Конфигурация ClusterAPI
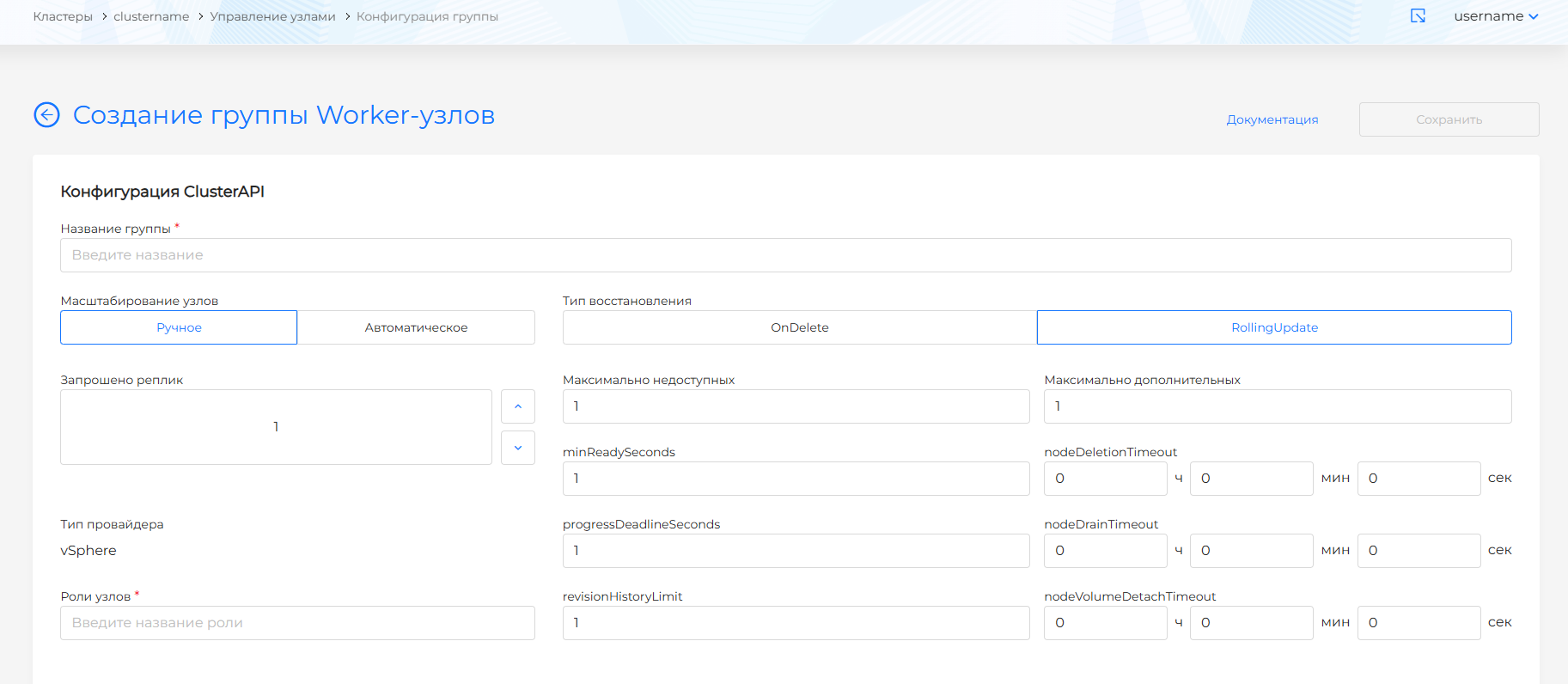
При создании новой группы в блоке Конфигурация ClusterAPI есть возможность указать параметры ClusterAPI, MachineDeployment. Название группы формируется по правилу: название кластера с постфиксом в виде запрашиваемого названия группы.
Скриншот создания группы
При просмотре конфигурации группы на вкладке Конфигурация ClusterAPI вы можете изменить параметры ClusterAPI, MachineDeployment.
