С версии 2.9.x
Обновление клиентского кластера
Если в клиентском кластере был включен “Модуль локального сбора метрик”, а в кластере управления “Модуль мониторинга. Компонент централизованного сбора метрик”, то после завершения обновления клиентского кластера с версии 2.9.Х на 2.10.0 и выше необходимо выполнить действия:
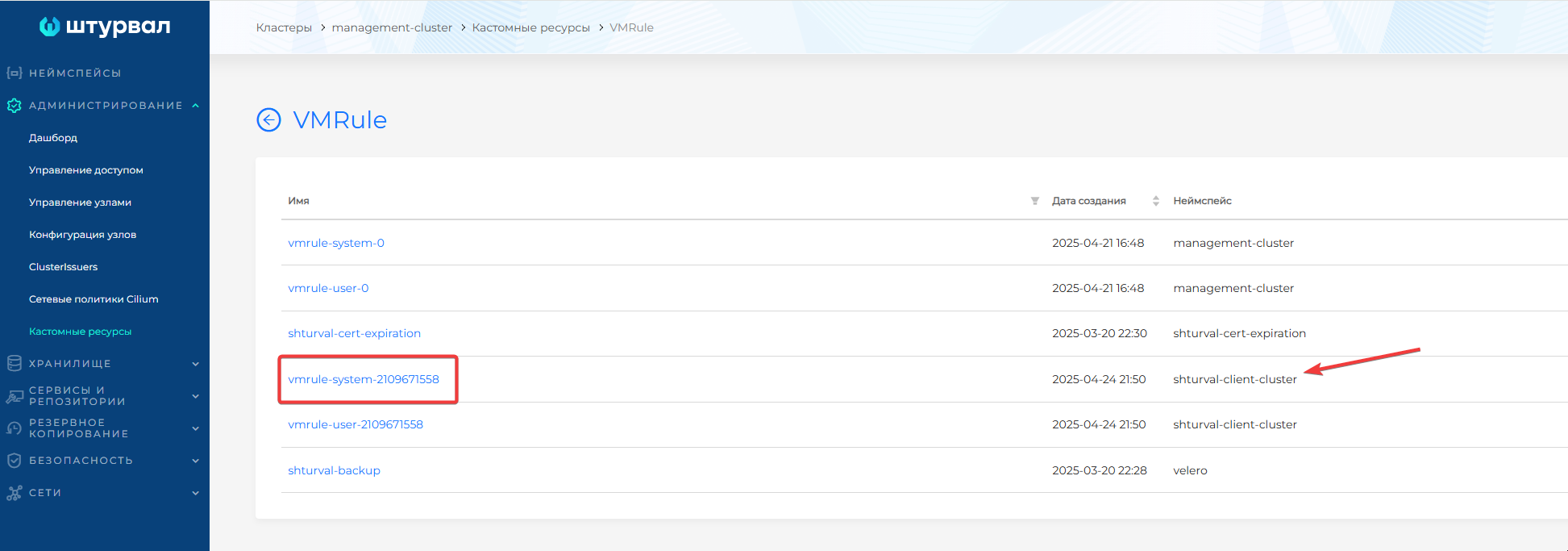
- В графическом интерфейсе кластера управления перейдите на страницу Кастомные ресурсы раздела Администрирование. Найдите и откройте API-группу
operator.victoriametrics.com; - Перейдите в список объектов типа
VMRule; - В таблице найдите VMRule с префиксом
systemв неймспейсе с именем клиентского кластера;
Скриншот
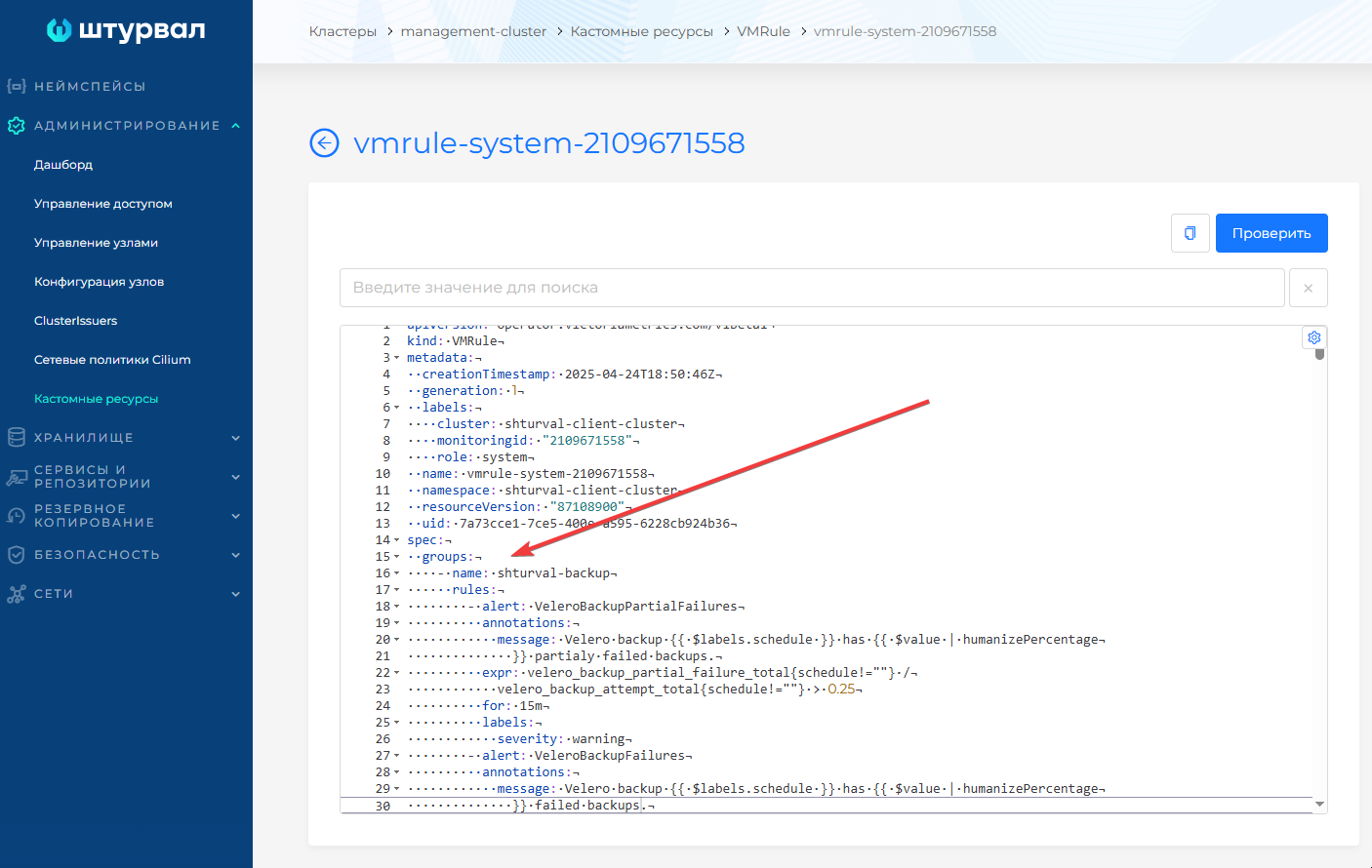
- Перейдите в манифест VMRule с префиксом
systemв неймспейсе с именем клиентского кластера; - Замените блок
specна содержимое, указанное в блоке “Обновленная часть spec”. Выполните проверку, нажав кнопку Проверить, затем сохраните изменения:
Скриншот
Обновленная часть spec
spec:
groups:
- name: shturval-backup
rules:
- alert: VeleroBackupPartialFailures
annotations:
message: >-
Velero backup {{ $labels.schedule }} has {{ $value |
humanizePercentage }} partialy failed backups.
expr: >-
velero_backup_partial_failure_total{schedule!=""} /
velero_backup_attempt_total{schedule!=""} > 0.25
for: 15m
labels:
severity: warning
- alert: VeleroBackupFailures
annotations:
message: >-
Velero backup {{ $labels.schedule }} has {{ $value |
humanizePercentage }} failed backups.
expr: >-
velero_backup_failure_total{schedule!=""} /
velero_backup_attempt_total{schedule!=""} > 0.25
for: 15m
labels:
severity: warning
- name: x509-certificate-exporter.rules
rules:
- alert: X509ExporterReadErrors
annotations:
description: >-
Over the last 15 minutes, this x509-certificate-exporter instance
has experienced errors reading certificate files or querying the
Kubernetes API. This could be caused by a misconfiguration if
triggered when the exporter starts.
summary: Increasing read errors for x509-certificate-exporter
expr: delta(x509_read_errors[15m]) > 0
for: 5m
labels:
severity: warning
- alert: CertificateError
annotations:
description: >-
Certificate could not be decoded {{if $labels.secret_name }}in
Kubernetes secret "{{ $labels.secret_namespace }}/{{
$labels.secret_name }}"{{else}}at location "{{ $labels.filepath
}}"{{end}}
summary: Certificate cannot be decoded
expr: x509_cert_error > 0
for: 15m
labels:
severity: warning
- alert: CertificateRenewal
annotations:
description: >-
Certificate for "{{ $labels.subject_CN }}" should be renewed {{if
$labels.secret_name }}in Kubernetes secret "{{
$labels.secret_namespace }}/{{ $labels.secret_name }}"{{else}}at
location "{{ $labels.filepath }}"{{end}}
summary: Certificate should be renewed
expr: (x509_cert_not_after - time()) < (28 * 86400)
for: 15m
labels:
severity: warning
- alert: CertificateExpiration
annotations:
description: >-
Certificate for "{{ $labels.subject_CN }}" is about to expire
after {{ humanizeDuration $value }} {{if $labels.secret_name }}in
Kubernetes secret "{{ $labels.secret_namespace }}/{{
$labels.secret_name }}"{{else}}at location "{{ $labels.filepath
}}"{{end}}
summary: Certificate is about to expire
expr: (x509_cert_not_after - time()) < (14 * 86400)
for: 15m
labels:
severity: critical
- name: alertmanager.rules
rules:
- alert: AlertmanagerFailedReload
annotations:
description: >-
Configuration has failed to load for {{ $labels.namespace }}/{{
$labels.pod}}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerfailedreload
summary: Reloading an Alertmanager configuration has failed.
expr: >-
# Without max_over_time, failed scrapes could create false
negatives, see
#
https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0
for details.
max_over_time(alertmanager_config_last_reload_successful{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m])
== 0
for: 10m
labels:
severity: critical
- alert: AlertmanagerMembersInconsistent
annotations:
description: >-
Alertmanager {{ $labels.namespace }}/{{ $labels.pod}} has only
found {{ $value }} members of the {{$labels.job}} cluster.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagermembersinconsistent
summary: >-
A member of an Alertmanager cluster has not found all other
cluster members.
expr: >-
# Without max_over_time, failed scrapes could create false
negatives, see
#
https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0
for details.
max_over_time(alertmanager_cluster_members{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m])
< on (namespace,service,cluster) group_left
count by (namespace,service,cluster) (max_over_time(alertmanager_cluster_members{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m]))
for: 15m
labels:
severity: critical
- alert: AlertmanagerFailedToSendAlerts
annotations:
description: >-
Alertmanager {{ $labels.namespace }}/{{ $labels.pod}} failed to
send {{ $value | humanizePercentage }} of notifications to {{
$labels.integration }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerfailedtosendalerts
summary: An Alertmanager instance failed to send notifications.
expr: |-
(
rate(alertmanager_notifications_failed_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m])
/
ignoring (reason) group_left rate(alertmanager_notifications_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m])
)
> 0.01
for: 5m
labels:
severity: warning
- alert: AlertmanagerClusterFailedToSendAlerts
annotations:
description: >-
The minimum notification failure rate to {{ $labels.integration }}
sent from any instance in the {{$labels.job}} cluster is {{ $value
| humanizePercentage }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerclusterfailedtosendalerts
summary: >-
All Alertmanager instances in a cluster failed to send
notifications to a critical integration.
expr: |-
min by (namespace,service,integration,cluster) (
rate(alertmanager_notifications_failed_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics", integration=~`.*`}[5m])
/
ignoring (reason) group_left rate(alertmanager_notifications_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics", integration=~`.*`}[5m])
)
> 0.01
for: 5m
labels:
severity: critical
- alert: AlertmanagerClusterFailedToSendAlerts
annotations:
description: >-
The minimum notification failure rate to {{ $labels.integration }}
sent from any instance in the {{$labels.job}} cluster is {{ $value
| humanizePercentage }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerclusterfailedtosendalerts
summary: >-
All Alertmanager instances in a cluster failed to send
notifications to a non-critical integration.
expr: |-
min by (namespace,service,integration,cluster) (
rate(alertmanager_notifications_failed_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics", integration!~`.*`}[5m])
/
ignoring (reason) group_left rate(alertmanager_notifications_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics", integration!~`.*`}[5m])
)
> 0.01
for: 5m
labels:
severity: warning
- alert: AlertmanagerConfigInconsistent
annotations:
description: >-
Alertmanager instances within the {{$labels.job}} cluster have
different configurations.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerconfiginconsistent
summary: >-
Alertmanager instances within the same cluster have different
configurations.
expr: |-
count by (namespace,service,cluster) (
count_values by (namespace,service,cluster) ("config_hash", alertmanager_config_hash{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"})
)
!= 1
for: 20m
labels:
severity: critical
- alert: AlertmanagerClusterDown
annotations:
description: >-
{{ $value | humanizePercentage }} of Alertmanager instances within
the {{$labels.job}} cluster have been up for less than half of the
last 5m.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerclusterdown
summary: >-
Half or more of the Alertmanager instances within the same cluster
are down.
