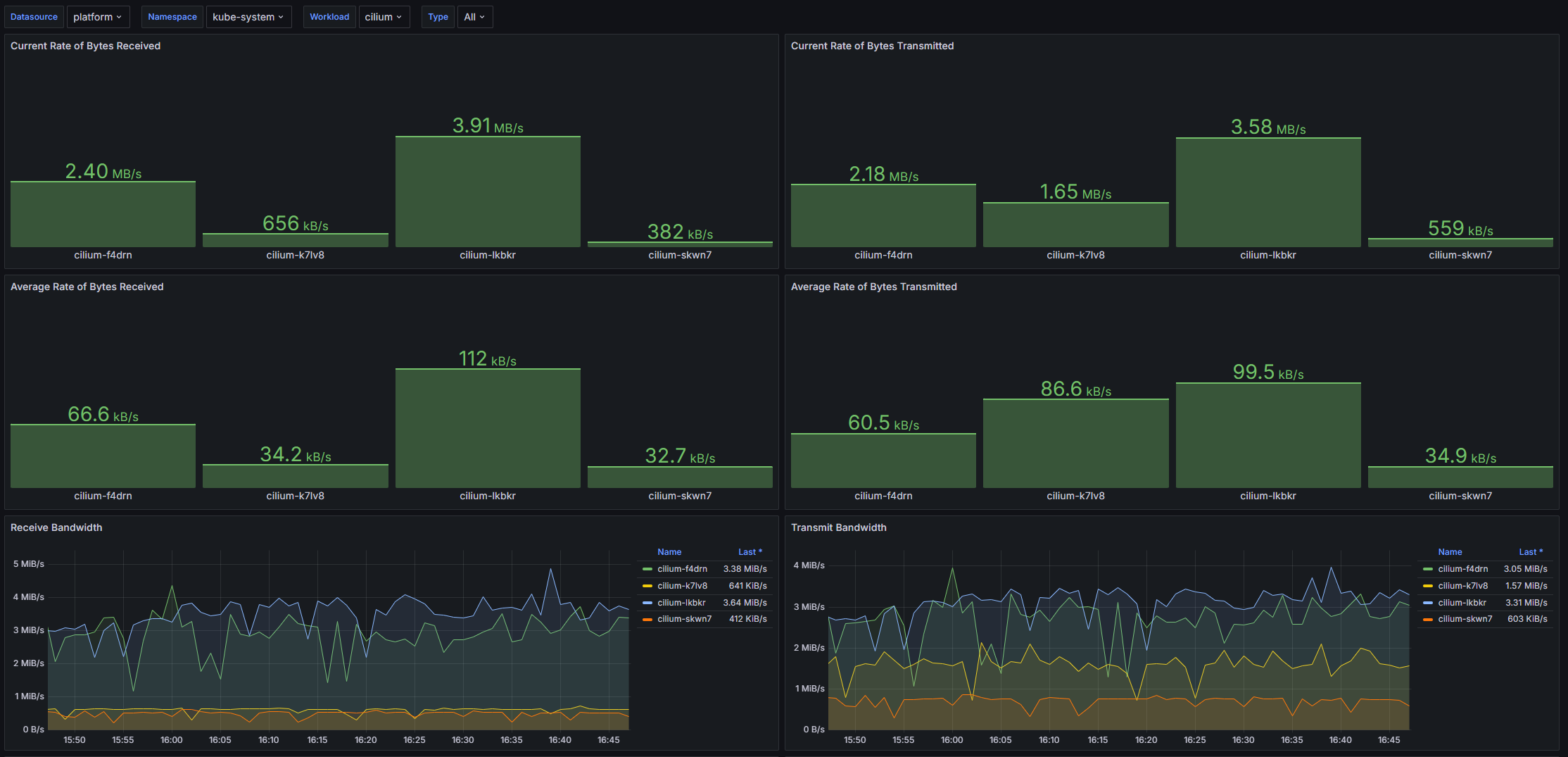
Структура дашборда
- Показатели сетевой активности
- Current Rate of Bytes Received: Отображает текущую скорость приема байтов в секундах для выбранных рабочих нагрузок.
- Current Rate of Bytes Transmitted: Отображает текущую скорость передачи байтов в секундах для выбранных рабочих нагрузок.
- Average Rate of Bytes Received: Предоставляет среднюю скорость приема байтов для выбранных рабочих нагрузок.
- Average Rate of Bytes Transmitted: Предоставляет среднюю скорость передачи байтов для выбранных рабочих нагрузок.
- Receive Bandwidth: Отображает график потребляемой полосы пропускания для получаемых байтов.
- Transmit Bandwidth: Отображает график потребляемой полосы пропускания для передаваемых байтов.
- Rate of Received Packets: Отображает скорость получения пакетов в секунду для выбранных рабочих нагрузок.
- Rate of Transmitted Packets: Отображает скорость передачи пакетов в секунду для выбранных рабочих нагрузок.
- Rate of Received Packets Dropped: Отображает скорость потерянных пакетов при получении в секунду для выбранных рабочих нагрузок.
- Rate of Transmitted Packets Dropped: Отображает скорость потерянных пакетов при передаче в секунду для выбранных рабочих нагрузок.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных (например, VM Agent), который будет использоваться для сбора метрик.
- cluster: Позволяет выбрать кластер Kubernetes, для которого будут запрашиваться метрики.
- namespace: Позволяет выбрать неймспейс в кластере, для которого будут отображаться метрики.
- workload: Позволяет выбрать конкретную загрузку по рабочим нагрузкам внутри указанного неймспейса.
- type: Позволяет выбрать тип нагрузки, чтобы фильтровать метрики по конкретным рабочим нагрузкам.
Kubernetes/Persistent Volumes
Описание
Данный дашборд предназначен для мониторинга использования ресурсов постоянных томов в среде Kubernetes. Он позволяет отслеживать параметры, такие как объем занятой и свободной памяти, а также использование inode-томов. Этот инструмент полезен для администраторов системы и DevOps-специалистов, обеспечивая возможность контролировать состояние хранения данных и предотвращать возможные проблемы с нехваткой ресурсов.
Скриншот
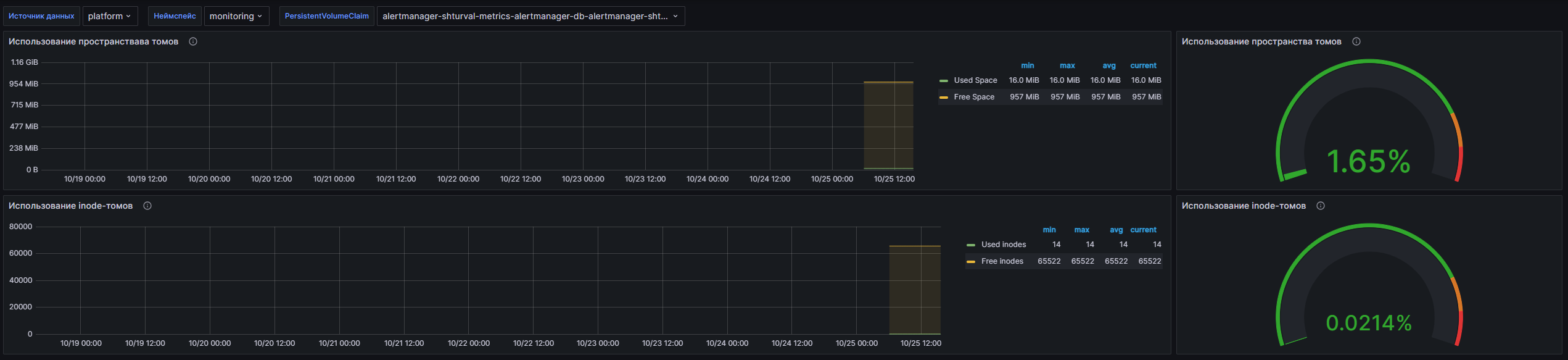
Структура дашборда
- Dashboard
- Использование пространства томов: Отображает график, показывающий объем занятой и свободной памяти постоянных томов. Метрики вычисляются с использованием запросов к kubelet, позволяя анализировать актуальное состояние использования хранилища.
- Использование пространства томов: Отображает текущее значение процента использования памяти постоянных томов. Данная панель предоставляет быстрое понимание загруженности хранилища.
- Использование inode-томов: Отображает график, показывающий количество использованных inode на постоянных томах. Это важно для понимания того, насколько эффективно используются метаданные при работе с файловой системой.
- Использование inode-томов: Показатель процента использованных inode, позволяющий быстро определить текущее состояние inode-ресурса.
Настраиваемые параметры
- datasource: Используется для выбора источника данных, который будет применяться для метрик дашборда.
- cluster: Позволяет выбрать конкретный кластер для отображения метрик, связанных с постоянными томами.
- namespace: Данный параметр используется для фильтрации метрик по неймспейсу в рамках заданного кластера.
- volume: Даёт возможность выбрать конкретный PersistentVolumeClaim для детального анализа его состояния.
Kubernetes/Прокси
Описание
Данный дашборд предоставляет инструменты для мониторинга работы kube-proxy в кластерах Kubernetes. Он отображает ключевые метрики, позволяя пользователям отслеживать состояние и производительность сетевой составляющей Kubernetes. Основные возможности включают мониторинг запущенных экземпляров, задержек в синхронизации правил, задержек сетевого программирования, а также информации о запросах к Kube API и использования ресурсов.
Структура дашборда
- Запущено: Количество запущенных экземпляров kube-proxy.
- Интенсивность синхронизации правил: Длительность синхронизации kube-proxy в операциях в секунду.
- Задержка синхронизации правил (99-й квантиль): 99-й квантиль времени задержки при синхронизации kube-proxy.
- Сетевое программирование: Задержка сетевого программирования в секундах.
- Задержка сетевого программирования (99-й квантиль): 99-й квантиль задержки сетевого программирования.
- Интенсивность запросов Kube API: Количество HTTP-запросов, распределенных по коду статуса, методу и хосту.
- Задержка POST-запроса (99-й квантиль): 99-й квантиль задержки POST-запроса.
- Задержка GET-запроса (99-й квантиль): 99-й квантиль задержки GET-запроса.
- Память: Объем памяти, используемой kube-proxy.
- Использование ЦП: Процессорное время, затраченное на kube-proxy.
- Go-рутины: Число go-рутин, используемых kube-proxy.
Настраиваемые параметры
- datasource: Используемый источник данных, в данном случае VM Agent.
- cluster: Название кластера, для которого будет производиться мониторинг.
- service: Название службы в кластере, для которой будут отображаться метрики.