Скриншот конфигурации группы узлов
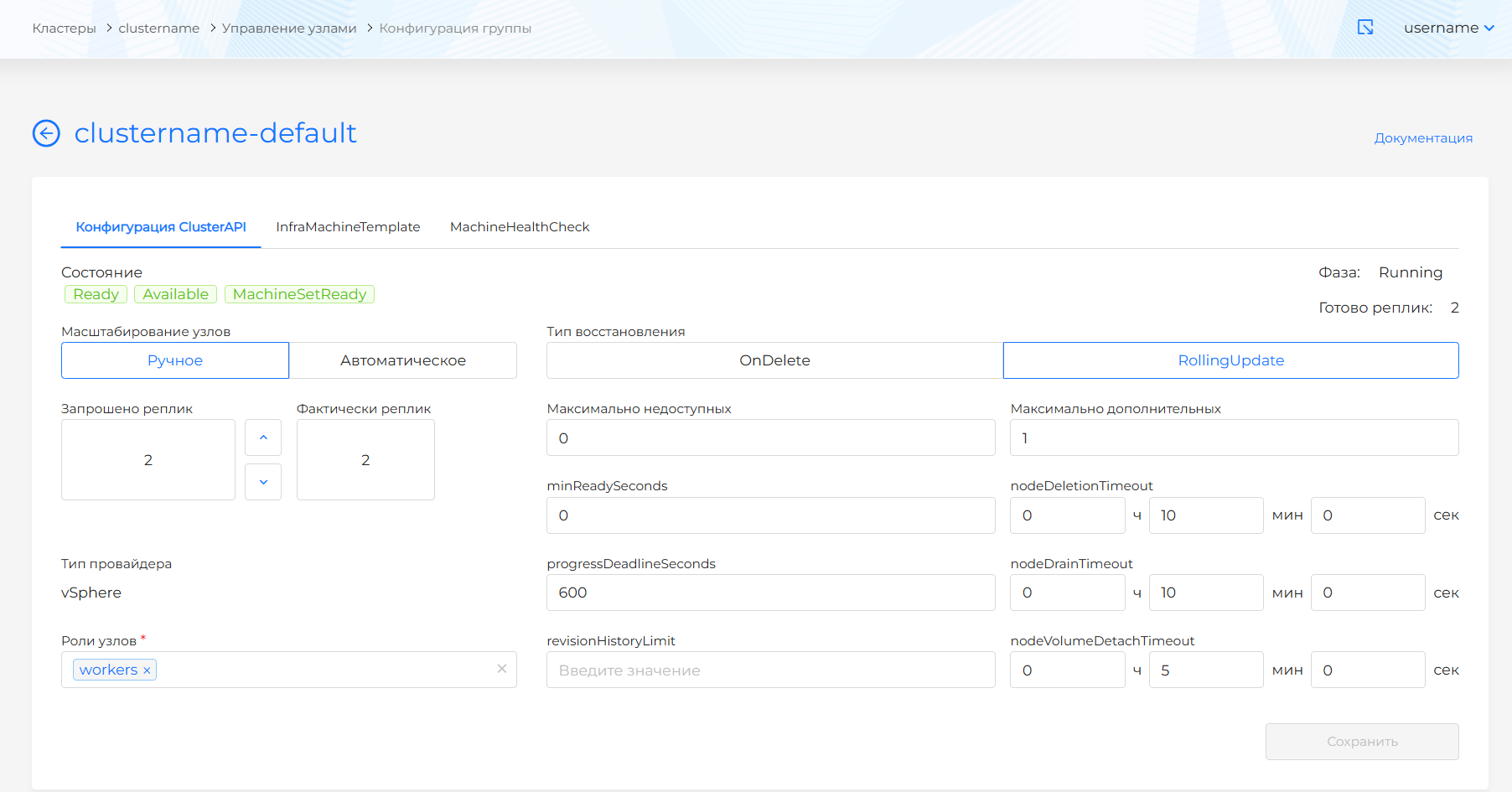
- Выбор способа масштабирования узлов в группе:
- Ручное. При этом доступно директивное указание запрашиваемого количества узлов в группе: в поле “Запрошено реплик” укажите желаемое количество узлов в группе.
- Автоматическое. При этом доступно указание диапазона узлов для группы: укажите минимальное и максимальное количества узлов в группе. Количество узлов будет увеличиваться или уменьшаться в пределах заданного диапазона в зависимости от нагрузки. Подробнее об автоматическом масштабировании в разделе Autoscaler в ClusterAPI.
При автоматическом масштабировании минимально количество узлов может быть 2. В графическом интерфейсе ограничена возможность задать менее 2-х реплик.
Скриншот

Обратите внимание!
- В случае необходимости выведения конкретного хоста с провайдером Shturval v2 из группы узлов воспользуйтесь инструкцией.
- В случае превышения лимита по количеству Worker-узлов согласно лицензии, на всех страницах графического интерфейса отобразится уведомление с просьбой обратится к вендору для изменения пакета лицензии.
- Тип восстановления:
- OnDelete. При наличии изменений старые узлы удаляются и поднимаются новые.
- RollingUpdate. При наличии изменений новые узлы создаются с последовательной заменой старых. Рекомендуемый вариант. При этом требуется указать максимальное количество недоступных и дополнительных узлов.
- minReadySeconds - минимальное количество секунд, в течение которых узел для созданной машины должен быть готов, прежде чем считать реплику доступной. По умолчанию 0 (машина будет считаться доступной, как только узел будет готов).
- progressDeadlineSeconds - максимальное время в секундах, необходимое для выполнения развертывания, прежде чем оно будет считаться неудавшимся. Контроллер развертывания продолжит обработку неудавшихся развертываний. В состоянии Cluster API будет отображено условие с причиной ProgressDeadlineExceeded. По умолчанию 600 с.
- revisionHistoryLimit - количество MachineSets, которые нужно сохранить для возможности отката. По умолчанию 1.
- nodeDeletionTimeout: определяет, как долго capi-controller-manager будет пытаться удалить узел, после того как ресурс Machine будет помечен на удаление. При значении 0 попытки удаления будут повторяться бесконечно. Если значение не указано, будет использовано значение по умолчанию (10 секунд) для этого свойства ресурса Machine.
- nodeDrainTimeout - это общее количество времени, которое контроллер потратит на слив/освобождение узла. Значение по умолчанию равно 0, что означает, время ожидания освобождения узла не ограниченно по времени и может ожидать сколько угодно. ПРИМЕЧАНИЕ: NodeDrainTimeout отличается от
kubectl drain --timeout. - nodeVolumeDetachTimeout - это общее количество времени, которое контроллер потратит на ожидание отсоединения всех томов (volumes). Значение по умолчанию равно 0, это означает, что тома (volumes) будут ожидать отсоединения без какого-либо ограничения по времени и может ожидать сколько угодно. По умолчанию для ресурса Machine установлено значение 10 секунд.
- роли: укажите через запятую роли, которые будут назначены группе. Каждая назначенная роль будет прописана в после “/” лейбл узла
node-role.kubernetes.io/.