expr: |-
(
count by (namespace,service,cluster) (
avg_over_time(up{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m]) < 0.5
)
/
count by (namespace,service,cluster) (
up{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}
)
)
>= 0.5
for: 5m
labels:
severity: critical
- alert: AlertmanagerClusterCrashlooping
annotations:
description: >-
{{ $value | humanizePercentage }} of Alertmanager instances within
the {{$labels.job}} cluster have restarted at least 5 times in the
last 10m.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerclustercrashlooping
summary: >-
Half or more of the Alertmanager instances within the same cluster
are crashlooping.
expr: |-
(
count by (namespace,service,cluster) (
changes(process_start_time_seconds{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[10m]) > 4
)
/
count by (namespace,service,cluster) (
up{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}
)
)
>= 0.5
for: 5m
labels:
severity: critical
- name: etcd
rules:
- alert: etcdMembersDown
annotations:
description: 'etcd cluster "{{ $labels.job }}": members are down ({{ $value }}).'
summary: etcd cluster members are down.
expr: |-
max without (endpoint) (
sum without (instance) (up{job=~".*etcd.*"} == bool 0)
or
count without (To) (
sum without (instance) (rate(etcd_network_peer_sent_failures_total{job=~".*etcd.*"}[120s])) > 0.01
)
)
> 0
for: 10m
labels:
severity: critical
- alert: etcdInsufficientMembers
annotations:
description: >-
etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).
summary: etcd cluster has insufficient number of members.
expr: >-
sum(up{job=~".*etcd.*"} == bool 1) without (instance) <
((count(up{job=~".*etcd.*"}) without (instance) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
description: >-
etcd cluster "{{ $labels.job }}": member {{ $labels.instance }}
has no leader.
summary: etcd cluster has no leader.
expr: etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighNumberOfLeaderChanges
annotations:
description: >-
etcd cluster "{{ $labels.job }}": {{ $value }} leader changes
within the last 15 minutes. Frequent elections may be a sign of
insufficient resources, high network latency, or disruptions by
other components and should be investigated.
summary: etcd cluster has high number of leader changes.
expr: >-
increase((max without (instance)
(etcd_server_leader_changes_seen_total{job=~".*etcd.*"}) or
0*absent(etcd_server_leader_changes_seen_total{job=~".*etcd.*"}))[15m:1m])
>= 4
for: 5m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
description: >-
etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance
}}.
summary: etcd cluster has high number of failed grpc requests.
expr: >-
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*",
grpc_code=~"Unknown|FailedPrecondition|ResourceExhausted|Internal|Unavailable|DataLoss|DeadlineExceeded"}[5m]))
without (grpc_type, grpc_code)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) without
(grpc_type, grpc_code)
> 1
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
description: >-
etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance
}}.
summary: etcd cluster has high number of failed grpc requests.
expr: >-
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*",
grpc_code=~"Unknown|FailedPrecondition|ResourceExhausted|Internal|Unavailable|DataLoss|DeadlineExceeded"}[5m]))
without (grpc_type, grpc_code)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) without
(grpc_type, grpc_code)
> 5
for: 5m
labels:
severity: critical
- alert: etcdGRPCRequestsSlow
annotations:
description: >-
etcd cluster "{{ $labels.job }}": 99th percentile of gRPC requests
is {{ $value }}s on etcd instance {{ $labels.instance }} for {{
$labels.grpc_method }} method.
summary: etcd grpc requests are slow
expr: >-
histogram_quantile(0.99,
sum(rate(grpc_server_handling_seconds_bucket{job=~".*etcd.*",
grpc_method!="Defragment", grpc_type="unary"}[5m]))
without(grpc_type))
> 0.15
for: 10m
labels:
severity: critical
- alert: etcdMemberCommunicationSlow
annotations:
description: >-
etcd cluster "{{ $labels.job }}": member communication with {{
$labels.To }} is taking {{ $value }}s on etcd instance {{
$labels.instance }}.
summary: etcd cluster member communication is slow.
expr: >-
histogram_quantile(0.99,
rate(etcd_network_peer_round_trip_time_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.15
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedProposals
annotations:
description: >-
etcd cluster "{{ $labels.job }}": {{ $value }} proposal failures
within the last 30 minutes on etcd instance {{ $labels.instance
}}.
summary: etcd cluster has high number of proposal failures.
expr: rate(etcd_server_proposals_failed_total{job=~".*etcd.*"}[15m]) > 5
for: 15m
labels:
severity: warning
- alert: etcdHighFsyncDurations
annotations:
description: >-
etcd cluster "{{ $labels.job }}": 99th percentile fsync durations
are {{ $value }}s on etcd instance {{ $labels.instance }}.
summary: etcd cluster 99th percentile fsync durations are too high.
expr: >-
histogram_quantile(0.99,
rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcdHighFsyncDurations
annotations:
description: >-
etcd cluster "{{ $labels.job }}": 99th percentile fsync durations
are {{ $value }}s on etcd instance {{ $labels.instance }}.
summary: etcd cluster 99th percentile fsync durations are too high.
expr: >-
histogram_quantile(0.99,
rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 1
for: 10m
labels:
severity: critical
- alert: etcdHighCommitDurations
annotations:
description: >-
etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.
summary: etcd cluster 99th percentile commit durations are too high.
expr: >-
histogram_quantile(0.99,
rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcdDatabaseQuotaLowSpace
annotations:
description: >-
etcd cluster "{{ $labels.job }}": database size exceeds the
defined quota on etcd instance {{ $labels.instance }}, please
defrag or increase the quota as the writes to etcd will be
disabled when it is full.
summary: etcd cluster database is running full.
expr: >-
(last_over_time(etcd_mvcc_db_total_size_in_bytes{job=~".*etcd.*"}[5m])
/
last_over_time(etcd_server_quota_backend_bytes{job=~".*etcd.*"}[5m]))*100
> 95
for: 10m
labels:
severity: critical
- alert: etcdExcessiveDatabaseGrowth
annotations:
description: >-
etcd cluster "{{ $labels.job }}": Predicting running out of disk
space in the next four hours, based on write observations within
the past four hours on etcd instance {{ $labels.instance }},
please check as it might be disruptive.
summary: etcd cluster database growing very fast.
expr: >-
predict_linear(etcd_mvcc_db_total_size_in_bytes{job=~".*etcd.*"}[4h],
4*60*60) > etcd_server_quota_backend_bytes{job=~".*etcd.*"}
for: 10m
labels:
severity: warning
- alert: etcdDatabaseHighFragmentationRatio
annotations:
description: >-
etcd cluster "{{ $labels.job }}": database size in use on instance
{{ $labels.instance }} is {{ $value | humanizePercentage }} of the
actual allocated disk space, please run defragmentation (e.g.
etcdctl defrag) to retrieve the unused fragmented disk space.
runbook_url: https://etcd.io/docs/v3.5/op-guide/maintenance/#defragmentation
summary: >-
etcd database size in use is less than 50% of the actual allocated
storage.
expr: >-
(last_over_time(etcd_mvcc_db_total_size_in_use_in_bytes{job=~".*etcd.*"}[5m])
/
last_over_time(etcd_mvcc_db_total_size_in_bytes{job=~".*etcd.*"}[5m]))
< 0.5 and etcd_mvcc_db_total_size_in_use_in_bytes{job=~".*etcd.*"} >
104857600
for: 10m
labels:
severity: warning
- name: general.rules
rules:
- alert: TargetDown
annotations:
description: >-
{{ printf "%.4g" $value }}% of the {{ $labels.job }}/{{
$labels.service }} targets in {{ $labels.namespace }} namespace
are down.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/general/targetdown
summary: One or more targets are unreachable.
expr: >-
100 * (count(up == 0) BY (job,namespace,service,cluster) / count(up)
BY (job,namespace,service,cluster)) > 10
for: 10m
labels:
severity: warning
- alert: Watchdog
annotations:
description: >
This is an alert meant to ensure that the entire alerting pipeline
is functional.
This alert is always firing, therefore it should always be firing
in Alertmanager
and always fire against a receiver. There are integrations with
various notification
mechanisms that send a notification when this alert is not firing.
For example the
"DeadMansSnitch" integration in PagerDuty.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/general/watchdog
summary: >-
An alert that should always be firing to certify that Alertmanager
is working properly.
expr: vector(1)
labels:
severity: none
- alert: InfoInhibitor
annotations:
description: >
This is an alert that is used to inhibit info alerts.
By themselves, the info-level alerts are sometimes very noisy, but
they are relevant when combined with
other alerts.
This alert fires whenever there's a severity="info" alert, and
stops firing when another alert with a
severity of 'warning' or 'critical' starts firing on the same
namespace.
This alert should be routed to a null receiver and configured to
inhibit alerts with severity="info".
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/general/infoinhibitor
summary: Info-level alert inhibition.
expr: >-
ALERTS{severity = "info"} == 1 unless on (namespace,cluster)
ALERTS{alertname != "InfoInhibitor", severity =~ "warning|critical",
alertstate="firing"} == 1
labels:
severity: none
- name: k8s.rules.container_cpu_limits
rules:
- expr: >-
kube_pod_container_resource_limits{resource="cpu",job="kube-state-metrics"}
* on (namespace,pod,cluster)
group_left() max by (namespace,pod,cluster) (
(kube_pod_status_phase{phase=~"Pending|Running"} == 1)
)
record: cluster:namespace:pod_cpu:active:kube_pod_container_resource_limits
- expr: |-
sum by (namespace,cluster) (
sum by (namespace,pod,cluster) (
max by (namespace,pod,container,cluster) (
kube_pod_container_resource_limits{resource="cpu",job="kube-state-metrics"}
) * on (namespace,pod,cluster) group_left() max by (namespace,pod,cluster) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)
)
)
record: namespace_cpu:kube_pod_container_resource_limits:sum
- name: k8s.rules.container_cpu_requests
rules:
- expr: >-
kube_pod_container_resource_requests{resource="cpu",job="kube-state-metrics"}
* on (namespace,pod,cluster)
group_left() max by (namespace,pod,cluster) (
(kube_pod_status_phase{phase=~"Pending|Running"} == 1)
)
record: >-
cluster:namespace:pod_cpu:active:kube_pod_container_resource_requests
- expr: |-
sum by (namespace,cluster) (
sum by (namespace,pod,cluster) (
max by (namespace,pod,container,cluster) (
kube_pod_container_resource_requests{resource="cpu",job="kube-state-metrics"}
) * on (namespace,pod,cluster) group_left() max by (namespace,pod,cluster) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)
)
)
record: namespace_cpu:kube_pod_container_resource_requests:sum
- name: k8s.rules.container_cpu_usage_seconds_total
rules:
- expr: >-
sum by (namespace,pod,container,cluster) (
irate(container_cpu_usage_seconds_total{job="kubelet", metrics_path="/metrics/cadvisor", image!=""}[5m])
) * on (namespace,pod,cluster) group_left(node) topk by
(namespace,pod,cluster) (
1, max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: >-
node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate
- name: k8s.rules.container_memory_cache
rules:
- expr: >-
container_memory_cache{job="kubelet",
metrics_path="/metrics/cadvisor", image!=""}
* on (namespace,pod,cluster) group_left(node) topk by
(namespace,pod,cluster) (1,
max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: node_namespace_pod_container:container_memory_cache
- name: k8s.rules.container_memory_limits
rules:
- expr: >-
kube_pod_container_resource_limits{resource="memory",job="kube-state-metrics"}
* on (namespace,pod,cluster)
group_left() max by (namespace,pod,cluster) (
(kube_pod_status_phase{phase=~"Pending|Running"} == 1)
)
record: >-
cluster:namespace:pod_memory:active:kube_pod_container_resource_limits
- expr: |-
sum by (namespace,cluster) (
sum by (namespace,pod,cluster) (
max by (namespace,pod,container,cluster) (
kube_pod_container_resource_limits{resource="memory",job="kube-state-metrics"}
) * on (namespace,pod,cluster) group_left() max by (namespace,pod,cluster) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)
)
)
record: namespace_memory:kube_pod_container_resource_limits:sum
- name: k8s.rules.container_memory_requests
rules:
- expr: >-
kube_pod_container_resource_requests{resource="memory",job="kube-state-metrics"}
* on (namespace,pod,cluster)
group_left() max by (namespace,pod,cluster) (
(kube_pod_status_phase{phase=~"Pending|Running"} == 1)
)
record: >-
cluster:namespace:pod_memory:active:kube_pod_container_resource_requests
- expr: |-
sum by (namespace,cluster) (
sum by (namespace,pod,cluster) (
max by (namespace,pod,container,cluster) (
kube_pod_container_resource_requests{resource="memory",job="kube-state-metrics"}
) * on (namespace,pod,cluster) group_left() max by (namespace,pod,cluster) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)
)
)
record: namespace_memory:kube_pod_container_resource_requests:sum
- name: k8s.rules.container_memory_rss
rules:
- expr: >-
container_memory_rss{job="kubelet",
metrics_path="/metrics/cadvisor", image!=""}
* on (namespace,pod,cluster) group_left(node) topk by
(namespace,pod,cluster) (1,
max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: node_namespace_pod_container:container_memory_rss
- name: k8s.rules.container_memory_swap
rules:
- expr: >-
container_memory_swap{job="kubelet",
metrics_path="/metrics/cadvisor", image!=""}
* on (namespace,pod,cluster) group_left(node) topk by
(namespace,pod,cluster) (1,
max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: node_namespace_pod_container:container_memory_swap
- name: k8s.rules.container_memory_working_set_bytes
rules:
- expr: >-
container_memory_working_set_bytes{job="kubelet",
metrics_path="/metrics/cadvisor", image!=""}
* on (namespace,pod,cluster) group_left(node) topk by
(namespace,pod,cluster) (1,
max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: node_namespace_pod_container:container_memory_working_set_bytes
- name: k8s.rules.pod_owner
rules:
- expr: |-
max by (namespace,workload,pod,cluster) (
label_replace(
label_replace(
kube_pod_owner{job="kube-state-metrics", owner_kind="ReplicaSet"},
"replicaset", "$1", "owner_name", "(.*)"
) * on (replicaset,namespace,cluster) group_left(owner_name) topk by (replicaset,namespace,cluster) (
1, max by (replicaset,namespace,owner_name,cluster) (
kube_replicaset_owner{job="kube-state-metrics"}
)
),
"workload", "$1", "owner_name", "(.*)"
)
)
labels:
workload_type: deployment
record: namespace_workload_pod:kube_pod_owner:relabel
- expr: |-
max by (namespace,workload,pod,cluster) (
label_replace(
kube_pod_owner{job="kube-state-metrics", owner_kind="DaemonSet"},
"workload", "$1", "owner_name", "(.*)"
)
)
labels:
workload_type: daemonset
record: namespace_workload_pod:kube_pod_owner:relabel
- expr: |-
max by (namespace,workload,pod,cluster) (
label_replace(
kube_pod_owner{job="kube-state-metrics", owner_kind="StatefulSet"},
"workload", "$1", "owner_name", "(.*)"
)
)
labels:
workload_type: statefulset
record: namespace_workload_pod:kube_pod_owner:relabel
- expr: |-
max by (namespace,workload,pod,cluster) (
label_replace(
kube_pod_owner{job="kube-state-metrics", owner_kind="Job"},
"workload", "$1", "owner_name", "(.*)"
)
)
labels:
workload_type: job
record: namespace_workload_pod:kube_pod_owner:relabel
- interval: 3m
name: kube-apiserver-availability.rules
rules:
- expr: >-
avg_over_time(code_verb:apiserver_request_total:increase1h[30d]) *
24 * 30
record: code_verb:apiserver_request_total:increase30d
- expr: >-
sum by (code,cluster)
(code_verb:apiserver_request_total:increase30d{verb=~"LIST|GET"})
labels:
verb: read
record: code:apiserver_request_total:increase30d
- expr: >-
sum by (code,cluster)
(code_verb:apiserver_request_total:increase30d{verb=~"POST|PUT|PATCH|DELETE"})