Kubernetes/Compute Resources/Cluster
Описание
Данный дашборд предназначен для мониторинга ресурсов вычислений в кластере Kubernetes. Он предоставляет пользователям возможность отслеживать использование CPU и памяти, запрашиваемые и лимитированные ресурсы, а также сетевую активность и I/O операции контейнеров. С помощью этого дашборда администраторы могут быстро оценить состояние кластера, выявить узкие места в ресурсах и оптимизировать распределение нагрузки.
Скриншот
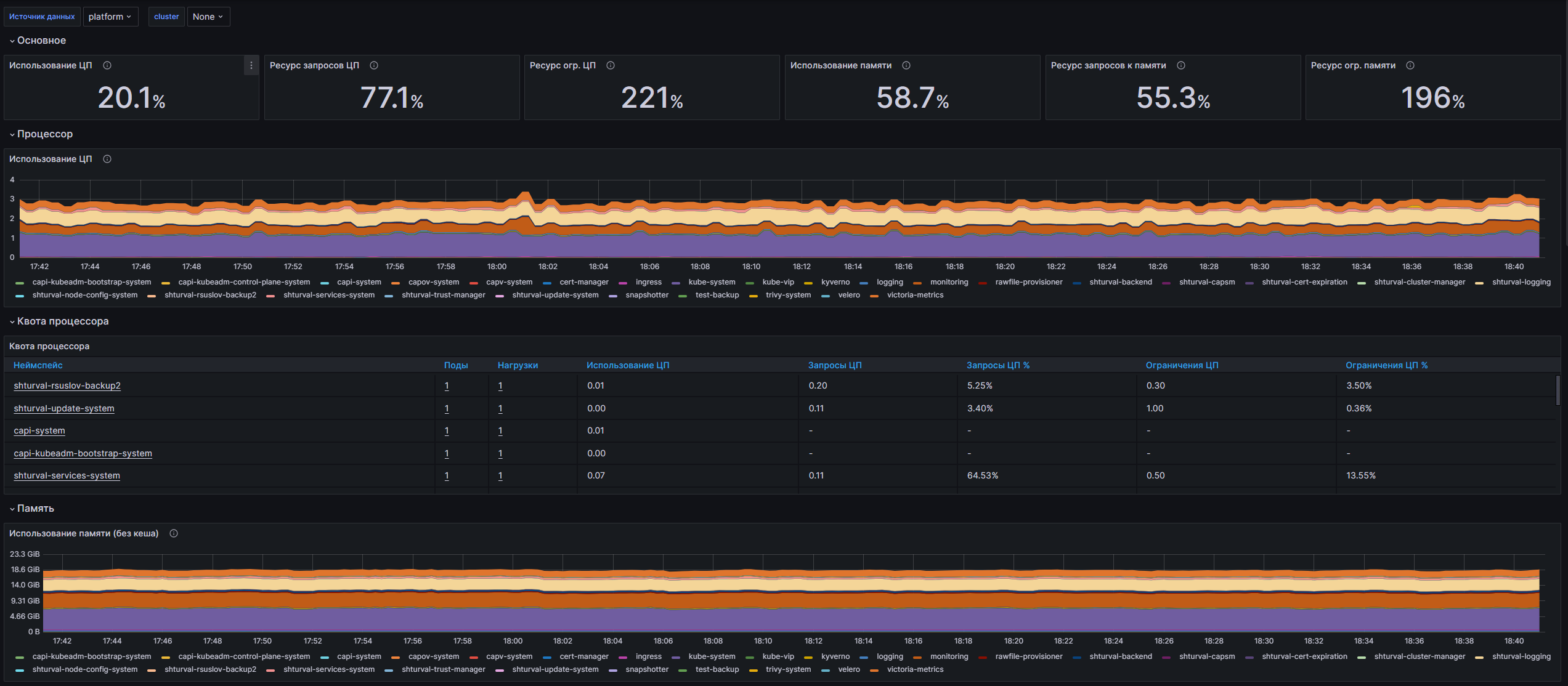
Структура дашборда
-
CPU Utilisation
- CPU Utilisation: Отображает коэффициент использования CPU на протяжении времени для выбранного кластера.
- CPU Requests Commitment: Показывает соотношение запрашиваемых ресурсов CPU к общему количеству доступных ресурсов.
- CPU Limits Commitment: демонстрирует соотношение лимитов ресурсов CPU к общему количеству доступных ресурсов.
-
Memory Utilisation
- Memory Utilisation: Отображает процент использованной памяти по сравнению с общей доступной памятью в кластере.
- Memory Requests Commitment: Показывает соотношение запрашиваемых ресурсов памяти к общему количеству доступных ресурсов.
- Memory Limits Commitment: Демонстрирует соотношение лимитов ресурсов памяти к общему количеству доступных ресурсов.
-
CPU Usage
- CPU Usage: Отображает использование CPU по неймспейсу в виде временного ряда.
-
CPU Quota
- CPU Quota: Таблица, которая отображает данные о владельцах подов, количестве подов, использующем CPU, запрашиваемых ресурсах CPU и соотношении использования к лимитам по неймспейсам.
-
Memory
- Memory: Отображает использование памяти контейнерами по неймспейсам в виде временного ряда.
-
Memory Requests by Namespace
- Memory Requests by Namespace: Таблица, отображающая информацию о владении подами, использовании памяти и запрашиваемых ресурсах по неймспейсам.
-
Current Network Usage
- Current Network Usage: Таблица, которая показывает текущую сетевую загрузку, включая количество переданных и полученных байтов и пакетов, а также количество потерянных пакетов по неймспейсам.
-
Receive Bandwidth
- Receive Bandwidth: Отображает временной ряд входящей полосы пропускания для контейнеров по неймспейсам.
-
Transmit Bandwidth
- Transmit Bandwidth: Отображает временной ряд исходящей полосы пропускания для контейнеров по неймспейсам.
-
Average Container Bandwidth by Namespace: Received
- Average Container Bandwidth by Namespace: Received: Временной ряд, показывающий среднюю входящую полосу пропускания контейнеров по неймспейсам.
-
Average Container Bandwidth by Namespace: Transmitted
- Average Container Bandwidth by Namespace: Transmitted: Временной ряд, демонстрирующий среднюю исходящую полосу пропускания контейнеров по неймспейсам.
-
Rate of Received Packets
- Rate of Received Packets: Временной ряд, отображающий скорость потока пакетов, полученных контейнерами по неймспейсам.
-
Rate of Transmitted Packets
- Rate of Transmitted Packets: Временной ряд, показывающий скорость потока пакетов, отправленных контейнерами по неймспейсам.
-
Rate of Received Packets Dropped
- Rate of Received Packets Dropped: Временной ряд, отображающий скорость потерянных пакетов, полученных контейнерами по неймспейсам.
-
Rate of Transmitted Packets Dropped
- Rate of Transmitted Packets Dropped: Временной ряд, показывающий скорость потерянных пакетов, отправленных контейнерами по неймспейсам.
-
IOPS(Reads+Writes)
- IOPS(Reads+Writes): Временной ряд, показывающий количество операций ввода-вывода в секунду (чтения и записи) по неймспейсам.
-
ThroughPut(Read+Write)
- ThroughPut(Read+Write): Временной ряд, отображающий объем данных, прочитанных и записанных с контейнерами, по неймспейсам.
-
Current Storage IO
- Current Storage IO: Таблица, показывающая характеристики I/O контейнеров, включая чтения и записи данных, по неймспейсам
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для мониторинга, по умолчанию установлен на VM Agent.
- cluster: Позволяет выбирать кластер, для которого будут отображаться метрики, извлекая информацию из параметров метрик Kubernetes.
Kubernetes/Compute Resources/Namespace (Pods)
Описание
Данный дашборд предоставляет комплексный мониторинг ресурсов вычислений в Kubernetes-кластере на уровне неймспейса. Он позволяет отслеживать использование CPU и памяти, а также сетевую и дисковую активность контейнеров. Используя метрики от kube-state-metrics и kubelet, дашборд предлагает пользователю возможность визуализировать ключевые показатели производительности, выявлять узкие места и оптимизировать ресурсы в реальном времени.
Скриншот
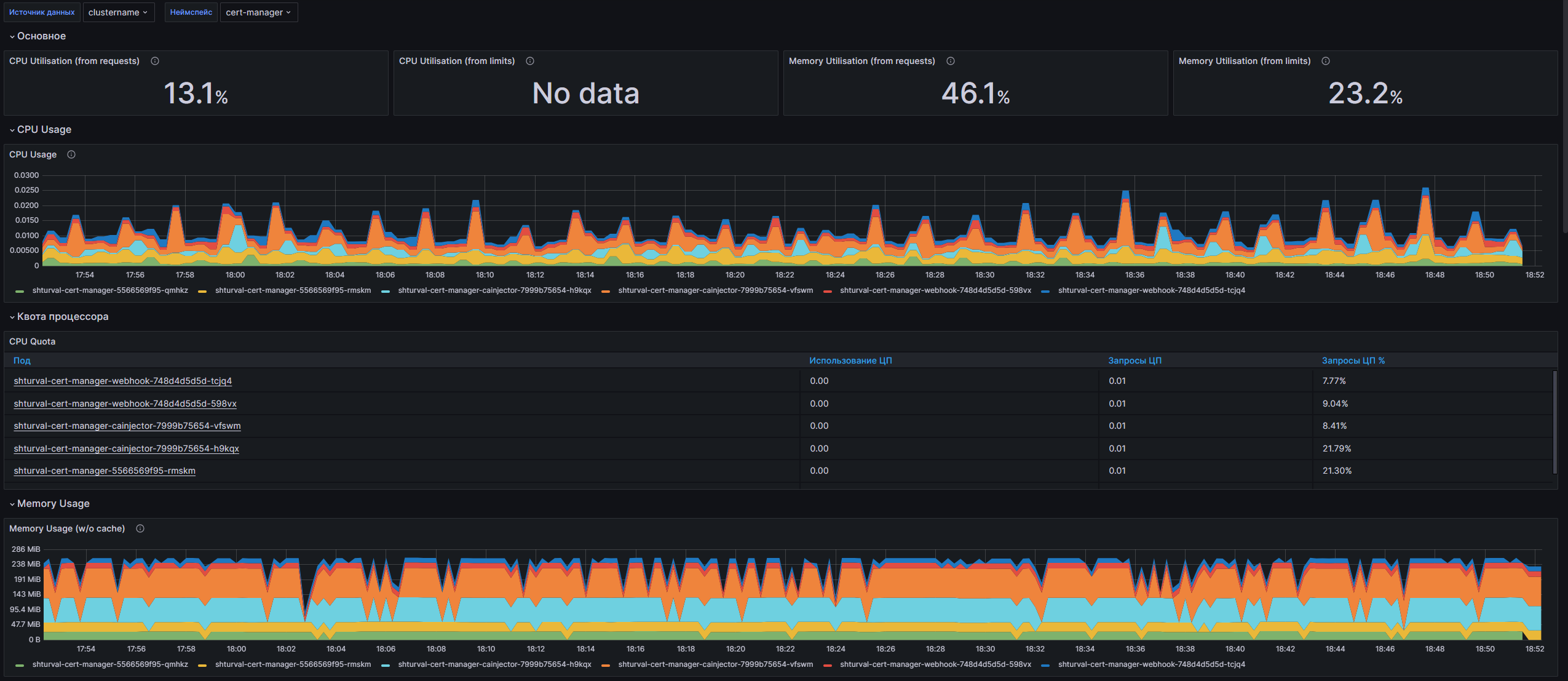
Структура дашборда
- CPU Utilisation (from requests): Отображает использование CPU в процентах на основании запрашиваемых ресурсов.