labels:
verb: write
record: code:apiserver_request_total:increase30d
- expr: >-
sum by (verb,scope,le,cluster)
(increase(apiserver_request_sli_duration_seconds_bucket[1h]))
record: >-
cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase1h
- expr: >-
sum by (verb,scope,le,cluster)
(avg_over_time(cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase1h[30d])
* 24 * 30)
record: >-
cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d
- expr: >-
sum by (verb,scope,cluster)
(cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase1h{le="+Inf"})
record: >-
cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase1h
- expr: >-
sum by (verb,scope,cluster)
(cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{le="+Inf"})
record: >-
cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d
- expr: |-
1 - (
(
# write too slow
sum by (cluster) (cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d{verb=~"POST|PUT|PATCH|DELETE"})
-
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"POST|PUT|PATCH|DELETE",le=~"1(\\.0)?"})
) +
(
# read too slow
sum by (cluster) (cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d{verb=~"LIST|GET"})
-
(
(
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope=~"resource|",le=~"1(\\.0)?"})
or
vector(0)
)
+
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope="namespace",le=~"5(\\.0)?"})
+
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope="cluster",le=~"30(\\.0)?"})
)
) +
# errors
sum by (cluster) (code:apiserver_request_total:increase30d{code=~"5.."} or vector(0))
)
/
sum by (cluster) (code:apiserver_request_total:increase30d)
labels:
verb: all
record: apiserver_request:availability30d
- expr: >-
1 - (
sum by (cluster) (cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d{verb=~"LIST|GET"})
-
(
# too slow
(
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope=~"resource|",le=~"1(\\.0)?"})
or
vector(0)
)
+
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope="namespace",le=~"5(\\.0)?"})
+
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope="cluster",le=~"30(\\.0)?"})
)
+
# errors
sum by (cluster) (code:apiserver_request_total:increase30d{verb="read",code=~"5.."} or vector(0))
)
/
sum by (cluster)
(code:apiserver_request_total:increase30d{verb="read"})
labels:
verb: read
record: apiserver_request:availability30d
- expr: >-
1 - (
(
# too slow
sum by (cluster) (cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d{verb=~"POST|PUT|PATCH|DELETE"})
-
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"POST|PUT|PATCH|DELETE",le=~"1(\\.0)?"})
)
+
# errors
sum by (cluster) (code:apiserver_request_total:increase30d{verb="write",code=~"5.."} or vector(0))
)
/
sum by (cluster)
(code:apiserver_request_total:increase30d{verb="write"})
labels:
verb: write
record: apiserver_request:availability30d
- expr: >-
sum by (code,resource,cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[5m]))
labels:
verb: read
record: code_resource:apiserver_request_total:rate5m
- expr: >-
sum by (code,resource,cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
labels:
verb: write
record: code_resource:apiserver_request_total:rate5m
- expr: >-
sum by (code,verb,cluster)
(increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"2.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
- expr: >-
sum by (code,verb,cluster)
(increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"3.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
- expr: >-
sum by (code,verb,cluster)
(increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"4.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
- expr: >-
sum by (code,verb,cluster)
(increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"5.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
- name: kube-apiserver-burnrate.rules
rules:
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[1d]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[1d]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[1d]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[1d]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[1d]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[1d]))
labels:
verb: read
record: apiserver_request:burnrate1d
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[1h]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[1h]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[1h]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[1h]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[1h]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[1h]))
labels:
verb: read
record: apiserver_request:burnrate1h
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[2h]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[2h]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[2h]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[2h]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[2h]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[2h]))
labels:
verb: read
record: apiserver_request:burnrate2h
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[30m]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[30m]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[30m]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[30m]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[30m]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[30m]))
labels:
verb: read
record: apiserver_request:burnrate30m
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[3d]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[3d]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[3d]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[3d]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[3d]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[3d]))
labels:
verb: read
record: apiserver_request:burnrate3d
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[5m]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[5m]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[5m]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[5m]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[5m]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[5m]))
labels:
verb: read
record: apiserver_request:burnrate5m
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[6h]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[6h]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[6h]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[6h]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[6h]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[6h]))
labels:
verb: read
record: apiserver_request:burnrate6h
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[1d]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[1d]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1d]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1d]))
labels:
verb: write
record: apiserver_request:burnrate1d
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[1h]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[1h]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1h]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1h]))
labels:
verb: write
record: apiserver_request:burnrate1h
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[2h]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[2h]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[2h]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[2h]))
labels:
verb: write
record: apiserver_request:burnrate2h
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[30m]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[30m]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[30m]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[30m]))
labels:
verb: write
record: apiserver_request:burnrate30m
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[3d]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[3d]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[3d]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[3d]))
labels:
verb: write
record: apiserver_request:burnrate3d
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[5m]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[5m]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[5m]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
labels:
verb: write
record: apiserver_request:burnrate5m
- expr: >-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[6h]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[6h]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[6h]))
)
/
sum by (cluster)
(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[6h]))
labels:
verb: write
record: apiserver_request:burnrate6h
- name: kube-apiserver-histogram.rules
rules:
- expr: >-
histogram_quantile(0.99, sum by (le,resource,cluster)
(rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[5m])))
> 0
labels:
quantile: '0.99'
verb: read
record: >-
cluster_quantile:apiserver_request_sli_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.99, sum by (le,resource,cluster)
(rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[5m])))
> 0
labels:
quantile: '0.99'
verb: write
record: >-
cluster_quantile:apiserver_request_sli_duration_seconds:histogram_quantile
- name: kube-apiserver-slos
rules:
- alert: KubeAPIErrorBudgetBurn
annotations:
description: >-
The API server is burning too much error budget on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapierrorbudgetburn
summary: The API server is burning too much error budget.
expr: |-
sum by (cluster) (apiserver_request:burnrate1h) > (14.40 * 0.01000)
and on (cluster)
sum by (cluster) (apiserver_request:burnrate5m) > (14.40 * 0.01000)
for: 2m
labels:
long: 1h
severity: critical
short: 5m
- alert: KubeAPIErrorBudgetBurn
annotations:
description: >-
The API server is burning too much error budget on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapierrorbudgetburn
summary: The API server is burning too much error budget.
expr: |-
sum by (cluster) (apiserver_request:burnrate6h) > (6.00 * 0.01000)
and on (cluster)
sum by (cluster) (apiserver_request:burnrate30m) > (6.00 * 0.01000)
for: 15m
labels:
long: 6h
severity: critical
short: 30m
- alert: KubeAPIErrorBudgetBurn
annotations:
description: >-
The API server is burning too much error budget on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapierrorbudgetburn
summary: The API server is burning too much error budget.
expr: |-
sum by (cluster) (apiserver_request:burnrate1d) > (3.00 * 0.01000)
and on (cluster)
sum by (cluster) (apiserver_request:burnrate2h) > (3.00 * 0.01000)
for: 1h
labels:
long: 1d
severity: warning
short: 2h
- alert: KubeAPIErrorBudgetBurn
annotations:
description: >-
The API server is burning too much error budget on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapierrorbudgetburn
summary: The API server is burning too much error budget.
expr: |-
sum by (cluster) (apiserver_request:burnrate3d) > (1.00 * 0.01000)
and on (cluster)
sum by (cluster) (apiserver_request:burnrate6h) > (1.00 * 0.01000)
for: 3h
labels:
long: 3d
severity: warning
short: 6h
- name: kube-prometheus-general.rules
rules:
- expr: count without(instance, pod, node) (up == 1)
record: count:up1
- expr: count without(instance, pod, node) (up == 0)
record: count:up0
- name: kube-prometheus-node-recording.rules
rules:
- expr: >-
sum(rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal"}[3m]))
BY (instance,cluster)
record: instance:node_cpu:rate:sum
- expr: >-
sum(rate(node_network_receive_bytes_total[3m])) BY
(instance,cluster)
record: instance:node_network_receive_bytes:rate:sum
- expr: >-
sum(rate(node_network_transmit_bytes_total[3m])) BY
(instance,cluster)
record: instance:node_network_transmit_bytes:rate:sum
- expr: >-
sum(rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal"}[5m]))
WITHOUT (cpu, mode) / ON (instance,cluster) GROUP_LEFT()
count(sum(node_cpu_seconds_total) BY (instance,cpu,cluster)) BY
(instance,cluster)
record: instance:node_cpu:ratio
- expr: >-
sum(rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal"}[5m]))
BY (cluster)
record: cluster:node_cpu:sum_rate5m
- expr: >-
cluster:node_cpu:sum_rate5m / count(sum(node_cpu_seconds_total) BY
(instance,cpu,cluster)) BY (cluster)
record: cluster:node_cpu:ratio
- name: kube-scheduler.rules
rules:
- expr: >-
histogram_quantile(0.99,
sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: '0.99'
record: >-
cluster_quantile:scheduler_e2e_scheduling_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.99,
sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: '0.99'
record: >-
cluster_quantile:scheduler_scheduling_algorithm_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.99,
sum(rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: '0.99'
record: >-
cluster_quantile:scheduler_binding_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.9,
sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: '0.9'
record: >-
cluster_quantile:scheduler_e2e_scheduling_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.9,
sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: '0.9'
record: >-
cluster_quantile:scheduler_scheduling_algorithm_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.9,
sum(rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: '0.9'
record: >-
cluster_quantile:scheduler_binding_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.5,
sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: '0.5'
record: >-
cluster_quantile:scheduler_e2e_scheduling_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.5,
sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: '0.5'
record: >-
cluster_quantile:scheduler_scheduling_algorithm_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.5,
sum(rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: '0.5'
record: >-
cluster_quantile:scheduler_binding_duration_seconds:histogram_quantile
- name: kube-state-metrics
rules:
- alert: KubeStateMetricsListErrors
annotations:
description: >-
kube-state-metrics is experiencing errors at an elevated rate in
list operations. This is likely causing it to not be able to
expose metrics about Kubernetes objects correctly or at all.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kube-state-metrics/kubestatemetricslisterrors
summary: kube-state-metrics is experiencing errors in list operations.
expr: >-
(sum(rate(kube_state_metrics_list_total{job="kube-state-metrics",result="error"}[5m]))
by (cluster)
/
sum(rate(kube_state_metrics_list_total{job="kube-state-metrics"}[5m]))
by (cluster))
> 0.01
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsWatchErrors
annotations:
description: >-
kube-state-metrics is experiencing errors at an elevated rate in
watch operations. This is likely causing it to not be able to
expose metrics about Kubernetes objects correctly or at all.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kube-state-metrics/kubestatemetricswatcherrors
summary: kube-state-metrics is experiencing errors in watch operations.
expr: >-
(sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics",result="error"}[5m]))
by (cluster)
/
sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics"}[5m]))
by (cluster))
> 0.01
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsShardingMismatch
annotations:
description: >-
kube-state-metrics pods are running with different --total-shards
configuration, some Kubernetes objects may be exposed multiple
times or not exposed at all.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kube-state-metrics/kubestatemetricsshardingmismatch
summary: kube-state-metrics sharding is misconfigured.
expr: >-
stdvar (kube_state_metrics_total_shards{job="kube-state-metrics"})
by (cluster) != 0
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsShardsMissing
annotations:
description: >-
kube-state-metrics shards are missing, some Kubernetes objects are
not being exposed.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kube-state-metrics/kubestatemetricsshardsmissing
summary: kube-state-metrics shards are missing.
expr: >-
2^max(kube_state_metrics_total_shards{job="kube-state-metrics"}) by
(cluster) - 1
-
sum( 2 ^ max by (shard_ordinal,cluster)
(kube_state_metrics_shard_ordinal{job="kube-state-metrics"}) ) by
(cluster)
!= 0
for: 15m
labels:
severity: critical
- name: kubelet.rules
rules:
- expr: >-
histogram_quantile(0.99,
sum(rate(kubelet_pleg_relist_duration_seconds_bucket{job="kubelet",
metrics_path="/metrics"}[5m])) by (instance,le,cluster) * on
(instance,cluster) group_left(node) kubelet_node_name{job="kubelet",
metrics_path="/metrics"})
labels:
quantile: '0.99'
record: >-
node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.9,
sum(rate(kubelet_pleg_relist_duration_seconds_bucket{job="kubelet",
metrics_path="/metrics"}[5m])) by (instance,le,cluster) * on
(instance,cluster) group_left(node) kubelet_node_name{job="kubelet",
metrics_path="/metrics"})
labels:
quantile: '0.9'
record: >-
node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
- expr: >-
histogram_quantile(0.5,
sum(rate(kubelet_pleg_relist_duration_seconds_bucket{job="kubelet",
metrics_path="/metrics"}[5m])) by (instance,le,cluster) * on
(instance,cluster) group_left(node) kubelet_node_name{job="kubelet",
metrics_path="/metrics"})
labels:
quantile: '0.5'
record: >-
node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
- name: kubernetes-apps
rules:
- alert: KubePodCrashLooping
annotations:
description: >-
Pod {{ $labels.namespace }}/{{ $labels.pod }} ({{
$labels.container }}) is in waiting state (reason:
"CrashLoopBackOff") on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepodcrashlooping
summary: Pod is crash looping.
expr: >-
max_over_time(kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff",
job="kube-state-metrics", namespace=~".*"}[5m]) >= 1
for: 15m
labels:
severity: warning
- alert: KubePodNotReady
annotations:
description: >-
Pod {{ $labels.namespace }}/{{ $labels.pod }} has been in a
non-ready state for longer than 15 minutes on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepodnotready
summary: Pod has been in a non-ready state for more than 15 minutes.
expr: |-
sum by (namespace,pod,cluster) (
max by (namespace,pod,cluster) (
kube_pod_status_phase{job="kube-state-metrics", namespace=~".*", phase=~"Pending|Unknown|Failed"}
) * on (namespace,pod,cluster) group_left(owner_kind) topk by (namespace,pod,cluster) (
1, max by (namespace,pod,owner_kind,cluster) (kube_pod_owner{owner_kind!="Job"})
)
) > 0
for: 15m
labels:
severity: warning
- alert: KubeDeploymentGenerationMismatch
annotations:
description: >-
Deployment generation for {{ $labels.namespace }}/{{
$labels.deployment }} does not match, this indicates that the
Deployment has failed but has not been rolled back on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedeploymentgenerationmismatch
summary: Deployment generation mismatch due to possible roll-back
expr: >-
kube_deployment_status_observed_generation{job="kube-state-metrics",
namespace=~".*"}
!=
kube_deployment_metadata_generation{job="kube-state-metrics",
namespace=~".*"}
for: 15m
labels:
severity: warning
- alert: KubeDeploymentReplicasMismatch
annotations:
description: >-
Deployment {{ $labels.namespace }}/{{ $labels.deployment }} has
not matched the expected number of replicas for longer than 15
minutes on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedeploymentreplicasmismatch
summary: Deployment has not matched the expected number of replicas.
expr: |-
(
kube_deployment_spec_replicas{job="kube-state-metrics", namespace=~".*"}
>
kube_deployment_status_replicas_available{job="kube-state-metrics", namespace=~".*"}
) and (
changes(kube_deployment_status_replicas_updated{job="kube-state-metrics", namespace=~".*"}[10m])
==
0
)
for: 15m
labels:
severity: warning
- alert: KubeDeploymentRolloutStuck
annotations:
description: >-
Rollout of deployment {{ $labels.namespace }}/{{
$labels.deployment }} is not progressing for longer than 15
minutes on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedeploymentrolloutstuck
summary: Deployment rollout is not progressing.
expr: >-
kube_deployment_status_condition{condition="Progressing",
status="false",job="kube-state-metrics", namespace=~".*"}
!= 0
for: 15m
labels:
severity: warning
- alert: KubeStatefulSetReplicasMismatch
annotations:
description: >-
StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }} has
not matched the expected number of replicas for longer than 15
minutes on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubestatefulsetreplicasmismatch
summary: StatefulSet has not matched the expected number of replicas.
expr: |-
(
kube_statefulset_status_replicas_ready{job="kube-state-metrics", namespace=~".*"}
!=
kube_statefulset_status_replicas{job="kube-state-metrics", namespace=~".*"}
) and (
changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics", namespace=~".*"}[10m])
==
0
)
for: 15m
labels:
severity: warning
- alert: KubeStatefulSetGenerationMismatch
annotations:
description: >-
StatefulSet generation for {{ $labels.namespace }}/{{
$labels.statefulset }} does not match, this indicates that the
StatefulSet has failed but has not been rolled back on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubestatefulsetgenerationmismatch
summary: StatefulSet generation mismatch due to possible roll-back
expr: >-
kube_statefulset_status_observed_generation{job="kube-state-metrics",
namespace=~".*"}
!=
kube_statefulset_metadata_generation{job="kube-state-metrics",
namespace=~".*"}
for: 15m
labels:
severity: warning
- alert: KubeStatefulSetUpdateNotRolledOut
annotations:
description: >-
StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }}
update has not been rolled out on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubestatefulsetupdatenotrolledout
summary: StatefulSet update has not been rolled out.
expr: |-
(
max by (namespace,statefulset,job,cluster) (
kube_statefulset_status_current_revision{job="kube-state-metrics", namespace=~".*"}
unless
kube_statefulset_status_update_revision{job="kube-state-metrics", namespace=~".*"}
)
*
(
kube_statefulset_replicas{job="kube-state-metrics", namespace=~".*"}
!=
kube_statefulset_status_replicas_updated{job="kube-state-metrics", namespace=~".*"}
)
) and (
changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics", namespace=~".*"}[5m])
==
0
)
for: 15m
labels:
severity: warning
- alert: KubeDaemonSetRolloutStuck
annotations:
description: >-
DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} has not
finished or progressed for at least 15m on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedaemonsetrolloutstuck
summary: DaemonSet rollout is stuck.
expr: |-
(
(
kube_daemonset_status_current_number_scheduled{job="kube-state-metrics", namespace=~".*"}
!=
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics", namespace=~".*"}
) or (
kube_daemonset_status_number_misscheduled{job="kube-state-metrics", namespace=~".*"}
!=
0
) or (
kube_daemonset_status_updated_number_scheduled{job="kube-state-metrics", namespace=~".*"}
!=
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics", namespace=~".*"}
) or (
kube_daemonset_status_number_available{job="kube-state-metrics", namespace=~".*"}
!=
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics", namespace=~".*"}
)
) and (
changes(kube_daemonset_status_updated_number_scheduled{job="kube-state-metrics", namespace=~".*"}[5m])
==
0
)
for: 15m
labels:
severity: warning
- alert: KubeContainerWaiting
annotations:
description: >-
pod/{{ $labels.pod }} in namespace {{ $labels.namespace }} on
container {{ $labels.container}} has been in waiting state for
longer than 1 hour. (reason: "{{ $labels.reason }}") on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubecontainerwaiting
summary: Pod container waiting longer than 1 hour
expr: >-
kube_pod_container_status_waiting_reason{reason!="CrashLoopBackOff",
job="kube-state-metrics", namespace=~".*"} > 0
for: 1h
labels:
severity: warning
- alert: KubeDaemonSetNotScheduled
annotations:
description: >-
{{ $value }} Pods of DaemonSet {{ $labels.namespace }}/{{
$labels.daemonset }} are not scheduled on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedaemonsetnotscheduled
summary: DaemonSet pods are not scheduled.
expr: >-
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics",
namespace=~".*"}
-
kube_daemonset_status_current_number_scheduled{job="kube-state-metrics",
namespace=~".*"} > 0
for: 10m
labels:
severity: warning
- alert: KubeDaemonSetMisScheduled
annotations:
description: >-
{{ $value }} Pods of DaemonSet {{ $labels.namespace }}/{{
$labels.daemonset }} are running where they are not supposed to
run on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedaemonsetmisscheduled
summary: DaemonSet pods are misscheduled.
expr: >-
kube_daemonset_status_number_misscheduled{job="kube-state-metrics",
namespace=~".*"} > 0
for: 15m
labels:
severity: warning
- alert: KubeJobNotCompleted
annotations:
description: >-
Job {{ $labels.namespace }}/{{ $labels.job_name }} is taking more
than {{ "43200" | humanizeDuration }} to complete on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubejobnotcompleted
summary: Job did not complete in time
expr: >-
time() - max by (namespace,job_name,cluster)
(kube_job_status_start_time{job="kube-state-metrics",
namespace=~".*"}
and
kube_job_status_active{job="kube-state-metrics", namespace=~".*"} >
0) > 43200
labels:
severity: warning
- alert: KubeJobFailed
annotations:
description: >-
Job {{ $labels.namespace }}/{{ $labels.job_name }} failed to
complete. Removing failed job after investigation should clear
this alert on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubejobfailed
summary: Job failed to complete.
expr: kube_job_failed{job="kube-state-metrics", namespace=~".*"} > 0
for: 15m
labels:
severity: warning
- alert: KubeHpaReplicasMismatch
annotations:
description: >-
HPA {{ $labels.namespace }}/{{ $labels.horizontalpodautoscaler }}
has not matched the desired number of replicas for longer than 15
minutes on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubehpareplicasmismatch
summary: HPA has not matched desired number of replicas.
expr: >-
(kube_horizontalpodautoscaler_status_desired_replicas{job="kube-state-metrics",
namespace=~".*"}
!=
kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics",
namespace=~".*"})
and
(kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics",
namespace=~".*"}
>
kube_horizontalpodautoscaler_spec_min_replicas{job="kube-state-metrics",
namespace=~".*"})
and
(kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics",
namespace=~".*"}
<
kube_horizontalpodautoscaler_spec_max_replicas{job="kube-state-metrics",
namespace=~".*"})
and
changes(kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics",
namespace=~".*"}[15m]) == 0
for: 15m
labels:
severity: warning
- alert: KubeHpaMaxedOut
annotations:
description: >-
HPA {{ $labels.namespace }}/{{ $labels.horizontalpodautoscaler }}
has been running at max replicas for longer than 15 minutes on
cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubehpamaxedout
summary: HPA is running at max replicas
expr: >-
kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics",
namespace=~".*"}
==
kube_horizontalpodautoscaler_spec_max_replicas{job="kube-state-metrics",
namespace=~".*"}
for: 15m
labels:
severity: warning
- name: kubernetes-resources
rules:
- alert: KubeCPUOvercommit
annotations:
description: >-
Cluster {{ $labels.cluster }} has overcommitted CPU resource
requests for Pods by {{ $value }} CPU shares and cannot tolerate
node failure.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubecpuovercommit
summary: Cluster has overcommitted CPU resource requests.
expr: >-
sum(namespace_cpu:kube_pod_container_resource_requests:sum{}) by
(cluster) -
(sum(kube_node_status_allocatable{job="kube-state-metrics",resource="cpu"})
by (cluster) -
max(kube_node_status_allocatable{job="kube-state-metrics",resource="cpu"})
by (cluster)) > 0
and
(sum(kube_node_status_allocatable{job="kube-state-metrics",resource="cpu"})
by (cluster) -
max(kube_node_status_allocatable{job="kube-state-metrics",resource="cpu"})
by (cluster)) > 0
for: 10m
labels:
severity: warning
- alert: KubeMemoryOvercommit
annotations:
description: >-
Cluster {{ $labels.cluster }} has overcommitted memory resource
requests for Pods by {{ $value | humanize }} bytes and cannot
tolerate node failure.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubememoryovercommit
summary: Cluster has overcommitted memory resource requests.
expr: >-
sum(namespace_memory:kube_pod_container_resource_requests:sum{}) by
(cluster) - (sum(kube_node_status_allocatable{resource="memory",
job="kube-state-metrics"}) by (cluster) -
max(kube_node_status_allocatable{resource="memory",
job="kube-state-metrics"}) by (cluster)) > 0
and
(sum(kube_node_status_allocatable{resource="memory",
job="kube-state-metrics"}) by (cluster) -
max(kube_node_status_allocatable{resource="memory",
job="kube-state-metrics"}) by (cluster)) > 0
for: 10m
labels:
severity: warning
- alert: KubeCPUQuotaOvercommit
annotations:
description: >-
Cluster {{ $labels.cluster }} has overcommitted CPU resource
requests for Namespaces.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubecpuquotaovercommit
summary: Cluster has overcommitted CPU resource requests.
expr: >-
sum(min without(resource)
(kube_resourcequota{job="kube-state-metrics", type="hard",
resource=~"(cpu|requests.cpu)"})) by (cluster)
/
sum(kube_node_status_allocatable{resource="cpu",
job="kube-state-metrics"}) by (cluster)
> 1.5
for: 5m
labels:
severity: warning
- alert: KubeMemoryQuotaOvercommit
annotations:
description: >-
Cluster {{ $labels.cluster }} has overcommitted memory resource
requests for Namespaces.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubememoryquotaovercommit
summary: Cluster has overcommitted memory resource requests.