- CPU Utilisation (from limits): Показывает использование CPU в процентах на основании установленных лимитов.
- Memory Utilisation (from requests): Выводит использование памяти на основании запрашиваемых ресурсов.
- Memory Utilisation (from limits): Отображает использование памяти на основании установленных лимитов.
- CPU Usage: Стремится визуализировать общее использование CPU для каждого пода, а также сравнивает с квотами на ресурсы.
- CPU Quota: Таблица, показывающая использование CPU по подам и их квоты на ресурс, как по запросам, так и по лимитам.
- Memory Usage (w/o cache): Визуализирует использование памяти без учета кэша на уровне подов.
- Memory Quota: Таблица, показывающая использование памяти и квоты на ресурс для каждого пода.
- Current Network Usage: Таблица, отображающая текущую сетевую активность, включая количество полученных и переданных байтов и пакетов.
- Receive Bandwidth: График, показывающий количество полученных байтов по подам.
- Transmit Bandwidth: График, отображающий количество переданных байтов по подам.
- Rate of Received Packets: Визуализация скорости полученных пакетов по подам.
- Rate of Transmitted Packets: Визуализация скорости переданных пакетов по подам.
- Rate of Received Packets Dropped: График, отображающий скорость потерянных пакетов при получении.
- Rate of Transmitted Packets Dropped: График, показывающий скорость потерянных пакетов при передаче.
- IOPS(Reads+Writes): Визуализирует количество операций чтения и записи на уровне подов.
- ThroughPut(Read+Write): Отображает пропускную способность чтения и записи для подов.
- Current Storage IO: Таблица, показывающая текущие операции ввода-вывода для контейнеров по подам.
Настраиваемые параметры
- datasource: Выбор источника данных для получения метрик, в данном случае используется VM Agent.
- cluster: Позволяет пользователю выбрать конкретный кластер для мониторинга, извлекая значения меток с помощью запроса.
- namespace: Позволяет пользователю выбрать неймспейс, для которого будут отображаться метрики, также извлекая значения через запрос.
Kubernetes/Compute Resources/Namespace (Workloads)
Описание
Данный дашборд предназначен для мониторинга ресурсов вычислений в кластере Kubernetes на уровне неймспейса. Он предоставляет пользователям возможность отслеживать использование CPU и памяти, а также сетевую активность контейнеров внутри рабочих нагрузок. С помощью данного дашборда можно эффективно управлять ресурсами, выявлять перегрузки и оптимизировать распределение нагрузки на кластер.
Скриншот
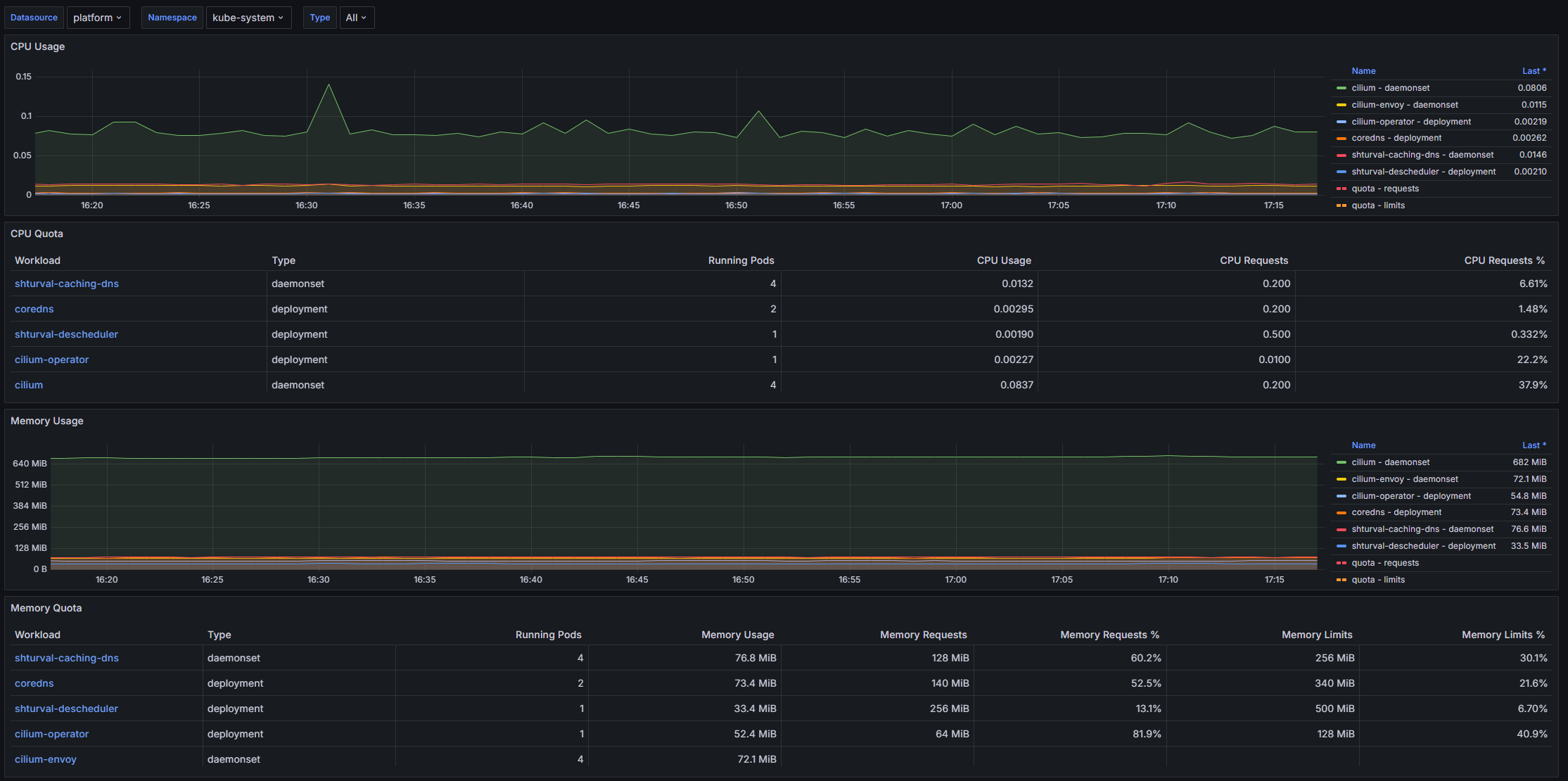
Структура дашборда
-
CPU Usage
- CPU Usage: Отображает временной ряд использования CPU контейнерами в выбранном неймспейсе и рабочей нагрузке.
- CPU Quota: Таблица, показывающая информацию о квотах CPU на уровне рабочих нагрузок, включая полное использование и запрашиваемые ресурсы.
-
Memory Usage
- Memory Usage: Отображает временной ряд использования памяти контейнерами в выбранном неймспейсе и рабочей нагрузке.
- Memory Quota: Таблица, показывающая информацию о квотах памяти на уровне рабочих нагрузок, включая полное использование и запрашиваемые ресурсы.
-
Current Network Usage
- Current Network Usage: Таблица, представляющая текущую сетевую активность для выбранных контейнеров, включая полученные и переданные байты, пакеты и их потери.
-
Network Bandwidth
- Receive Bandwidth: Временной ряд, отображающий скорость получения сетевых данных на уровне рабочих нагрузок.
- Transmit Bandwidth: Временной ряд, отображающий скорость передачи сетевых данных на уровне рабочих нагрузок.
- Average Container Bandwidth by Workload: Received: Временной ряд, показывающий среднюю скорость получения данных контейнерами по рабочей нагрузке.
- Average Container Bandwidth by Workload: Transmitted: Временной ряд, показывающий среднюю скорость передачи данных контейнерами по рабочей нагрузке.
- Rate of Received Packets: Временной ряд, отображающий скорость получения сетевых пакетов.
- Rate of Transmitted Packets: Временной ряд, отображающий скорость передачи сетевых пакетов.
- Rate of Received Packets Dropped: Временной ряд, показывающий скорость потерь полученных пакетов.
- Rate of Transmitted Packets Dropped: Временной ряд, показывающий скорость потерь переданных пакетов.
Настраиваемые параметры
- datasource: Определяет источник данных для отображаемых метрик.
- cluster: Позволяет выбрать кластер, для которого будет производиться мониторинг ресурсов.
- namespace: Позволяет выбрать неймспейс, в пределах которого будут мониториться ресурсы.
- type: Позволяет выбрать тип рабочей нагрузки (workload) для более детального анализа метрик.
Kubernetes/Compute Resources/Node (Pods)
Описание
Данный дашборд предназначен для мониторинга ресурсов вычислительных узлов в кластере Kubernetes. Он предоставляет важную информацию о потреблении ресурсов, таких как CPU и память, а также их квотах для отдельных подов. Пользователи могут быстро оценить текущее состояние узлов, контролируя максимальные доступные мощности и использование ресурсов, что является ключевым аспектом для обеспечения высокой производительности и стабильности приложений в контейнерах.
Скриншот
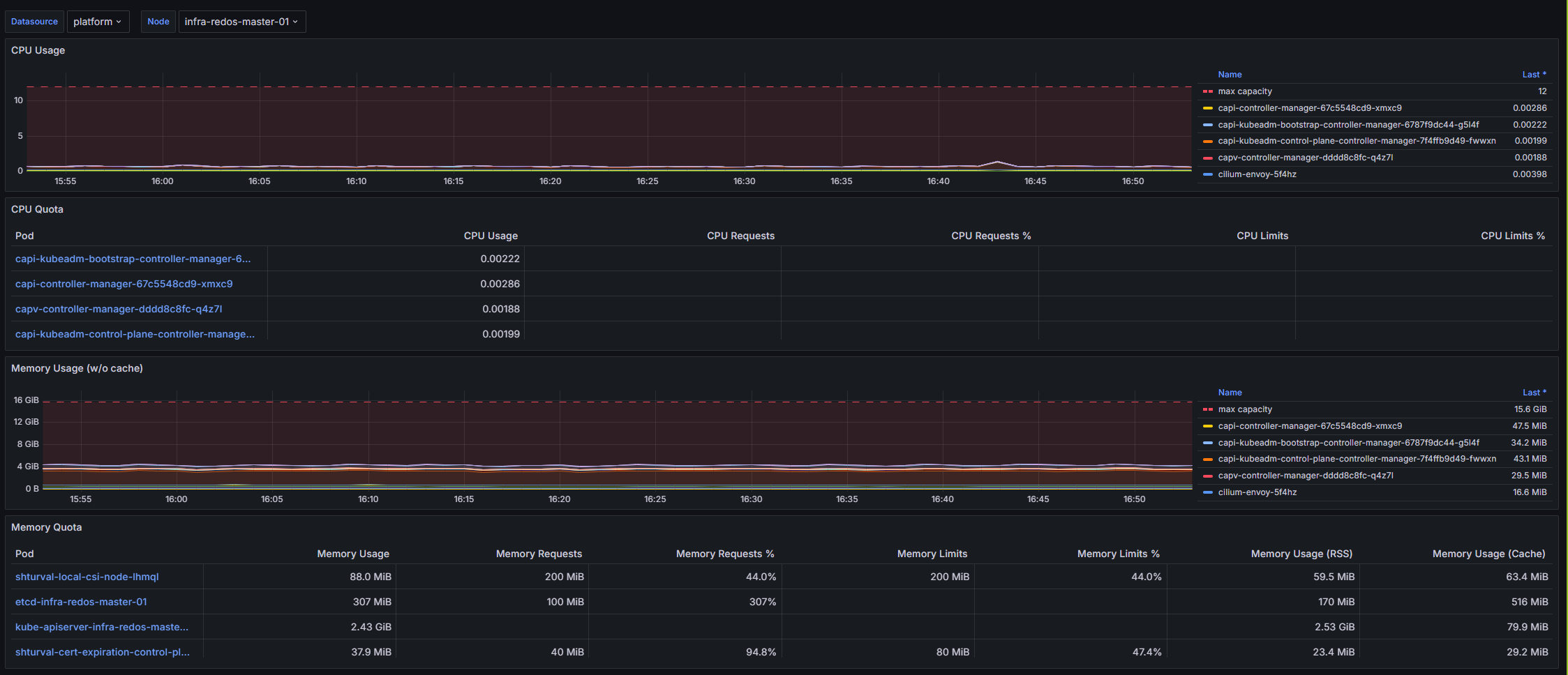
Структура дашборда
-
CPU Usage
- CPU Usage: Панель отображает динамику использования CPU в подах, показывая как текущую загрузку, так и максимальную доступную мощность для заданного узла.
-
CPU Quota
- CPU Quota: Таблица, отображающая квоты по CPU для подов, включая текущее использование, запрошенные ресурсы и лимиты.
-
Memory Usage (w/o cache)
- Memory Usage (w/o cache): Панель показывает использование памяти подами без учета кэша, а также максимальную доступную память для узла.
-
Memory Quota
- Memory Quota: Таблица, которая отображает использование памяти подами, запросы и лимиты на память, а также разбиение по RSS, кэшам и свопам для более глубокого анализа.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для мониторинга, в данном случае используется VM Agent.
- cluster: Настройка для выбора конкретного кластера Kubernetes, что позволяет фильтровать данные по нужному кластеру.
- node: Параметр для выбора узла в кластере, что также помогает в детальном анализе ресурсов на уровне узлов.
Kubernetes/Compute Resources/Pod
Описание
Данный дашборд предназначен для мониторинга ресурсов контейнеров в среде Kubernetes. Он предоставляет пользователям возможность отслеживать использование CPU и памяти, сетевые показатели, а также ввод-вывод операций на дисках. С помощью этого дашборда администраторы и разработчики могут быстро выявлять проблемы с производительностью и оптимизировать распределение ресурсов.
Скриншот
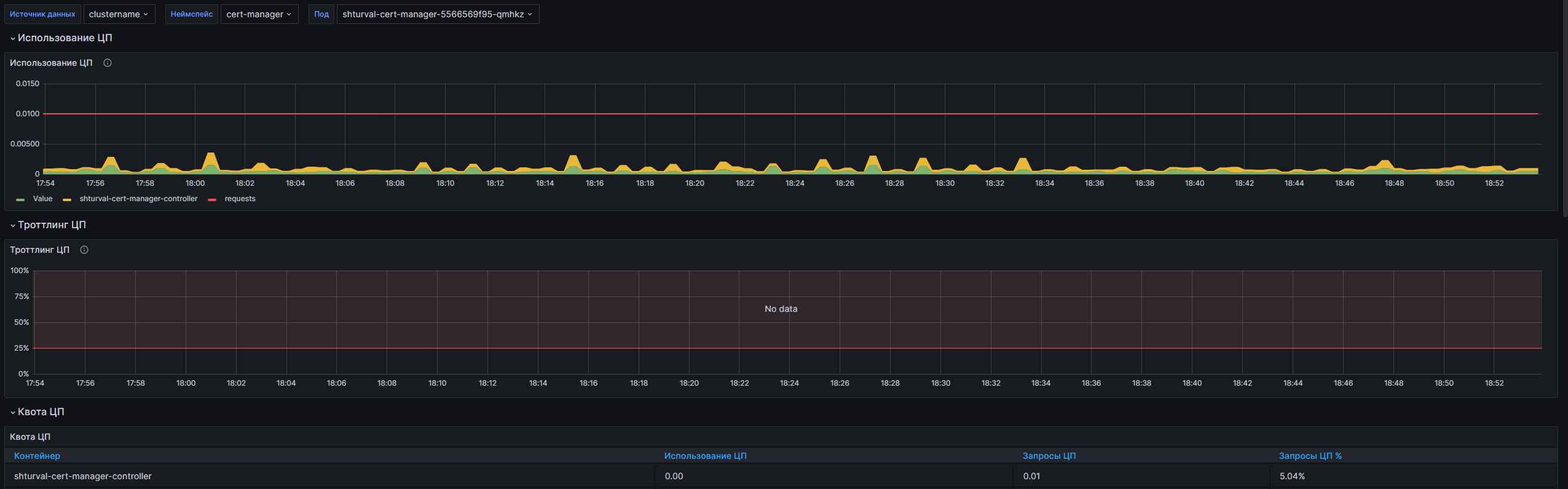
Структура дашборда
-
CPU Usage
- CPU Usage: Отображает использование CPU в контейнерах выбранного пода на основе показателей, полученных из VM Agent.
- CPU Throttling: Показывает throttling CPU, что позволяет отслеживать ограничения на использование CPU.
- CPU Quota: Таблица, отображающая текущие лимиты и запросы на использование CPU.
-
Memory Usage (WSS)
- Memory Usage (WSS): Отображает использование рабочей памяти в контейнерах выбранного пода.
- Memory Quota: Таблица, показывающая лимиты и запросы на использование памяти для контейнеров.
-
Network Traffic
- Receive Bandwidth: Отображает данные о входящей полосе пропускания для контейнеров.
- Transmit Bandwidth: Показывает данные о исходящей полосе пропускания для контейнеров.
- Rate of Received Packets: Отображает скорость получения пакетов.
- Rate of Transmitted Packets: Отображает скорость отправки пакетов.
- Rate of Received Packets Dropped: Показывает скорость получения потерянных пакетов.
- Rate of Transmitted Packets Dropped: Отображает скорость отправки потерянных пакетов.
-
I/O Operations
- IOPS (Pod): Отображает количество операций ввода-вывода в секунду (IOPS) для пода.
- ThroughPut (Pod): Показывает скорость передачи данных (ThroughPut) для пода.
- IOPS (Containers): Отображает количество операций ввода-вывода в секунду (IOPS) для контейнеров.
- ThroughPut (Containers): Показывает скорость передачи данных (ThroughPut) для контейнеров.
- Current Storage IO: Таблица, показывающая текущие операции ввода и вывода для контейнеров, включая количество прочитанных и записанных байтов.
Настраиваемые параметры
- datasource: Параметр для выбора источника данных, позволяет настраивать используемые метрики.
- cluster: Выбор кластера, для которого будут отображаться метрики.
- namespace: Выбор неймспейса Kubernetes, в котором происходит мониторинг.
- pod: Выбор конкретного пода для отображения его метрик.
Kubernetes/Compute Resources/Workload
Описание
Данный дашборд предназначен для мониторинга ресурсов вычислительной среды Kubernetes. Он предоставляет детальную информацию о нагрузках на CPU, памяти и сетевых интерфейсах, а также о квотах, выделенных под эти ресурсы. С помощью визуализации временных рядов и таблиц в реальном времени можно отслеживать производительность и эффективность использования ресурсов для различных workloads в кластере.