expr: >-
sum(min without(resource)
(kube_resourcequota{job="kube-state-metrics", type="hard",
resource=~"(memory|requests.memory)"})) by (cluster)
/
sum(kube_node_status_allocatable{resource="memory",
job="kube-state-metrics"}) by (cluster)
> 1.5
for: 5m
labels:
severity: warning
- alert: KubeQuotaAlmostFull
annotations:
description: >-
Namespace {{ $labels.namespace }} is using {{ $value |
humanizePercentage }} of its {{ $labels.resource }} quota on
cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubequotaalmostfull
summary: Namespace quota is going to be full.
expr: |-
kube_resourcequota{job="kube-state-metrics", type="used"}
/ ignoring(instance, job, type)
(kube_resourcequota{job="kube-state-metrics", type="hard"} > 0)
> 0.9 < 1
for: 15m
labels:
severity: info
- alert: KubeQuotaFullyUsed
annotations:
description: >-
Namespace {{ $labels.namespace }} is using {{ $value |
humanizePercentage }} of its {{ $labels.resource }} quota on
cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubequotafullyused
summary: Namespace quota is fully used.
expr: |-
kube_resourcequota{job="kube-state-metrics", type="used"}
/ ignoring(instance, job, type)
(kube_resourcequota{job="kube-state-metrics", type="hard"} > 0)
== 1
for: 15m
labels:
severity: info
- alert: KubeQuotaExceeded
annotations:
description: >-
Namespace {{ $labels.namespace }} is using {{ $value |
humanizePercentage }} of its {{ $labels.resource }} quota on
cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubequotaexceeded
summary: Namespace quota has exceeded the limits.
expr: |-
kube_resourcequota{job="kube-state-metrics", type="used"}
/ ignoring(instance, job, type)
(kube_resourcequota{job="kube-state-metrics", type="hard"} > 0)
> 1
for: 15m
labels:
severity: warning
- alert: CPUThrottlingHigh
annotations:
description: >-
{{ $value | humanizePercentage }} throttling of CPU in namespace
{{ $labels.namespace }} for container {{ $labels.container }} in
pod {{ $labels.pod }} on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/cputhrottlinghigh
summary: Processes experience elevated CPU throttling.
expr: >-
sum(increase(container_cpu_cfs_throttled_periods_total{container!="",
job="kubelet", metrics_path="/metrics/cadvisor", }[5m])) without
(id, metrics_path, name, image, endpoint, job, node)
/
sum(increase(container_cpu_cfs_periods_total{job="kubelet",
metrics_path="/metrics/cadvisor", }[5m])) without (id, metrics_path,
name, image, endpoint, job, node)
> ( 25 / 100 )
for: 15m
labels:
severity: info
- name: kubernetes-storage
rules:
- alert: KubePersistentVolumeFillingUp
annotations:
description: >-
The PersistentVolume claimed by {{ $labels.persistentvolumeclaim
}} in Namespace {{ $labels.namespace }} {{ with $labels.cluster
-}} on Cluster {{ . }} {{- end }} is only {{ $value |
humanizePercentage }} free.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumefillingup
summary: PersistentVolume is filling up.
expr: >-
(
kubelet_volume_stats_available_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
/
kubelet_volume_stats_capacity_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
) < 0.03
and
kubelet_volume_stats_used_bytes{job="kubelet", namespace=~".*",
metrics_path="/metrics"} > 0
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_access_mode{ access_mode="ReadOnlyMany"}
== 1
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_labels{label_excluded_from_alerts="true"}
== 1
for: 1m
labels:
severity: critical
- alert: KubePersistentVolumeFillingUp
annotations:
description: >-
Based on recent sampling, the PersistentVolume claimed by {{
$labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace
}} {{ with $labels.cluster -}} on Cluster {{ . }} {{- end }} is
expected to fill up within four days. Currently {{ $value |
humanizePercentage }} is available.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumefillingup
summary: PersistentVolume is filling up.
expr: >-
(
kubelet_volume_stats_available_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
/
kubelet_volume_stats_capacity_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
) < 0.15
and
kubelet_volume_stats_used_bytes{job="kubelet", namespace=~".*",
metrics_path="/metrics"} > 0
and
predict_linear(kubelet_volume_stats_available_bytes{job="kubelet",
namespace=~".*", metrics_path="/metrics"}[6h], 4 * 24 * 3600) < 0
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_access_mode{ access_mode="ReadOnlyMany"}
== 1
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_labels{label_excluded_from_alerts="true"}
== 1
for: 1h
labels:
severity: warning
- alert: KubePersistentVolumeInodesFillingUp
annotations:
description: >-
The PersistentVolume claimed by {{ $labels.persistentvolumeclaim
}} in Namespace {{ $labels.namespace }} {{ with $labels.cluster
-}} on Cluster {{ . }} {{- end }} only has {{ $value |
humanizePercentage }} free inodes.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumeinodesfillingup
summary: PersistentVolumeInodes are filling up.
expr: >-
(
kubelet_volume_stats_inodes_free{job="kubelet", namespace=~".*", metrics_path="/metrics"}
/
kubelet_volume_stats_inodes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
) < 0.03
and
kubelet_volume_stats_inodes_used{job="kubelet", namespace=~".*",
metrics_path="/metrics"} > 0
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_access_mode{ access_mode="ReadOnlyMany"}
== 1
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_labels{label_excluded_from_alerts="true"}
== 1
for: 1m
labels:
severity: critical
- alert: KubePersistentVolumeInodesFillingUp
annotations:
description: >-
Based on recent sampling, the PersistentVolume claimed by {{
$labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace
}} {{ with $labels.cluster -}} on Cluster {{ . }} {{- end }} is
expected to run out of inodes within four days. Currently {{
$value | humanizePercentage }} of its inodes are free.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumeinodesfillingup
summary: PersistentVolumeInodes are filling up.
expr: >-
(
kubelet_volume_stats_inodes_free{job="kubelet", namespace=~".*", metrics_path="/metrics"}
/
kubelet_volume_stats_inodes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
) < 0.15
and
kubelet_volume_stats_inodes_used{job="kubelet", namespace=~".*",
metrics_path="/metrics"} > 0
and
predict_linear(kubelet_volume_stats_inodes_free{job="kubelet",
namespace=~".*", metrics_path="/metrics"}[6h], 4 * 24 * 3600) < 0
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_access_mode{ access_mode="ReadOnlyMany"}
== 1
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_labels{label_excluded_from_alerts="true"}
== 1
for: 1h
labels:
severity: warning
- alert: KubePersistentVolumeErrors
annotations:
description: >-
The persistent volume {{ $labels.persistentvolume }} {{ with
$labels.cluster -}} on Cluster {{ . }} {{- end }} has status {{
$labels.phase }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumeerrors
summary: PersistentVolume is having issues with provisioning.
expr: >-
kube_persistentvolume_status_phase{phase=~"Failed|Pending",job="kube-state-metrics"}
> 0
for: 5m
labels:
severity: critical
- name: kubernetes-system
rules:
- alert: KubeVersionMismatch
annotations:
description: >-
There are {{ $value }} different semantic versions of Kubernetes
components running on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeversionmismatch
summary: Different semantic versions of Kubernetes components running.
expr: >-
count by (cluster) (count by (git_version,cluster)
(label_replace(kubernetes_build_info{job!~"kube-dns|coredns"},"git_version","$1","git_version","(v[0-9]*.[0-9]*).*")))
> 1
for: 15m
labels:
severity: warning
- alert: KubeClientErrors
annotations:
description: >-
Kubernetes API server client '{{ $labels.job }}/{{
$labels.instance }}' is experiencing {{ $value |
humanizePercentage }} errors on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeclienterrors
summary: Kubernetes API server client is experiencing errors.
expr: >-
(sum(rate(rest_client_requests_total{job="apiserver",code=~"5.."}[5m]))
by (instance,job,namespace,cluster)
/
sum(rate(rest_client_requests_total{job="apiserver"}[5m])) by
(instance,job,namespace,cluster))
> 0.01
for: 15m
labels:
severity: warning
- name: kubernetes-system-apiserver
rules:
- alert: KubeClientCertificateExpiration
annotations:
description: >-
A client certificate used to authenticate to kubernetes apiserver
is expiring in less than 7.0 days on cluster {{ $labels.cluster
}}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeclientcertificateexpiration
summary: Client certificate is about to expire.
expr: >-
histogram_quantile(0.01, sum without (namespace, service, endpoint)
(rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m])))
< 604800
and
on (job,instance,cluster)
apiserver_client_certificate_expiration_seconds_count{job="apiserver"}
> 0
for: 5m
labels:
severity: warning
- alert: KubeClientCertificateExpiration
annotations:
description: >-
A client certificate used to authenticate to kubernetes apiserver
is expiring in less than 24.0 hours on cluster {{ $labels.cluster
}}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeclientcertificateexpiration
summary: Client certificate is about to expire.
expr: >-
histogram_quantile(0.01, sum without (namespace, service, endpoint)
(rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m])))
< 86400
and
on (job,instance,cluster)
apiserver_client_certificate_expiration_seconds_count{job="apiserver"}
> 0
for: 5m
labels:
severity: critical
- alert: KubeAggregatedAPIErrors
annotations:
description: >-
Kubernetes aggregated API {{ $labels.instance }}/{{ $labels.name
}} has reported {{ $labels.reason }} errors on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeaggregatedapierrors
summary: Kubernetes aggregated API has reported errors.
expr: >-
sum by
(instance,name,reason,cluster)(increase(aggregator_unavailable_apiservice_total{job="apiserver"}[1m]))
> 0
for: 10m
labels:
severity: warning
- alert: KubeAggregatedAPIDown
annotations:
description: >-
Kubernetes aggregated API {{ $labels.name }}/{{ $labels.namespace
}} has been only {{ $value | humanize }}% available over the last
10m on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeaggregatedapidown
summary: Kubernetes aggregated API is down.
expr: >-
(1 - max by
(name,namespace,cluster)(avg_over_time(aggregator_unavailable_apiservice{job="apiserver"}[10m])))
* 100 < 85
for: 5m
labels:
severity: warning
- alert: KubeAPIDown
annotations:
description: KubeAPI has disappeared from Prometheus target discovery.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapidown
summary: Target disappeared from Prometheus target discovery.
expr: absent(up{job="apiserver"} == 1)
for: 15m
labels:
severity: critical
- alert: KubeAPITerminatedRequests
annotations:
description: >-
The kubernetes apiserver has terminated {{ $value |
humanizePercentage }} of its incoming requests on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapiterminatedrequests
summary: >-
The kubernetes apiserver has terminated {{ $value |
humanizePercentage }} of its incoming requests.
expr: >-
sum by (cluster)
(rate(apiserver_request_terminations_total{job="apiserver"}[10m])) /
( sum by (cluster)
(rate(apiserver_request_total{job="apiserver"}[10m])) + sum by
(cluster)
(rate(apiserver_request_terminations_total{job="apiserver"}[10m])) )
> 0.20
for: 5m
labels:
severity: warning
- name: kubernetes-system-controller-manager
rules:
- alert: KubeControllerManagerDown
annotations:
description: >-
KubeControllerManager has disappeared from Prometheus target
discovery.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubecontrollermanagerdown
summary: Target disappeared from Prometheus target discovery.
expr: absent(up{job="kube-controller-manager"} == 1)
for: 15m
labels:
severity: critical
- name: kubernetes-system-kubelet
rules:
- alert: KubeNodeNotReady
annotations:
description: >-
{{ $labels.node }} has been unready for more than 15 minutes on
cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubenodenotready
summary: Node is not ready.
expr: >-
kube_node_status_condition{job="kube-state-metrics",condition="Ready",status="true"}
== 0
for: 15m
labels:
severity: warning
- alert: KubeNodeUnreachable
annotations:
description: >-
{{ $labels.node }} is unreachable and some workloads may be
rescheduled on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubenodeunreachable
summary: Node is unreachable.
expr: >-
(kube_node_spec_taint{job="kube-state-metrics",key="node.kubernetes.io/unreachable",effect="NoSchedule"}
unless ignoring(key,value)
kube_node_spec_taint{job="kube-state-metrics",key=~"ToBeDeletedByClusterAutoscaler|cloud.google.com/impending-node-termination|aws-node-termination-handler/spot-itn"})
== 1
for: 15m
labels:
severity: warning
- alert: KubeletTooManyPods
annotations:
description: >-
Kubelet '{{ $labels.node }}' is running at {{ $value |
humanizePercentage }} of its Pod capacity on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubelettoomanypods
summary: Kubelet is running at capacity.
expr: |-
count by (node,cluster) (
(kube_pod_status_phase{job="kube-state-metrics", phase="Running"} == 1)
* on (namespace,pod,cluster) group_left (node)
group by (namespace,pod,node,cluster) (
kube_pod_info{job="kube-state-metrics"}
)
)
/
max by (node,cluster) (
kube_node_status_capacity{job="kube-state-metrics", resource="pods"} != 1
) > 0.95
for: 15m
labels:
severity: info
- alert: KubeNodeReadinessFlapping
annotations:
description: >-
The readiness status of node {{ $labels.node }} has changed {{
$value }} times in the last 15 minutes on cluster {{
$labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubenodereadinessflapping
summary: Node readiness status is flapping.