Скриншот
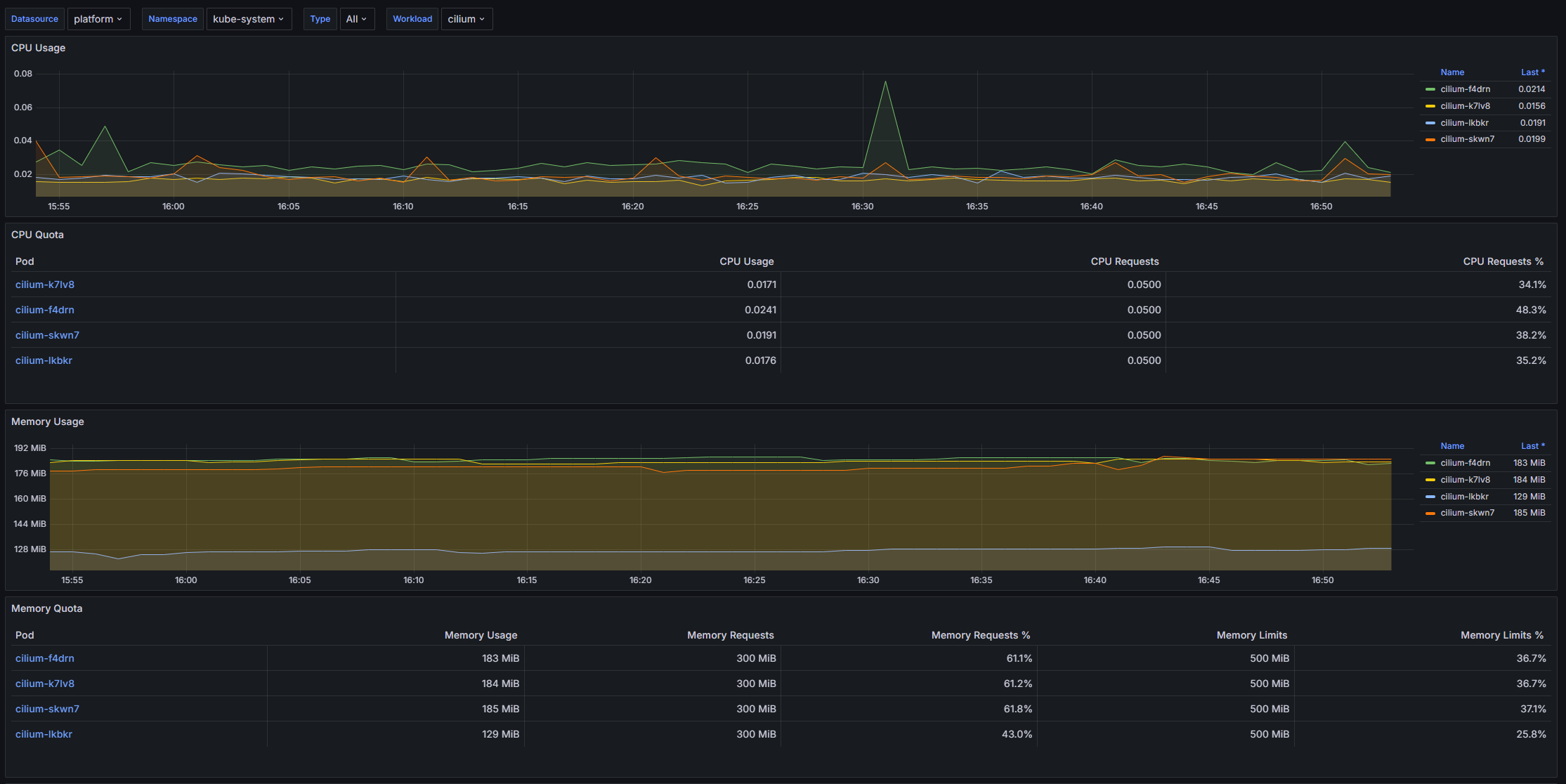
Структура дашборда
-
CPU Usage
- [CPU Usage]: Отображает использование CPU для каждого пода с помощью временных рядов.
-
CPU Quota
- [CPU Quota]: Позволяет увидеть информацию о квоте CPU, выделенной для подов в виде таблицы на основе различных метрик.
-
Memory Usage
- [Memory Usage]: Презентует текущее использование памяти подами в формате временных рядов.
-
Memory Quota
- [Memory Quota]: Демонстрирует квоты на использование памяти для подов с подробной информацией в виде таблицы.
-
Current Network Usage
- [Current Network Usage]: Отображает текущую сетевую активность подов с помощью таблицы, включая как входящий, так и исходящий трафик.
-
Receive Bandwidth
- [Receive Bandwidth]: Временной ряд, показывающий объем входящей сетевой активности для подов.
-
Transmit Bandwidth
- [Transmit Bandwidth]: Временной ряд, показывающий объем исходящей сетевой активности для подов.
-
Average Container Bandwidth by Pod: Received
- [Average Container Bandwidth by Pod: Received]: Среднее значение входящего трафика по подам в формате временных рядов.
-
Average Container Bandwidth by Pod: Transmitted
- [Average Container Bandwidth by Pod: Transmitted]: Среднее значение исходящего трафика по подам в формате временных рядов.
-
Rate of Received Packets
- [Rate of Received Packets]: Временной ряд, отображающий среднюю скорость получаемых сетевых пакетов.
-
Rate of Transmitted Packets
- [Rate of Transmitted Packets]: Временной ряд, отображающий среднюю скорость отправляемых сетевых пакетов.
-
Rate of Received Packets Dropped
- [Rate of Received Packets Dropped]: Временной ряд, показывающий количество потерянных входящих пакетов.
-
Rate of Transmitted Packets Dropped
- [Rate of Transmitted Packets Dropped]: Временной ряд, показывающий количество потерянных исходящих пакетов.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для отображения метрик.
- cluster: Позволяет выбрать конкретный кластер Kubernetes для мониторинга.
- namespace: Позволяет выбрать неймспейс, в котором происходит мониторинг.
- type: Позволяет выбрать тип workload для отображаемых метрик.
- workload: Позволяет выбрать конкретный workload в заданном неймспейсе и кластере.
Kubernetes/Планировщик
Описание
Данный дашборд предназначен для мониторинга работы планировщика Kubernetes. Он позволяет отслеживать ключевые метрики, связанные с процессом планирования, включая количество активных планировщиков, задержки при планировании и статистику HTTP-запросов к API Kube. Дашборд предоставляет графическую визуализацию данных, что помогает в быстром выявлении и решении проблем с производительностью в кластере Kubernetes.
Скриншот
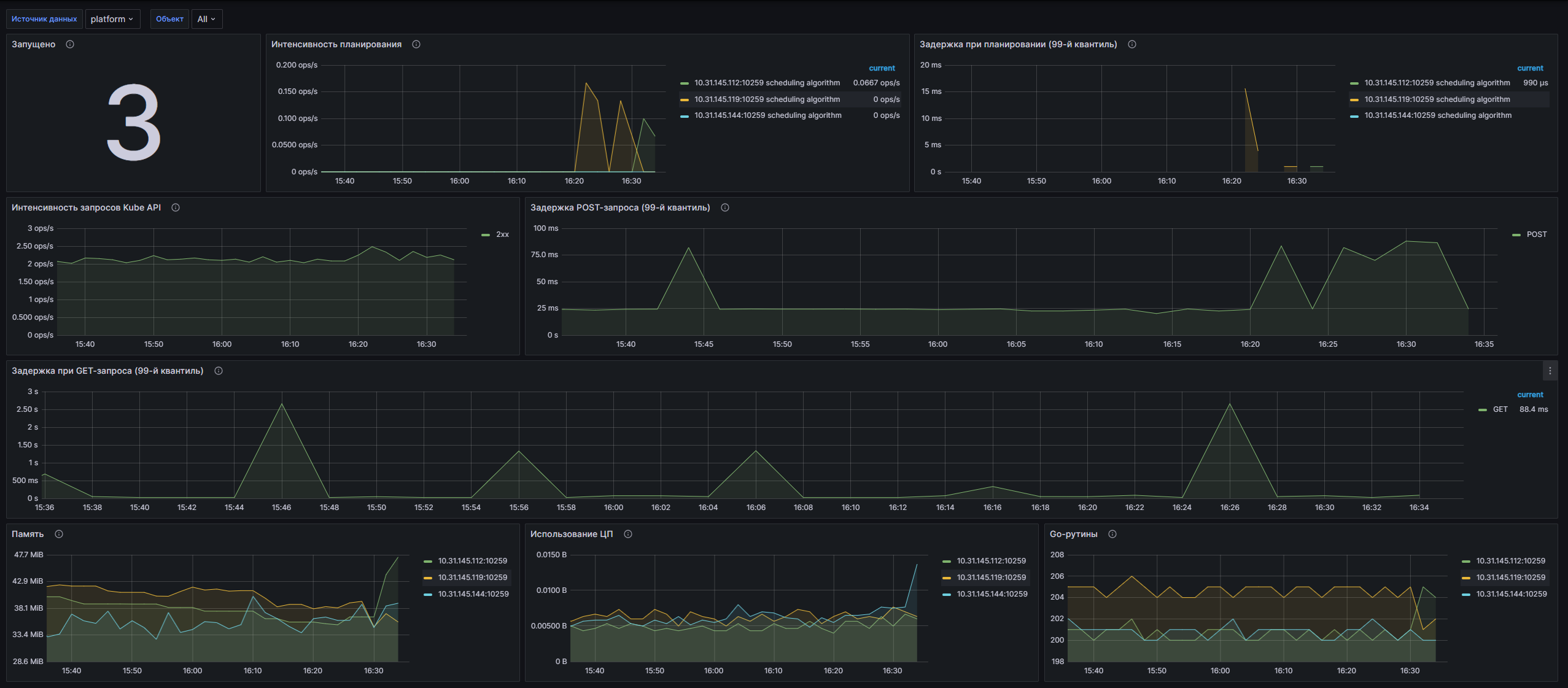
Структура дашборда
- Запущено: Количество запущенных планировщиков в кластере.
- Интенсивность планирования: Длительность различных стадий планирования в операциях в секунду.
- Задержка при планировании (99-й квартиль): 99-й квартиль времени задержки при планировании для различных стадий планирования, таких как e2e, binding, scheduling algorithm и volume.
- Интенсивность запросов Kube API: Количество HTTP-запросов, разделённых по коду статуса, методу и хосту.
- Задержка POST-запроса (99-й квартиль): 99-й квартиль задержки POST-запроса в секундах, сгруппированный по методам и URL.
- Задержка при GET-запросе (99-й квартиль): 99-й квартиль задержки GET-запроса в секундах, сгруппированный по методам и URL.
- Память: Объём памяти, используемой планировщиком, в байтах.
- Использование ЦП: Процессорное время, затрачиваемое на работающий планировщик.
- Go-рутины: Число GO-рутин, используемых планировщиком.
Настраиваемые параметры
- datasource: Источник данных для получения метрик (например, VM Agent).
- cluster: Название кластера, для которого нужно получать данные.
- service: Сервис, для которого будут фильтроваться метрики в зависимости от выбранного кластера.
Kubernetes/StatefulSet
Описание
Данный дашборд предназначен для мониторинга состояния StatefulSet в Kubernetes кластере. Он предоставляет наглядные метрики, позволяющие отслеживать использование ресурсов, таких как процессор, память и сетевые взаимодействия, а также показатели, связанные с репликацией StatefulSet. Используя дашборд, пользователи могут эффективно анализировать производительность и состояние приложений, работающих в режиме Stateful.
Скриншот

Структура дашборда
- Цп: Процессорное время, затраченное на работу со стейфул.
- Память: Объём памяти, используемый StatefulSet.
- Сеть: Количество байт, переданных и отправленных StatefulSet.
- Требуется реплик: Максимально возможное число реплик.
- Количество реплик этой версии: Максимально доступное количество реплик на данный момент.
- Наблюдаемая версия: Генерация, наблюдаемая контроллером развертывания.