expr: >-
sum(changes(kube_node_status_condition{job="kube-state-metrics",status="true",condition="Ready"}[15m]))
by (node,cluster) > 2
for: 15m
labels:
severity: warning
- alert: KubeletPlegDurationHigh
annotations:
description: >-
The Kubelet Pod Lifecycle Event Generator has a 99th percentile
duration of {{ $value }} seconds on node {{ $labels.node }} on
cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletplegdurationhigh
summary: >-
Kubelet Pod Lifecycle Event Generator is taking too long to
relist.
expr: >-
node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile{quantile="0.99"}
>= 10
for: 5m
labels:
severity: warning
- alert: KubeletPodStartUpLatencyHigh
annotations:
description: >-
Kubelet Pod startup 99th percentile latency is {{ $value }}
seconds on node {{ $labels.node }} on cluster {{ $labels.cluster
}}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletpodstartuplatencyhigh
summary: Kubelet Pod startup latency is too high.
expr: >-
histogram_quantile(0.99,
sum(rate(kubelet_pod_worker_duration_seconds_bucket{job="kubelet",
metrics_path="/metrics"}[5m])) by (instance,le,cluster)) * on
(instance,cluster) group_left(node) kubelet_node_name{job="kubelet",
metrics_path="/metrics"} > 60
for: 15m
labels:
severity: warning
- alert: KubeletClientCertificateExpiration
annotations:
description: >-
Client certificate for Kubelet on node {{ $labels.node }} expires
in {{ $value | humanizeDuration }} on cluster {{ $labels.cluster
}}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletclientcertificateexpiration
summary: Kubelet client certificate is about to expire.
expr: kubelet_certificate_manager_client_ttl_seconds < 604800
labels:
severity: warning
- alert: KubeletClientCertificateExpiration
annotations:
description: >-
Client certificate for Kubelet on node {{ $labels.node }} expires
in {{ $value | humanizeDuration }} on cluster {{ $labels.cluster
}}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletclientcertificateexpiration
summary: Kubelet client certificate is about to expire.
expr: kubelet_certificate_manager_client_ttl_seconds < 86400
labels:
severity: critical
- alert: KubeletServerCertificateExpiration
annotations:
description: >-
Server certificate for Kubelet on node {{ $labels.node }} expires
in {{ $value | humanizeDuration }} on cluster {{ $labels.cluster
}}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletservercertificateexpiration
summary: Kubelet server certificate is about to expire.
expr: kubelet_certificate_manager_server_ttl_seconds < 604800
labels:
severity: warning
- alert: KubeletServerCertificateExpiration
annotations:
description: >-
Server certificate for Kubelet on node {{ $labels.node }} expires
in {{ $value | humanizeDuration }} on cluster {{ $labels.cluster
}}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletservercertificateexpiration
summary: Kubelet server certificate is about to expire.
expr: kubelet_certificate_manager_server_ttl_seconds < 86400
labels:
severity: critical
- alert: KubeletClientCertificateRenewalErrors
annotations:
description: >-
Kubelet on node {{ $labels.node }} has failed to renew its client
certificate ({{ $value | humanize }} errors in the last 5 minutes)
on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletclientcertificaterenewalerrors
summary: Kubelet has failed to renew its client certificate.
expr: >-
increase(kubelet_certificate_manager_client_expiration_renew_errors[5m])
> 0
for: 15m
labels:
severity: warning
- alert: KubeletServerCertificateRenewalErrors
annotations:
description: >-
Kubelet on node {{ $labels.node }} has failed to renew its server
certificate ({{ $value | humanize }} errors in the last 5 minutes)
on cluster {{ $labels.cluster }}.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletservercertificaterenewalerrors
summary: Kubelet has failed to renew its server certificate.
expr: increase(kubelet_server_expiration_renew_errors[5m]) > 0
for: 15m
labels:
severity: warning
- alert: KubeletDown
annotations:
description: Kubelet has disappeared from Prometheus target discovery.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletdown
summary: Target disappeared from Prometheus target discovery.
expr: absent(up{job="kubelet", metrics_path="/metrics"} == 1)
for: 15m
labels:
severity: critical
- name: kubernetes-system-scheduler
rules:
- alert: KubeSchedulerDown
annotations:
description: KubeScheduler has disappeared from Prometheus target discovery.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeschedulerdown
summary: Target disappeared from Prometheus target discovery.
expr: absent(up{job="kube-scheduler"} == 1)
for: 15m
labels:
severity: critical
- name: node-exporter
rules:
- alert: NodeFilesystemSpaceFillingUp
annotations:
description: >-
Filesystem on {{ $labels.device }}, mounted on {{
$labels.mountpoint }}, at {{ $labels.instance }} has only {{
printf "%.2f" $value }}% available space left and is filling up.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemspacefillingup
summary: >-
Filesystem is predicted to run out of space within the next 24
hours.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 15
and
predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""}[6h], 24*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: warning
- alert: NodeFilesystemSpaceFillingUp
annotations:
description: >-
Filesystem on {{ $labels.device }}, mounted on {{
$labels.mountpoint }}, at {{ $labels.instance }} has only {{
printf "%.2f" $value }}% available space left and is filling up
fast.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemspacefillingup
summary: >-
Filesystem is predicted to run out of space within the next 4
hours.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 10
and
predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""}[6h], 4*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: critical
- alert: NodeFilesystemAlmostOutOfSpace
annotations:
description: >-
Filesystem on {{ $labels.device }}, mounted on {{
$labels.mountpoint }}, at {{ $labels.instance }} has only {{
printf "%.2f" $value }}% available space left.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemalmostoutofspace
summary: Filesystem has less than 5% space left.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 5
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 30m
labels:
severity: warning
- alert: NodeFilesystemAlmostOutOfSpace
annotations:
description: >-
Filesystem on {{ $labels.device }}, mounted on {{
$labels.mountpoint }}, at {{ $labels.instance }} has only {{
printf "%.2f" $value }}% available space left.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemalmostoutofspace
summary: Filesystem has less than 3% space left.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 3
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 30m
labels:
severity: critical
- alert: NodeFilesystemFilesFillingUp
annotations:
description: >-
Filesystem on {{ $labels.device }}, mounted on {{
$labels.mountpoint }}, at {{ $labels.instance }} has only {{
printf "%.2f" $value }}% available inodes left and is filling up.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemfilesfillingup
summary: >-
Filesystem is predicted to run out of inodes within the next 24
hours.
expr: |-
(
node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_files{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 40
and
predict_linear(node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""}[6h], 24*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: warning
- alert: NodeFilesystemFilesFillingUp
annotations:
description: >-
Filesystem on {{ $labels.device }}, mounted on {{
$labels.mountpoint }}, at {{ $labels.instance }} has only {{
printf "%.2f" $value }}% available inodes left and is filling up
fast.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemfilesfillingup
summary: >-
Filesystem is predicted to run out of inodes within the next 4
hours.
expr: |-
(
node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_files{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 20
and
predict_linear(node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""}[6h], 4*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: critical
- alert: NodeFilesystemAlmostOutOfFiles
annotations:
description: >-
Filesystem on {{ $labels.device }}, mounted on {{
$labels.mountpoint }}, at {{ $labels.instance }} has only {{
printf "%.2f" $value }}% available inodes left.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemalmostoutoffiles
summary: Filesystem has less than 5% inodes left.
expr: |-
(
node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_files{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 5
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: warning
- alert: NodeFilesystemAlmostOutOfFiles
annotations:
description: >-
Filesystem on {{ $labels.device }}, mounted on {{
$labels.mountpoint }}, at {{ $labels.instance }} has only {{
printf "%.2f" $value }}% available inodes left.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemalmostoutoffiles
summary: Filesystem has less than 3% inodes left.
expr: |-
(
node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_files{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 3
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: critical
- alert: NodeNetworkReceiveErrs
annotations:
description: >-
{{ $labels.instance }} interface {{ $labels.device }} has
encountered {{ printf "%.0f" $value }} receive errors in the last
two minutes.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodenetworkreceiveerrs
summary: Network interface is reporting many receive errors.
expr: >-
rate(node_network_receive_errs_total{job="node-exporter"}[2m]) /
rate(node_network_receive_packets_total{job="node-exporter"}[2m]) >
0.01
for: 1h
labels:
severity: warning
- alert: NodeNetworkTransmitErrs
annotations:
description: >-
{{ $labels.instance }} interface {{ $labels.device }} has
encountered {{ printf "%.0f" $value }} transmit errors in the last
two minutes.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodenetworktransmiterrs
summary: Network interface is reporting many transmit errors.
expr: >-
rate(node_network_transmit_errs_total{job="node-exporter"}[2m]) /
rate(node_network_transmit_packets_total{job="node-exporter"}[2m]) >
0.01
for: 1h
labels:
severity: warning
- alert: NodeHighNumberConntrackEntriesUsed
annotations:
description: >-
{{ $labels.instance }} {{ $value | humanizePercentage }} of
conntrack entries are used.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodehighnumberconntrackentriesused
summary: Number of conntrack are getting close to the limit.
expr: >-
(node_nf_conntrack_entries{job="node-exporter"} /
node_nf_conntrack_entries_limit) > 0.75
labels:
severity: warning
- alert: NodeTextFileCollectorScrapeError
annotations:
description: >-
Node Exporter text file collector on {{ $labels.instance }} failed
to scrape.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodetextfilecollectorscrapeerror
summary: Node Exporter text file collector failed to scrape.
expr: node_textfile_scrape_error{job="node-exporter"} == 1
labels:
severity: warning
- alert: NodeClockSkewDetected
annotations:
description: >-
Clock at {{ $labels.instance }} is out of sync by more than 0.05s.
Ensure NTP is configured correctly on this host.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodeclockskewdetected
summary: Clock skew detected.
expr: |-
(
node_timex_offset_seconds{job="node-exporter"} > 0.05
and
deriv(node_timex_offset_seconds{job="node-exporter"}[5m]) >= 0
)
or
(
node_timex_offset_seconds{job="node-exporter"} < -0.05
and
deriv(node_timex_offset_seconds{job="node-exporter"}[5m]) <= 0
)
for: 10m
labels:
severity: warning
- alert: NodeClockNotSynchronising
annotations:
description: >-
Clock at {{ $labels.instance }} is not synchronising. Ensure NTP
is configured on this host.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodeclocknotsynchronising
summary: Clock not synchronising.
expr: |-
min_over_time(node_timex_sync_status{job="node-exporter"}[5m]) == 0
and
node_timex_maxerror_seconds{job="node-exporter"} >= 16
for: 10m
labels:
severity: warning
- alert: NodeRAIDDegraded
annotations:
description: >-
RAID array '{{ $labels.device }}' at {{ $labels.instance }} is in
degraded state due to one or more disks failures. Number of spare
drives is insufficient to fix issue automatically.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/noderaiddegraded
summary: RAID Array is degraded.
expr: >-
node_md_disks_required{job="node-exporter",device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}
- ignoring (state)
(node_md_disks{state="active",job="node-exporter",device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"})
> 0
for: 15m
labels:
severity: critical
- alert: NodeRAIDDiskFailure
annotations:
description: >-
At least one device in RAID array at {{ $labels.instance }}
failed. Array '{{ $labels.device }}' needs attention and possibly
a disk swap.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/noderaiddiskfailure
summary: Failed device in RAID array.
expr: >-
node_md_disks{state="failed",job="node-exporter",device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}
> 0
labels:
severity: warning
- alert: NodeFileDescriptorLimit
annotations:
description: >-
File descriptors limit at {{ $labels.instance }} is currently at
{{ printf "%.2f" $value }}%.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefiledescriptorlimit
summary: Kernel is predicted to exhaust file descriptors limit soon.
expr: |-
(
node_filefd_allocated{job="node-exporter"} * 100 / node_filefd_maximum{job="node-exporter"} > 70
)
for: 15m
labels:
severity: warning
- alert: NodeFileDescriptorLimit
annotations:
description: >-
File descriptors limit at {{ $labels.instance }} is currently at
{{ printf "%.2f" $value }}%.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodefiledescriptorlimit
summary: Kernel is predicted to exhaust file descriptors limit soon.
expr: |-
(
node_filefd_allocated{job="node-exporter"} * 100 / node_filefd_maximum{job="node-exporter"} > 90
)
for: 15m
labels:
severity: critical
- alert: NodeCPUHighUsage
annotations:
description: >
CPU usage at {{ $labels.instance }} has been above 90% for the
last 15 minutes, is currently at {{ printf "%.2f" $value }}%.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodecpuhighusage
summary: High CPU usage.
expr: >-
sum without(mode) (avg without (cpu)
(rate(node_cpu_seconds_total{job="node-exporter",
mode!~"idle|iowait"}[2m]))) * 100 > 90
for: 15m
labels:
severity: info
- alert: NodeSystemSaturation
annotations:
description: >
System load per core at {{ $labels.instance }} has been above 2
for the last 15 minutes, is currently at {{ printf "%.2f" $value
}}.
This might indicate this instance resources saturation and can
cause it becoming unresponsive.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodesystemsaturation
summary: System saturated, load per core is very high.
expr: >-
node_load1{job="node-exporter"}
/ count without (cpu, mode)
(node_cpu_seconds_total{job="node-exporter", mode="idle"}) > 2
for: 15m
labels:
severity: warning
- alert: NodeMemoryMajorPagesFaults
annotations:
description: >
Memory major pages are occurring at very high rate at {{
$labels.instance }}, 500 major page faults per second for the last
15 minutes, is currently at {{ printf "%.2f" $value }}.