- Генерация метаданных: Номер последовательности, представляющий конкретную генерацию желаемого состояния StatefulSet.
- Реплики: Специфические метрики по репликам, включая максимальное, созданное, готовое и обновленное число реплик.
Настраиваемые параметры
- datasource: Назначение - выбор источника данных для метрик мониторинга (например, VM Agent).
- cluster: Назначение - выбор кластера Kubernetes для мониторинга.
- namespace: Назначение - выбор неймспейса, в котором находится monitored StatefulSet.
- statefulset: Назначение - выбор конкретного StatefulSet для детального мониторинга.
Kubernetes/Views/Global
Описание
Данный дашборд предназначен для мониторинга Kubernetes кластеров и представляет собой современный “Глобальный обзор”, созданный для kube-VM Agent-stack и использующий последние функции Grafana. Он позволяет пользователям отслеживать ресурсы кластера, такие как использование процессора и памяти, количество узлов, подов и другие метрики, что обеспечивает эффективное управление ресурсами и поддержание стабильной работы приложений.
Скриншот
Структура дашборда
-
Обзор
- Global CPU Usage: Отображает данные о среднем использовании ЦП в процентовом соотношении, включая метрики по реальному использованию, запросам и лимитам ресурсов.
- Global RAM Usage: Представляет информацию об использовании оперативной памяти, включая реальные данные, запросы и лимиты памяти.
- Nodes: Панель показывает общее количество узлов в кластере.
- Kubernetes Resource Count: Визуализирует количество различных ресурсов Kubernetes, включая неймспейсы, запущенные контейнеры, поды, сервисы и другие.
- Namespaces: Отображает общее количество созданных неймспейсов в кластере.
- CPU Usage: Информирует о текущем использовании ЦП в кластере, включая реальные данные, запросы, лимиты и общее количество ядер ЦП.
- RAM Usage: Показатели использования оперативной памяти, включая реальные данные, запросы и лимиты, а также общее количество доступной памяти.
- Running Pods: Отображает текущее количество запущенных подов.
-
Ресурсы
- Cluster CPU Utilization: График, показывающий среднее использование ЦП на кластер в процентах.
- Cluster Memory Utilization: Выводит процентное использование оперативной памяти кластера.
- CPU Utilization by namespace: Оценка использования ЦП по отдельным неймспейсам.
- Memory Utilization by namespace: Отображает использование оперативной памяти по неймспейсам.
- CPU Utilization by node: График средних показателей использования ЦП для каждого узла.
- Memory Utilization by node: Визуализация использования оперативной памяти по узлам.
- CPU Throttled seconds by namespace: Отображает информацию о времени простоя ЦП по неймспейсам.
- CPU Core Throttled by node: Панель показывает, сколько времени ядра ЦП находились в состоянии ограничения.
-
Kubernetes
- Kubernetes Pods QoS classes: Отображает количество подов по классам качества обслуживания (QoS).
- Kubernetes Pods Status Reason: Информирует о причинах статусов подов.
- OOM Events by namespace: Отображает количество событий завершения работы из-за недостатка памяти по неймспейсам.
- Container Restarts by namespace: Информирует о количестве перезапусков контейнеров по неймспейсам.
-
Сеть
- Global Network Utilization by device: Отражает загрузку сети по устройствам, исключая виртуальные устройства.
- Network Saturation - Packets dropped: Показывает количество потерянных пакетов при получении и отправке данных.
- Network Received by namespace: Отображает получение и передачу данных по неймспейсам.
- Total Network Received (with all virtual devices) by node: Информация о полученных и переданных данных по узлам, включая все виртуальные устройства.
- Network Received (without loopback) by node: Показывает сетевую активность по узлам без учета петлевых устройств.
- Network Received (loopback only) by node: Визуализация сетевой активности только по петлевым устройствам на узлах.
Настраиваемые параметры
- datasource: Позволяет пользователю выбрать источник данных для получения метрик.
- role: Позволяет пользователю выбрать роль узлов для фильтрации метрик.
- node: Предоставляет возможность фильтровать метрики по конкретному узлу.
- resolution: Позволяет пользователю выбрать временное разрешение для отображаемых данных (1s, 15s, 30s, 1m, 3m, 5m).
Экспортер метрик
Экспортер метрик/Узлы
Описание
Данный дашборд предназначен для мониторинга метрик узлов, собранных с помощью экспортеров VM Agent, в частности, node-exporter. Он предоставляет пользователям возможность отслеживания ключевых показателей производительности и состояния системы, включая использование ЦП, памяти, дискового пространства и сетевых ресурсов. Информация отображается в виде графиков и статистических данных, позволяя быстро оценивать загрузку и производительность узлов.
Скриншот
Структура дашборда
- Использование ЦП: Отображает нагрузку на ЦП для выбранного узла в процентах.
- Средняя нагрузка: Показывает среднюю нагрузку на узел за различные временные интервалы (1 минута, 5 минут и 15 минут), а также количество логических ядер.
- Использование памяти: Имеет несколько графиков, отображающих использование памяти на узле, включая общую выделенную, буферизованную, кэшированную и свободную память.
- Использование памяти: Статистика для оперативной памяти, показывающая процент используемой памяти на узле.
- Ввод/вывод диска: Отображает объем памяти, использованной при операциях чтения и записи на диске, а также общее время, проведенное в операциях ввода/вывода.
- Использование дискового пространства: График, показывающий использование дискового пространства на устройстве, включая доступное и занятое пространство.
- Сеть: Получено: График, отображающий объем данных, полученных узлом от конкретного устройства.
- Сеть: Отправлено: График, показывающий объем данных, отправленных узлом конкретным устройствам.
Настраиваемые параметры
- datasource: Параметр, позволяющий выбрать источник данных для дашборда. В данном случае используется VM Agent.
- instance: Переменная, позволяющая пользователю выбрать конкретный экземпляр узла, для которого будут отображаться метрики, при этом данные извлекаются на основе значений меток.
Экспортер метрик/Метод USE/Кластер
Описание
Данный дашборд предназначен для мониторинга ресурсов кластера с использованием экспорта метрик при помощи node-exporter. Он позволяет визуализировать ключевые показатели производительности (KPI) системы, такие как использование процессора, памяти, сетевых ресурсов и операций ввода-вывода на дисках. Основная цель дашборда — обеспечить технических специалистов необходимой информацией для анализа состояния и производительности системы, что позволяет быстро идентифицировать и устранять узкие места.
Скриншот
Структура дашборда
-
ЦП
- Использование ЦП: Отображает процент процессорного времени, используемого экспортером метрик.
- Превышение нагрузки на одно ядро: Показывает процент нагрузки на экспортер метрик на ЦП.
-
Память
- Использование памяти: Визуализирует объем памяти, используемой экспортером метрик.
- Ошибки страниц памяти: Количество ошибок записи в память за последние 5 минут.
-
Сеть
- Использование сети (получено/отправлено): Отображает скорость передачи данных в байтах/секунду для отправленных и полученных байтов.
- Превышение нагрузок сети (сбрасывов при отправке/получении): Скорость сброшенных байтов на отправленных и полученных соединениях.
-
Ввод/вывод диска
- Использование Ввода/вывода диска: Показывает нагрузку операций ввода/вывода на диск.
- Превышение операций дискового ввода-вывода: Отображает взвешенную нагрузку операций ввода/вывода на основе времени.
-
Дисковое пространство
- Использование дискового пространства: Визуализирует процент занятого дискового пространства на файловых системах.
Настраиваемые параметры
- datasource: Настройка источника данных для отображения метрик.
- cluster: Выбор кластера для мониторинга, позволяющий фильтровать метрики по выбранному кластеру.
Экспортер метрик/Метод USE/Узел
Описание
Данный дашборд предназначен для мониторинга производительности узлов в кластере с использованием экспорта метрик через Node Exporter. Он позволяет отслеживать ключевые метрики нагрузки на процессоры, память, сеть и диски, что дает возможность анализировать состояние системных ресурсов и выявлять возможные проблемы с их производительностью.
Скриншот

Структура дашборда
-
ЦП
- Использование ЦП: Отображает процессорное время, использованное выбранным узлом Экспортера метрик.
- Превышение нагрузки на одно ядро: Мониторит нагрузку на ЦП для выбранного узла, показывая соотношение текущей нагрузки к полной загрузке ядра.
-
Память
- Использование памяти: Представляет объем памяти, использованный выбранным узлом Экспортера метрик.
- Ошибки страниц памяти: Измеряет количество ошибок памяти за последние 5 минут, что позволяет следить за состоянием управления памятью.
-
Сеть
- Использование сети (байт получено/отправлено): Показывает скорость получения и отправки байтов для выбранного узла Экспортера метрик.
- Превышение нагрузки сети (сбросов при отправке/получении): Отображает обращение к сетевым интерфейсам с зафиксированным количеством сбросов при отправке и получении данных.
-
Ввод/вывод диска
- Нагрузка на диск: Отображает нагрузку операций ввода/вывода на каждый диск в системе.
- Превышение операций дискового ввода-вывода: Мониторит весомую нагрузку операций ввода/вывода на диски, отображая значения в байтах.
-
Дисковое пространство
- Использование дискового пространства: Показывает процент занятого дискового пространства на выбранном устройстве.
Настраиваемые параметры
- datasource: Позволяет выбирать источник данных для отображения метрик, в данном случае используется VM Agent.
- cluster: Позволяет выбрать кластер для мониторинга, фильтруя по метке времени.
- instance: Позволяет выбрать конкретный экземпляр узла, для которого будут отображены метрики, что позволяет детализировать мониторинг на уровне отдельных узлов.
VictoriaMetrics
VictoriaMetrics/vmagent
Описание
Данный дашборд предоставляет обширный обзор работы VictoriaMetrics vmagent версии 1.102.0 и выше. Он предназначен для мониторинга различных метрик, связанных с процессом сбора и обработки данных, а также выявления ошибок и производительности компонентов системы. Основные возможности дашборда включают отображение статистики о числе извлеченных образцов, уровнях загрузки ресурсов, ошибках и задержках при записи данных, что позволяет оперативно реагировать на возможные проблемы в инфраструктуре.
Структура дашборда
-
Stats
-
Samples scraped/s: Отображает частоту извлечения образцов из настроенных источников. - Samples ingested/s: Показывает скорость обработки образцов в систему. - Targets scraped/s: Предоставляет информацию о количестве целевых метрик, извлекаемых в секунду. - Scrape targets: Позволяет увидеть общее количество всех настроенных целей для извлечения метрик и состояние их работы (включено или выключено). - Log errors (30m): Отображает количество ошибок, сгенерированных в логах за последние 30 минут. - Persistent queue size: Показывает размер ожидающих образцов в байтах, которые не были отправлены в удаленное хранилище. Увеличение этого значения может указывать на проблемы с подключением. - Uptime: Отображает время работы экземпляров системы.
-
Overview
- Samples rate ($instance): Отображает скорость ввода и вывода образцов, включая модели push и pull.
- Persistent queue size ($instance) to ($url): Показывает размер постоянной очереди ожидающих образцов, которые еще не были отправлены в удаленное хранилище, с акцентом на значения выше 2MB.
- Logging rate: Отображает частоту логирования сообщений по уровню серьезности.
- Requests rate ($instance): Показывает частоту запросов, обрабатываемых HTTP сервером vmagent.
- Errors rate ($instance): Показывает частоту ошибок для различных метрик, что может указывать на проблемы с сетью или форматированием данных.
-
Resource usage
- CPU ($instance): Отображает использование процессора экземпляра.
- RSS memory % usage ($instance): Процент использования резидентной памяти (RSS) экземпляра.
- Disk writes/reads ($instance): Показатели записи/чтения данных из хранилища.
- Network usage ($instance): Отображает скорость передачи данных, принимаемых и отправляемых vmagent.
- Open FDs usage % ($instance): Процент открытых дескрипторов файлов в ОС для каждого экземпляра.
- Goroutines ($instance): Показывает количество горутин, выполняемых в экземпляре.
- CPU spent on GC ($instance): Процент использования процессора, занимаемого сборщиком мусора.
- Threads ($instance): Отображает количество потоков, запущенных в экземпляре.
-
Troubleshooting
- Top 10 jobs by unique samples: Показывает 10 основных jobs по количеству новых зарегистрированных сериес за последние 5 минут.
- Top 10 instances by unique samples: Показывает 10 основных экземпляров по количеству новых зарегистрированных сериес за последние 5 минут.
- Persistent queue write saturation ($instance): Показатели насыщения очереди записи для экземпляра.
- Persistent queue read saturation ($instance): Показатели насыщения очереди чтения для экземпляра.
- Data blocks dropped ($instance) to ($url): Отображает частоту сброшенных блоков данных при получении
400 Bad Requestи409 Conflictответов от удаленного хранилища. - Non-default flags: Список нестандартных флагов конфигурации, установленных для jobs и экземпляров.
-
Scraping
- Scrape targets UP(By Type): Количество действующих целевых метрик по типам.
- Scrape targets DOWN(By Type): Количество недоступных целевых метрик по типам.
- Scrape rate ($instance): Число запросов на извлечение метрик в секунду.
- Scraped datapoints rate ($instance): Количество извлеченных данных в секунду.
- Scrape response size 0.99 quantile ($instance): 99-й процентиль размера ответов на запросы.
- Scrape duration 0.99 quantile ($instance): 99-й процентиль времени, необходимого для извлечения метрик.
- Scrape fails ($instance): Частота сбоев при извлечении метрик.
-
Ingestion
- Requests rate ($instance): Частота запросов на запись данных в ingestserver и HTTP сервер.
- Rows rate ($instance): Частота строк, загружаемых в vmagent через push-протоколы.
- Concurrent inserts ($instance): Количество одновременных вставок данных в систему.
- Error rate ($instance): Частота ошибок при записи в ingestserver и HTTP Сервер.
-
Streaming aggregation
- Matched samples ($instance): Количество образцов, соответствующих правилам агрегации.
- Ignored samples ($instance): Частота игнорируемых образцов во время агрегации.
- Produced samples ($instance): Количество созданных образцов по правилам агрегации.
- Flush timeouts ($instance): Показатели таймаутов, возникающих во время дедупликации или агрегации.
- Samples lag 0.99 quantile ($instance): Задержка между временными метками образцов внутри одной группы.
- Dedup flush duration 0.99 quantile ($instance): 99-й процентиль продолжительности очистки для агрегированных данных.
- Labels compressor ($instance): Размер компрессора меток по количеству записей.
-
Remote write
- Requests rate ($instance) to ($url): Частота запросов к удаленным конечным точкам.
- Bytes write rate ($instance): Глобальная скорость записи байтов через удаленные соединения.
- Retry rate ($instance) to ($url): Частота повторных попыток запросов к удаленным конечным точкам.
- Connections ($instance): Текущее количество установленных соединений с удаленными конечными точками.
- Hourly series limit: Использование предела уникальных серий за час.
- Remote write connection saturation ($instance): Показатели насыщения соединений с удаленными хранилищами.
- Daily series limit: Использование предела уникальных серий за день.
-
Drilldown
- CPU usage ($instance): Использование процессора экземпляра.
- RSS memory usage ($instance): Использование резидентной памяти экземпляра.
- Persistent queue size ($instance) to ($url): Размер постоянной очереди ожидающих образцов.
- Samples rate ($instance): Скорость ввода и вывода образцов для экземпляра.
- Disk writes/reads ($instance): Чтение/запись данных для экземпляра.
Настраиваемые параметры
- ds: Назначение и описание источника данных.
- job: Переменная для выбора конкретной работы или задачи.
- instance: Переменная для выбора конкретного экземпляра.
- url: Переменная для выбора URL для удаленной записи данных.
- adhoc: Используется для создания временных переменных.
VictoriaMetrics/vmalert
Описание
Данный дашборд предназначен для мониторинга системы управления оповещениями vmalert, которая входит в состав VictoriaMetrics. Он предоставляет обзор состояния и производительности различных правил оповещения и записи, а также ресурсных метрик, таких как использование памяти и процессоров. Дашборд позволяет пользователю отслеживать ошибки в выполнении правил, а также эффективность отправки оповещений в Alertmanager, что критически важно для обеспечения корректной работы системы оповещений.
Структура дашборда
-
Stats
- Config update: Отображает статус последнего обновления конфигурации. Значение “Not Ok” указывает на наличие ошибок при обновлении.
- Alerting rules: Показывает общее количество загруженных правил оповещения для выбранных экземпляров и групп.
- Recording rules: Отражает общее количество загруженных правил записи для выбранных экземпляров и групп.
- Errors: Отображает общее количество ошибок, возникших в результате выполнения правил оповещения и записи.
- No data errors: Отображает количество правил записи, которые не выдают данные, что может указывать на ошибочную конфигурацию.
- Uptime: Показывает статус доступности экземпляров vmalert.
-
Overview ($instance)
- Alerts fired total ($instance): Отображает общее количество сработавших оповещений по каждой работе.
- Top $topk groups avg evaluation duration ($group): Показывает топ $topk групп по времени выполнения оценок.
- Rules execution rate ($instance): Отображает скорость выполнения запросов кDatasource.
- Rules execution errors ($instance): Отображает частоту ошибок при выполнении правил.
- Non-default flags: Показывает использование нестандартных флагов в системе.
- Missed evaluations ($instance): Отображает количество пропущенных оценок, что может вызвать проблемы с уведомлениями.
-
Resource usage
- Memory usage % ($instance): Процент использования памяти.
- Memory usage ($instance): Объем используемой памяти.
- CPU usage %($instance): Процент использования процессора.
- CPU usage ($instance): Максимальное количество используемых ядер.
- Open FDs usage % ($instance): Процент открытых дескрипторов файлов в операционной системе.
- Goroutines ($instance): Общее количество активных горутин.
-
Alerting rules ($instance)
- Top $topk active alerts ($group): Топ $topk активных правил срабатывания оповещений.
- Errors ($group): Отображает события, когда выполнение правил привело к ошибкам.
- Pending ($group): Количество текущих ожидающих правил оповещения.
- Errors rate to Alertmanager: Частота ошибок при отправке оповещений в Alertmanager.
- Requests rate to Alertmanager by job ($group): Количество оповещений, отправляемых в Alertmanager.
-
Recording rules ($instance)
- Top $topk rules by produced samples ($group): Топ $topk правил, генерирующих наибольшее количество образцов.
- Rules with 0 produced samples ($group): Показывает правила, которые не генерируют образцы.
- Errors ($group): Отображает ошибки, возникшие во время выполнения правил записи.
-
Remote write
- Datapoints send rate ($instance): Скорость отправки данных через удаленные подключения.
- Datapoints drop rate ($instance): Количество точек данных, отбрасываемых при отправке.
- Connections ($instance): Текучее количество установленных соединений с удаленными конечными точками.
- Bytes write rate ($instance): Глобальная скорость записи байтов через удаленные подключения.
Настраиваемые параметры
- ds: Параметр для выбора источника данных, который будет использоваться для метрик.
- job: Параметр для выбора конкретной работы, чтобы отфильтровать метрики.
- instance: Позволяет выбрать экземпляр, который будет использоваться для отображения метрик.
- group: Позволяет выбрать группу, чтобы отобразить метрики только для определенных групп.
- topk: Определяет количество топовых метрик, отображаемых в некоторых панелях.
- adhoc: Параметр для создания произвольных переменных для фильтрации данных.
VictoriaMetrics/vmauth
Описание
Данный дашборд предоставляет обзор работы системы аутентификации для VictoriaMetrics (vmauth) версии 1.80.0 и выше. Он предназначен для мониторинга ключевых метрик, связанных с работой и эффективностью системы аутентификации. Интеграция с VM Agent позволяет отслеживать состояние и производительность, обеспечивая возможность настраивания различных параметров для более детального анализа.
Структура дашборда
-
Stats
- Uptime: Отображает суммарное время работы, позволяя видеть зависимость от заданного интервала.
- Config update: Показывает успешность последнего обновления конфигурации, где “Not Ok” указывает на ошибку при обновлении.
- Requests rate: Отображает скорость обработки запросов в системе.
- Users count: Показывает общее количество пользователей, определенных в конфигурационном файле.
- Errors rate: Отображает частоту ошибок в обработке запросов.
- Version: Выводит таблицу с версиями приложения.
-
Overview
- Requests rate: Временной ряд, отображающий скорость поступления запросов с разбивкой по пользователям.
- User concurrent requests usage: Отображает процент использования разрешенных параллельных запросов по пользователям.
- Requests rejected rate: Отображает скорость отклоненных запросов с указанием причины.
- Concurrent limit reached: Отображает случаи, когда количество параллельных соединений достигло лимита, с рекомендациями по действиям.
- User requests duration: Показывает продолжительность запросов пользователей по квантилям.
-
Resource usage
- RSS memory % usage ($instance): Процент использования резидентной памяти, критичный для производительности.
- CPU % usage ($instance): Процент использования CPU, показывающий загруженность системы.
- Memory usage ($instance): Различные показатели использования памяти.
- CPU ($instance): Использование CPU и доступные лимиты.
- TCP connections ($instance): Количество активных TCP соединений.