Please check that there is enough memory available at this
instance.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodememorymajorpagesfaults
summary: Memory major page faults are occurring at very high rate.
expr: rate(node_vmstat_pgmajfault{job="node-exporter"}[5m]) > 500
for: 15m
labels:
severity: warning
- alert: NodeMemoryHighUtilization
annotations:
description: >
Memory is filling up at {{ $labels.instance }}, has been above 90%
for the last 15 minutes, is currently at {{ printf "%.2f" $value
}}%.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodememoryhighutilization
summary: Host is running out of memory.
expr: >-
100 - (node_memory_MemAvailable_bytes{job="node-exporter"} /
node_memory_MemTotal_bytes{job="node-exporter"} * 100) > 90
for: 15m
labels:
severity: warning
- alert: NodeDiskIOSaturation
annotations:
description: >
Disk IO queue (aqu-sq) is high on {{ $labels.device }} at {{
$labels.instance }}, has been above 10 for the last 30 minutes, is
currently at {{ printf "%.2f" $value }}.
This symptom might indicate disk saturation.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodediskiosaturation
summary: Disk IO queue is high.
expr: >-
rate(node_disk_io_time_weighted_seconds_total{job="node-exporter",
device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}[5m])
> 10
for: 30m
labels:
severity: warning
- alert: NodeSystemdServiceFailed
annotations:
description: >-
Systemd service {{ $labels.name }} has entered failed state at {{
$labels.instance }}
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodesystemdservicefailed
summary: Systemd service has entered failed state.
expr: node_systemd_unit_state{job="node-exporter", state="failed"} == 1
for: 5m
labels:
severity: warning
- alert: NodeBondingDegraded
annotations:
description: >-
Bonding interface {{ $labels.master }} on {{ $labels.instance }}
is in degraded state due to one or more slave failures.
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/node/nodebondingdegraded
summary: Bonding interface is degraded
expr: (node_bonding_slaves - node_bonding_active) != 0
for: 5m
labels:
severity: warning
- name: node-exporter.rules
rules:
- expr: |-
count without (cpu, mode) (
node_cpu_seconds_total{job="node-exporter",mode="idle"}
)
record: instance:node_num_cpu:sum
- expr: |-
1 - avg without (cpu) (
sum without (mode) (rate(node_cpu_seconds_total{job="node-exporter", mode=~"idle|iowait|steal"}[5m]))
)
record: instance:node_cpu_utilisation:rate5m
- expr: |-
(
node_load1{job="node-exporter"}
/
instance:node_num_cpu:sum{job="node-exporter"}
)
record: instance:node_load1_per_cpu:ratio
- expr: |-
1 - (
(
node_memory_MemAvailable_bytes{job="node-exporter"}
or
(
node_memory_Buffers_bytes{job="node-exporter"}
+
node_memory_Cached_bytes{job="node-exporter"}
+
node_memory_MemFree_bytes{job="node-exporter"}
+
node_memory_Slab_bytes{job="node-exporter"}
)
)
/
node_memory_MemTotal_bytes{job="node-exporter"}
)
record: instance:node_memory_utilisation:ratio
- expr: rate(node_vmstat_pgmajfault{job="node-exporter"}[5m])
record: instance:node_vmstat_pgmajfault:rate5m
- expr: >-
rate(node_disk_io_time_seconds_total{job="node-exporter",
device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}[5m])
record: instance_device:node_disk_io_time_seconds:rate5m
- expr: >-
rate(node_disk_io_time_weighted_seconds_total{job="node-exporter",
device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}[5m])
record: instance_device:node_disk_io_time_weighted_seconds:rate5m
- expr: |-
sum without (device) (
rate(node_network_receive_bytes_total{job="node-exporter", device!="lo"}[5m])
)
record: instance:node_network_receive_bytes_excluding_lo:rate5m
- expr: |-
sum without (device) (
rate(node_network_transmit_bytes_total{job="node-exporter", device!="lo"}[5m])
)
record: instance:node_network_transmit_bytes_excluding_lo:rate5m
- expr: |-
sum without (device) (
rate(node_network_receive_drop_total{job="node-exporter", device!="lo"}[5m])
)
record: instance:node_network_receive_drop_excluding_lo:rate5m
- expr: |-
sum without (device) (
rate(node_network_transmit_drop_total{job="node-exporter", device!="lo"}[5m])
)
record: instance:node_network_transmit_drop_excluding_lo:rate5m
- name: node-network
rules:
- alert: NodeNetworkInterfaceFlapping
annotations:
description: >-
Network interface "{{ $labels.device }}" changing its up status
often on node-exporter {{ $labels.namespace }}/{{ $labels.pod }}
runbook_url: >-
https://runbooks.prometheus-operator.dev/runbooks/general/nodenetworkinterfaceflapping
summary: Network interface is often changing its status
expr: >-
changes(node_network_up{job="node-exporter",device!~"veth.+"}[2m]) >
2
for: 2m
labels:
severity: warning
- name: node.rules
rules:
- expr: |-
topk by (namespace,pod,cluster) (1,
max by (node,namespace,pod,cluster) (
label_replace(kube_pod_info{job="kube-state-metrics",node!=""}, "pod", "$1", "pod", "(.*)")
))
record: 'node_namespace_pod:kube_pod_info:'
- expr: |-
count by (node,cluster) (
node_cpu_seconds_total{mode="idle",job="node-exporter"}
* on (namespace,pod,cluster) group_left(node)
topk by (namespace,pod,cluster) (1, node_namespace_pod:kube_pod_info:)
)
record: node:node_num_cpu:sum
- expr: |-
sum(
node_memory_MemAvailable_bytes{job="node-exporter"} or
(
node_memory_Buffers_bytes{job="node-exporter"} +
node_memory_Cached_bytes{job="node-exporter"} +
node_memory_MemFree_bytes{job="node-exporter"} +
node_memory_Slab_bytes{job="node-exporter"}
)
) by (cluster)
record: ':node_memory_MemAvailable_bytes:sum'
- expr: |-
avg by (node,cluster) (
sum without (mode) (
rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal",job="node-exporter"}[5m])
)
)
record: node:node_cpu_utilization:ratio_rate5m
- expr: |-
avg by (cluster) (
node:node_cpu_utilization:ratio_rate5m
)
record: cluster:node_cpu:ratio_rate5m
- name: vm-health
rules:
- alert: TooManyRestarts
annotations:
description: >
Job {{ $labels.job }} (instance {{ $labels.instance }}) has
restarted more than twice in the last 15 minutes. It might be
crashlooping.
summary: >-
{{ $labels.job }} too many restarts (instance {{ $labels.instance
}})
expr: >-
changes(process_start_time_seconds{job=~".*(victoriametrics|vmselect|vminsert|vmstorage|vmagent|vmalert|vmsingle|vmalertmanager|vmauth).*"}[15m])
> 2
labels:
severity: critical
- alert: ServiceDown
annotations:
description: >-
{{ $labels.instance }} of job {{ $labels.job }} has been down for
more than 2 minutes.
summary: Service {{ $labels.job }} is down on {{ $labels.instance }}
expr: >-
up{job=~".*(victoriametrics|vmselect|vminsert|vmstorage|vmagent|vmalert|vmsingle|vmalertmanager|vmauth).*"}
== 0
for: 2m
labels:
severity: critical
- alert: ProcessNearFDLimits
annotations:
description: >
Exhausting OS file descriptors limit can cause severe degradation
of the process.
Consider to increase the limit as fast as possible.
summary: >-
Number of free file descriptors is less than 100 for "{{
$labels.job }}"("{{ $labels.instance }}") for the last 5m
expr: (process_max_fds - process_open_fds) < 100
for: 5m
labels:
severity: critical
- alert: TooHighMemoryUsage
annotations:
description: >
Too high memory usage may result into multiple issues such as OOMs
or degraded performance.
Consider to either increase available memory or decrease the load
on the process.
summary: >-
It is more than 80% of memory used by "{{ $labels.job }}"("{{
$labels.instance }}")
expr: >-
(min_over_time(process_resident_memory_anon_bytes[10m]) /
vm_available_memory_bytes) > 0.8
for: 5m
labels:
severity: critical
- alert: TooHighCPUUsage
annotations:
description: >
Too high CPU usage may be a sign of insufficient resources and
make process unstable. Consider to either increase available CPU
resources or decrease the load on the process.
summary: >-
More than 90% of CPU is used by "{{ $labels.job }}"("{{
$labels.instance }}") during the last 5m
expr: >-
rate(process_cpu_seconds_total[5m]) / process_cpu_cores_available >
0.9
for: 5m
labels:
severity: critical
- alert: TooHighGoroutineSchedulingLatency
annotations:
description: >
Go runtime is unable to schedule goroutines execution in
acceptable time. This is usually a sign of insufficient CPU
resources or CPU throttling. Verify that service has enough CPU
resources. Otherwise, the service could work unreliably with
delays in processing.
summary: >-
"{{ $labels.job }}"("{{ $labels.instance }}") has insufficient CPU
resources for >15m
expr: >-
histogram_quantile(0.99,
sum(rate(go_sched_latencies_seconds_bucket[5m])) by
(le,job,instance,cluster)) > 0.1
for: 15m
labels:
severity: critical
- alert: TooManyLogs
annotations:
description: >
Logging rate for job \"{{ $labels.job }}\" ({{ $labels.instance
}}) is {{ $value }} for last 15m. Worth to check logs for specific
error messages.
summary: >-
Too many logs printed for job "{{ $labels.job }}" ({{
$labels.instance }})
expr: >-
sum(increase(vm_log_messages_total{level="error"}[5m])) without
(app_version, location) > 0
for: 15m
labels:
severity: warning
- alert: TooManyTSIDMisses
annotations:
description: >
The rate of TSID misses during query lookups is too high for \"{{
$labels.job }}\" ({{ $labels.instance }}).
Make sure you're running VictoriaMetrics of v1.85.3 or higher.
Related issue
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/3502
summary: >-
Too many TSID misses for job "{{ $labels.job }}" ({{
$labels.instance }})
expr: rate(vm_missing_tsids_for_metric_id_total[5m]) > 0
for: 10m
labels:
severity: critical
- alert: ConcurrentInsertsHitTheLimit
annotations:
description: >
The limit of concurrent inserts on instance {{ $labels.instance }}
depends on the number of CPUs.
Usually, when component constantly hits the limit it is likely the
component is overloaded and requires more CPU.
In some cases for components like vmagent or vminsert the alert
might trigger if there are too many clients
making write attempts. If vmagent's or vminsert's CPU usage and
network saturation are at normal level, then
it might be worth adjusting `-maxConcurrentInserts` cmd-line flag.
summary: >-
{{ $labels.job }} on instance {{ $labels.instance }} is constantly
hitting concurrent inserts limit
expr: >-
avg_over_time(vm_concurrent_insert_current[1m]) >=
vm_concurrent_insert_capacity
for: 15m
labels:
severity: warning
- alert: IndexDBRecordsDrop
annotations:
description: >
VictoriaMetrics could skip registering new timeseries during
ingestion if they fail the validation process.
For example, `reason=too_long_item` means that time series cannot
exceed 64KB. Please, reduce the number
of labels or label values for such series. Or enforce these limits
via `-maxLabelsPerTimeseries` and
`-maxLabelValueLen` command-line flags.
summary: >-
IndexDB skipped registering items during data ingestion with
reason={{ $labels.reason }}.
expr: increase(vm_indexdb_items_dropped_total[5m]) > 0
labels:
severity: critical
- alert: RowsRejectedOnIngestion
annotations:
description: >-
Ingested rows on instance "{{ $labels.instance }}" are rejected
due to the following reason: "{{ $labels.reason }}"
summary: >-
Some rows are rejected on "{{ $labels.instance }}" on ingestion
attempt
expr: rate(vm_rows_ignored_total[5m]) > 0
for: 15m
labels:
severity: warning
- concurrency: 2
interval: 30s
name: vmagent
rules:
- alert: PersistentQueueIsDroppingData
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=49&var-instance={{
$labels.instance }}
description: >-
Vmagent dropped {{ $value | humanize1024 }} from persistent queue
on instance {{ $labels.instance }} for the last 10m.
summary: >-
Instance {{ $labels.instance }} is dropping data from persistent
queue
expr: >-
sum(increase(vm_persistentqueue_bytes_dropped_total[5m])) without
(path) > 0
for: 10m
labels:
severity: critical
- alert: RejectedRemoteWriteDataBlocksAreDropped
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=79&var-instance={{
$labels.instance }}
description: >-
Job "{{ $labels.job }}" on instance {{ $labels.instance }} drops
the rejected by remote-write server data blocks. Check the logs to
find the reason for rejects.
summary: >-
Vmagent is dropping data blocks that are rejected by remote
storage
expr: >-
sum(increase(vmagent_remotewrite_packets_dropped_total[5m])) without
(url) > 0
for: 15m
labels:
severity: warning
- alert: TooManyScrapeErrors
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=31&var-instance={{
$labels.instance }}
description: >-
Job "{{ $labels.job }}" on instance {{ $labels.instance }} fails
to scrape targets for last 15m
summary: Vmagent fails to scrape one or more targets
expr: increase(vm_promscrape_scrapes_failed_total[5m]) > 0
for: 15m
labels:
severity: warning
- alert: TooManyWriteErrors
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=77&var-instance={{
$labels.instance }}
description: >-
Job "{{ $labels.job }}" on instance {{ $labels.instance }}
responds with errors to write requests for last 15m.
summary: Vmagent responds with too many errors on data ingestion protocols
expr: >-
(sum(increase(vm_ingestserver_request_errors_total[5m])) without
(name,net,type)
+
sum(increase(vmagent_http_request_errors_total[5m])) without
(path,protocol)) > 0
for: 15m
labels:
severity: warning
- alert: TooManyRemoteWriteErrors
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=61&var-instance={{
$labels.instance }}
description: >-
Vmagent fails to push data via remote write protocol to
destination "{{ $labels.url }}"
Ensure that destination is up and reachable.
summary: >-
Job "{{ $labels.job }}" on instance {{ $labels.instance }} fails
to push to remote storage
expr: rate(vmagent_remotewrite_retries_count_total[5m]) > 0
for: 15m
labels:
severity: warning
- alert: RemoteWriteConnectionIsSaturated
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=84&var-instance={{
$labels.instance }}
description: >-
The remote write connection between vmagent "{{ $labels.job }}"
(instance {{ $labels.instance }}) and destination "{{ $labels.url
}}" is saturated by more than 90% and vmagent won't be able to
keep up.