- TCP connections rate ($instance): Скорость нового подключения по TCP.
- Open FDs ($instance): Процент открытых файловых дескрипторов по отношению к установленному лимиту.
- Goroutines ($instance): Отображает количество горутин в системе.
- Threads ($instance): Отображает количество потоков.
-
Troubleshooting
- Non-default flags: Таблица, отображающая флаги, не установленные по умолчанию.
- Log errors: Временной ряд, показывающий количество ошибок и предупреждений в логах, что может указывать на проблемы с соединением или неправильную конфигурацию.
Настраиваемые параметры
- ds: Параметр для выбора источника данных, установленного на VM Agent.
- job: Позволяет пользователю выбрать конкретную задачу из списка рабочих версий vmauth.
- instance: Предоставляет возможность выбрать конкретный экземпляр рабочей задачи для мониторинга.
- user: Позволяет выбрать пользователя из списка для дальнейшего анализа запросов.
- adhoc: Параметр для создания произвольных запросов к данным.
VictoriaMetrics/cluster
Описание
Данный дашборд предназначен для мониторинга кластеров VictoriaMetrics версии 1.86.0 и выше. Он предоставляет обширные возможности для отслеживания производительности и состояния компонентов кластера, включая статистику о потреблении ресурсов, частоту запросов, метрики ингрессии данных и уровень ошибок. Дашборд поддерживает гибкость в выборе источников данных, что способствует глубинному анализу работы системы.
Структура дашборда
-
Stats
- Total datapoints: Отображает общее количество данных, хранящихся в системе.
- Ingestion rate: Показывает скорость поступления данных, включая коэффициент репликации.
- Read requests: Отображает частоту HTTP-запросов на чтение.
- Available CPU: Показывает общее количество доступных процессоров для всех компонентов VictoriaMetrics.
- Active series: Отображает количество активных временных рядов с новыми данными за последний час.
- Disk space usage: Общая информация о занимаемом дисковом пространстве.
- Bytes per point: Среднее значение дискового пространства, занимаемого одним временным рядом.
- Available memory: Общее количество доступной оперативной памяти для всех компонентов VictoriaMetrics.
- Uptime ($job): Временной ряд, показывающий время работы компонента.
-
Overview
- Datapoints ingestion rate ($instance): Показывает количество данных, поступающих в кластер в секунду.
- Requests rate ($instance): Кавказ запрашивает различные метрики от VM, включая команды на вставку и чтение.
- Active time series ($instance): Отображает количество активных временных рядов за последний час.
- Query duration 0.99 quantile ($instance): Время обработки запросов на чтение.
- Requests error rate ($instance): Уровень ошибок при выполнении запросов.
- Logging rate: Отображает частоту логирования сообщений по уровням.
-
Resource usage ($job)
- RSS memory % usage ($instance): Условие использования RSS (резервной) памяти.
- RSS anonymous memory % usage ($instance): Использование анонимной памяти.
- CPU ($instance): Использование процессора.
- Disk writes/reads ($instance): Данные по чтениям и записям на диск.
- Open FDs usage % ($instance): Процент используемых дескрипторов файлов.
- Disk write/read calls ($instance): Количество системных вызовов на чтение/запись.
- Goroutines ($instance): Использование горутин в приложении.
- TCP connections ($instance): Текущее количество TCP-соединений.
- Threads ($instance): Текущее количество потоков приложения.
-
Troubleshooting
- Churn rate ($instance): Частота создания новых рядов за последние 24 часа.
- Slow inserts: Процент медленных вставок относительно общего числа вставок.
- Storage in readonly status for vminsert ($instance): Проверка статуса доступности vmstorage.
- Slow queries % ($instance): Процент медленных запросов.
- Assisted merges ($instance): Количество ассистированных слияний данных в хранилище.
- Labels limit exceeded ($instance): Число метрик с превышением лимита меток.
- Cache usage % by type ($instance): Использование кэша по типам.
- Cache miss ratio ($instance): Отношение пропусков кэша.
-
Interconnection ($job)
- Rows ($instance): Количество строк, переданных и полученных.
- RPC errors ($instance): Ошибки связи между узлами.
- Rows ($instance) rerouted to: Количество переадресованных строк.
- Pending: Краткое состояние текущих активных запросов.
-
vmstorage ($instance)
- Ingestion rate ($instance): Скорость поступления данных в узлы хранилища.
- Storage full ETA ($instance): Оценка времени достижения 100% использования диска.
- CPU usage % ($instance): Использование процессора для компонента хранилища.
- Memory usage % ($instance): Использование оперативной памяти для компонентов хранилища.
-
vmselect ($instance)
- Requests rate ($instance): Частота запросов, принятых узлами vmselect.
- Concurrent selects ($instance): Текущие и максимальные количество параллельных запросов.
-
vminsert ($instance)
- Requests rate ($instance): Частота запросов для узлов vminsert.
- Concurrent inserts ($instance): Количество параллельных вставок.
-
Drilldown
- RSS memory usage ($instance): Использование памяти (резервной).
- Storage full ETA ($instance): Приблизительное время, необходимое для достижения 100% дискового пространства.
Настраиваемые параметры
- **ds**: Определяет источник данных для запросов.
- **job**: Позволяет выбрать заданную работу внутри кластера.
- **job_insert**: Фильтрует выборку данных для операций вставки.
- **job_select**: Фильтрует выборку данных для операций выборки.
- **job_storage**: Фильтрует выборку данных для операций с хранилищем.
- **instance**: Позволяет выбирать конкретные экземпляры для мониторинга.
- **adhoc**: Позволяет использовать произвольные запросы без предварительных определений.
VictoriaMetrics/Cluster Per Tenant Statistic
Описание
Данный дашборд предоставляет обширный обзор показателей кластеров VictoriaMetrics версии 1.56.0 и выше, позволяя пользователям отслеживать и анализировать данные по каждому арендатору. Основные возможности дашборда включают мониторинг скорости инжекции данных, частоты запросов чтения, активности временных рядов и использования дискового пространства. Это является важным инструментом для выявления узких мест, оптимизации работы кластера и поддержки принятия оперативных решений в области хранения и обработки данных.
Структура дашборда
-
Statistics
- Datapoints ingestion rate: Отображает количество точек данных, вставляемых в хранилище в секунду с разбивкой по accountID и projectID.
- Read query rate: Показывает частоту запросов, принимаемых узлами vmselect для каждого арендатора.
- Active time series: Отображает количество активных временных рядов с новыми данными, вставленными в течение последнего часа. Высокое значение может указывать на замедление процесса инжекции данных.
- Time spent on queries, seconds: Время, потраченное на выполнение запросов для каждого арендатора в секунду.
- Disk space usage (datapoints only): Показывает объем дискового пространства, занимаемого только точками данных. Нет возможности различить статистику по арендаторам для indexdb.
- New series over 24h: Количество новых временных рядов, созданных за последние 24 часа.
-
Billing
- Ingestion Rate Top 5, by account id: Топ-5 аккаунтов по скорости инжекции данных.
- Read query rate, Top 5, by account id: Топ-5 аккаунтов по частоте запросов чтения.
- Time spent on queries, seconds, Top 5, by account id: Топ-5 аккаунтов по времени, проведенному на запросах.
- Active time series, Top 5, by account id: Топ-5 аккаунтов по количеству активных временных рядов.
- Disk space usage, Top 5, by account id: Топ-5 аккаунтов по использованию дискового пространства.
- New series over 24h, Top 5, by account id: Топ-5 аккаунтов по количеству новых временных рядов, созданных за последние 24 часа.
Настраиваемые параметры
- ds: Позволяет выбрать источник данных (datasource) для запросов.
- account: Дает возможность фильтровать данные по идентификатору аккаунта. Пользователь может выбрать один или несколько аккаунтов для анализа.
- project: Позволяет фильтровать данные по идентификатору проекта для выбранного аккаунта. Опция включает возможность выбора нескольких проектов.
- adhoc: Предоставляет возможность создания произвольных фильтров для динамического анализа данных.
VictoriaMetrics/operator
Описание
Данный дашборд предоставляет обзор работы оператора VictoriaMetrics версии 0.25.0 и выше. Он позволяет отслеживать ключевые метрики производительности и состояния, относящиеся к управлению объектами в кластере Kubernetes. С помощью этого дашборда пользователи могут быстро оценить общее состояние системы, а также выявить и диагностировать проблемы на уровне контроллеров и ресурсов.
Структура дашборда
-
Overview
- Version: Текстовая панель, отображающая текущую версию оператора.
- CRD Objects count by controller: Панель типа “stat”, показывающая количество объектов в кластере Kubernetes для каждого контроллера.
- Uptime: Панель типа “stat”, отображающая время работы системы на каждом экземпляре.
- Reconciliation rate by controller: Панель типа “timeseries”, отображающая скорость выполнения операций согласования для каждого контроллера.
- Log message rate: Панель типа “timeseries”, показывающая частоту логирования сообщений в зависимости от уровня логирования.
-
Troubleshooting
- reconcile errors by controller: Панель типа “timeseries”, отображающая ошибки согласования по контроллерам. Ненулевые значения указывают на проблемы с определением объектов CR или с подключением к API Kubernetes.
- throttled reconcilation events: Панель типа “timeseries”, показывающая количество событий согласования, которые были ограничены. Это помогает снизить нагрузку на кластер Kubernetes и повысить производительность оператора.
- Working queue depth: Панель типа “timeseries”, отображающая количество объектов, ожидающих обработки в очереди. Ненулевые значения указывают на трудности оператора в обработке изменений объектов CR.
- Reconcilation latency by controller: Панель типа “timeseries”, показывающая задержку согласования для каждого контроллера. Высокая задержка может указывать на проблемы с производительностью оператора.
-
resources
- Memory usage ($instance): Панель типа “timeseries”, показывающая использование памяти для каждого экземпляра, включая запрашиваемую системную память, память, находящуюся в использовании, и резидентную память.
- CPU ($instance): Панель типа “timeseries”, отображающая использование CPU для каждого экземпляра.
- Goroutines ($instance): Панель типа “timeseries”, отображающая количество горутин для каждого экземпляра.
- GC duration ($instance): Панель типа “timeseries”, показывающая среднюю длительность сборки мусора для каждого экземпляра.
Настраиваемые параметры
- ds: Параметр, позволяющий выбирать источник данных (datasource) для отображения метрик.
- job: Параметр, позволяющий фильтровать метрики по заданной задаче (job).
- instance: Параметр, который позволяет выбирать конкретный экземпляр для отображения метрик.
- version: Параметр, дающий возможность выбирать версию приложения для анализа метрик.