This usually means that `-remoteWrite.queues` command-line flag must be increased in order to increase the number of connections per each remote storage.
summary: >-
Remote write connection from "{{ $labels.job }}" (instance {{
$labels.instance }}) to {{ $labels.url }} is saturated
expr: |-
(
rate(vmagent_remotewrite_send_duration_seconds_total[5m])
/
vmagent_remotewrite_queues
) > 0.9
for: 15m
labels:
severity: warning
- alert: PersistentQueueForWritesIsSaturated
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=98&var-instance={{
$labels.instance }}
description: >-
Persistent queue writes for vmagent "{{ $labels.job }}" (instance
{{ $labels.instance }}) are saturated by more than 90% and vmagent
won't be able to keep up with flushing data on disk. In this case,
consider to decrease load on the vmagent or improve the disk
throughput.
summary: >-
Persistent queue writes for instance {{ $labels.instance }} are
saturated
expr: rate(vm_persistentqueue_write_duration_seconds_total[5m]) > 0.9
for: 15m
labels:
severity: warning
- alert: PersistentQueueForReadsIsSaturated
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=99&var-instance={{
$labels.instance }}
description: >-
Persistent queue reads for vmagent "{{ $labels.job }}" (instance
{{ $labels.instance }}) are saturated by more than 90% and vmagent
won't be able to keep up with reading data from the disk. In this
case, consider to decrease load on the vmagent or improve the disk
throughput.
summary: >-
Persistent queue reads for instance {{ $labels.instance }} are
saturated
expr: rate(vm_persistentqueue_read_duration_seconds_total[5m]) > 0.9
for: 15m
labels:
severity: warning
- alert: SeriesLimitHourReached
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=88&var-instance={{
$labels.instance }}
description: >-
Max series limit set via -remoteWrite.maxHourlySeries flag is
close to reaching the max value. Then samples for new time series
will be dropped instead of sending them to remote storage systems.
summary: Instance {{ $labels.instance }} reached 90% of the limit
expr: >-
(vmagent_hourly_series_limit_current_series /
vmagent_hourly_series_limit_max_series) > 0.9
labels:
severity: critical
- alert: SeriesLimitDayReached
annotations:
dashboard: >-
grafana.external.host/d/G7Z9GzMGz?viewPanel=90&var-instance={{
$labels.instance }}
description: >-
Max series limit set via -remoteWrite.maxDailySeries flag is close
to reaching the max value. Then samples for new time series will
be dropped instead of sending them to remote storage systems.
summary: Instance {{ $labels.instance }} reached 90% of the limit
expr: >-
(vmagent_daily_series_limit_current_series /
vmagent_daily_series_limit_max_series) > 0.9
labels:
severity: critical
- alert: ConfigurationReloadFailure
annotations:
description: >-
Configuration hot-reload failed for vmagent on instance {{
$labels.instance }}. Check vmagent's logs for detailed error
message.
summary: >-
Configuration reload failed for vmagent instance {{
$labels.instance }}
expr: |-
vm_promscrape_config_last_reload_successful != 1
or
vmagent_relabel_config_last_reload_successful != 1
labels:
severity: warning
- alert: StreamAggrFlushTimeout
annotations:
description: >-
Stream aggregation process can't keep up with the load and might
produce incorrect aggregation results. Check logs for more
details. Possible solutions: increase aggregation interval;
aggregate smaller number of series; reduce samples' ingestion rate
to stream aggregation.
summary: >-
Streaming aggregation at "{{ $labels.job }}" (instance {{
$labels.instance }}) can't be finished within the configured
aggregation interval.
expr: increase(vm_streamaggr_flush_timeouts_total[5m]) > 0
labels:
severity: warning
- alert: StreamAggrDedupFlushTimeout
annotations:
description: >-
Deduplication process can't keep up with the load and might
produce incorrect results. Check docs
https://docs.victoriametrics.com/stream-aggregation/#deduplication
and logs for more details. Possible solutions: increase
deduplication interval; deduplicate smaller number of series;
reduce samples' ingestion rate.
summary: >-
Deduplication "{{ $labels.job }}" (instance {{ $labels.instance
}}) can't be finished within configured deduplication interval.
expr: increase(vm_streamaggr_dedup_flush_timeouts_total[5m]) > 0
labels:
severity: warning
- concurrency: 2
interval: 30s
name: vmcluster
rules:
- alert: DiskRunsOutOfSpaceIn3Days
annotations:
dashboard: >-
grafana.external.host/d/oS7Bi_0Wz?viewPanel=113&var-instance={{
$labels.instance }}
description: >-
Taking into account current ingestion rate, free disk space will
be enough only for {{ $value | humanizeDuration }} on instance {{
$labels.instance }}.
Consider to limit the ingestion rate, decrease retention or scale the disk space up if possible.
summary: >-
Instance {{ $labels.instance }} will run out of disk space in 3
days
expr: |-
sum(vm_free_disk_space_bytes) without(path) /
(
rate(vm_rows_added_to_storage_total[1d]) * (
sum(vm_data_size_bytes{type!~"indexdb.*"}) without(type) /
sum(vm_rows{type!~"indexdb.*"}) without(type)
)
) < 3 * 24 * 3600 > 0
for: 30m
labels:
severity: critical
- alert: NodeBecomesReadonlyIn3Days
annotations:
dashboard: >-
grafana.external.host/d/oS7Bi_0Wz?viewPanel=113&var-instance={{
$labels.instance }}
description: >-
Taking into account current ingestion rate, free disk space and
-storage.minFreeDiskSpaceBytes instance {{ $labels.instance }}
will remain writable for {{ $value | humanizeDuration }}.
Consider to limit the ingestion rate, decrease retention or scale the disk space up if possible.
summary: Instance {{ $labels.instance }} will become read-only in 3 days
expr: >-
sum(vm_free_disk_space_bytes - vm_free_disk_space_limit_bytes)
without(path) /
(
rate(vm_rows_added_to_storage_total[1d]) * (
sum(vm_data_size_bytes{type!~"indexdb.*"}) without(type) /
sum(vm_rows{type!~"indexdb.*"}) without(type)
)
) < 3 * 24 * 3600 > 0
for: 30m
labels:
severity: warning
- alert: DiskRunsOutOfSpace
annotations:
dashboard: >-
grafana.external.host/d/oS7Bi_0Wz?viewPanel=200&var-instance={{
$labels.instance }}
description: >-
Disk utilisation on instance {{ $labels.instance }} is more than
80%.
Having less than 20% of free disk space could cripple merges processes and overall performance. Consider to limit the ingestion rate, decrease retention or scale the disk space if possible.
summary: >-
Instance {{ $labels.instance }} (job={{ $labels.job }}) will run
out of disk space soon
expr: |-
sum(vm_data_size_bytes) by (job,instance,cluster) /
(
sum(vm_free_disk_space_bytes) by (job,instance,cluster) +
sum(vm_data_size_bytes) by (job,instance,cluster)
) > 0.8
for: 30m
labels:
severity: critical
- alert: RequestErrorsToAPI
annotations:
dashboard: >-
grafana.external.host/d/oS7Bi_0Wz?viewPanel=52&var-instance={{
$labels.instance }}
description: >-
Requests to path {{ $labels.path }} are receiving errors. Please
verify if clients are sending correct requests.
summary: >-
Too many errors served for {{ $labels.job }} path {{ $labels.path
}} (instance {{ $labels.instance }})
expr: increase(vm_http_request_errors_total[5m]) > 0
for: 15m
labels:
severity: warning
show_at: dashboard
- alert: RPCErrors
annotations:
dashboard: >-
grafana.external.host/d/oS7Bi_0Wz?viewPanel=44&var-instance={{
$labels.instance }}
description: |-
RPC errors are interconnection errors between cluster components.
Possible reasons for errors are misconfiguration, overload, network blips or unreachable components.
summary: >-
Too many RPC errors for {{ $labels.job }} (instance {{
$labels.instance }})
expr: |-
(
sum(increase(vm_rpc_connection_errors_total[5m])) by (job,instance,cluster)
+
sum(increase(vm_rpc_dial_errors_total[5m])) by (job,instance,cluster)
+
sum(increase(vm_rpc_handshake_errors_total[5m])) by (job,instance,cluster)
) > 0
for: 15m
labels:
severity: warning
show_at: dashboard
- alert: TooHighChurnRate
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=102
description: |-
VM constantly creates new time series.
This effect is known as Churn Rate.
High Churn Rate tightly connected with database performance and may result in unexpected OOM's or slow queries.
summary: Churn rate is more than 10% for the last 15m
expr: |-
(
sum(rate(vm_new_timeseries_created_total[5m])) by (job,cluster)
/
sum(rate(vm_rows_inserted_total[5m])) by (job,cluster)
) > 0.1
for: 15m
labels:
severity: warning
- alert: TooHighChurnRate24h
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=102
description: >-
The number of created new time series over last 24h is 3x times
higher than current number of active series.
This effect is known as Churn Rate.
High Churn Rate tightly connected with database performance and may result in unexpected OOM's or slow queries.
summary: Too high number of new series created over last 24h
expr: >-
sum(increase(vm_new_timeseries_created_total[24h])) by (job,cluster)
>
(sum(vm_cache_entries{type="storage/hour_metric_ids"}) by
(job,cluster) * 3)
for: 15m
labels:
severity: warning
- alert: TooHighSlowInsertsRate
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=108
description: >-
High rate of slow inserts may be a sign of resource exhaustion for
the current load. It is likely more RAM is needed for optimal
handling of the current number of active time series. See also
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/3976#issuecomment-1476883183
summary: Percentage of slow inserts is more than 5% for the last 15m
expr: |-
(
sum(rate(vm_slow_row_inserts_total[5m])) by (job,cluster)
/
sum(rate(vm_rows_inserted_total[5m])) by (job,cluster)
) > 0.05
for: 15m
labels:
severity: warning
- alert: VminsertVmstorageConnectionIsSaturated
annotations:
dashboard: >-
grafana.external.host/d/oS7Bi_0Wz?viewPanel=139&var-instance={{
$labels.instance }}
description: >-
The connection between vminsert (instance {{ $labels.instance }})
and vmstorage (instance {{ $labels.addr }}) is saturated by more
than 90% and vminsert won't be able to keep up.
This usually means that more vminsert or vmstorage nodes must be added to the cluster in order to increase the total number of vminsert -> vmstorage links.
summary: >-
Connection between vminsert on {{ $labels.instance }} and
vmstorage on {{ $labels.addr }} is saturated
expr: rate(vm_rpc_send_duration_seconds_total[5m]) > 0.9
for: 15m
labels:
severity: warning
show_at: dashboard
- name: vmoperator
rules:
- alert: LogErrors
annotations:
dashboard: >-
{{ $externalURL }}/d/1H179hunk/victoriametrics-operator?ds={{
$labels.dc }}&orgId=1&viewPanel=16
description: >-
Operator has too many errors at logs: {{ $value}}, check operator
logs
summary: 'Too many errors at logs of operator: {{ $value}}'
expr: |-
sum(
rate(
operator_log_messages_total{
level="error",job=~".*((victoria.*)|vm)-?operator"
}[5m]
)
) by (cluster) > 0
for: 15m
labels:
severity: warning
show_at: dashboard
- alert: ReconcileErrors
annotations:
dashboard: >-
{{ $externalURL }}/d/1H179hunk/victoriametrics-operator?ds={{
$labels.dc }}&orgId=1&viewPanel=10
description: >-
Operator cannot parse response from k8s api server, possible bug:
{{ $value }}, check operator logs
summary: 'Too many errors at reconcile loop of operator: {{ $value}}'
expr: |-
sum(
rate(
controller_runtime_reconcile_errors_total{
job=~".*((victoria.*)|vm)-?operator"
}[5m]
)
) by (cluster) > 0
for: 10m
labels:
severity: warning
show_at: dashboard
- alert: HighQueueDepth
annotations:
dashboard: >-
{{ $externalURL }}/d/1H179hunk/victoriametrics-operator?ds={{
$labels.dc }}&orgId=1&viewPanel=20
description: >-
Operator cannot handle reconciliation load for controller: `{{-
$labels.name }}`, current depth: {{ $value }}
summary: 'Too many `{{- $labels.name }}` in queue: {{ $value }}'
expr: |-
sum(
workqueue_depth{
job=~".*((victoria.*)|vm)-?operator",
name=~"(vmagent|vmalert|vmalertmanager|vmauth|vmcluster|vmnodescrape|vmpodscrape|vmprobe|vmrule|vmservicescrape|vmsingle|vmstaticscrape)"
}
) by (name,cluster) > 10
for: 15m
labels:
severity: warning
show_at: dashboard
- alert: BadObjects
annotations:
dashboard: >-
{{ $externalURL }}/d/1H179hunk/victoriametrics-operator?ds={{
$labels.dc }}&orgId=1
description: >-
Operator got incorrect resources in controller {{
$labels.controller }}, check operator logs
summary: Incorrect `{{ $labels.controller }}` resources in the cluster
expr: |-
sum(
operator_controller_bad_objects_count{job=~".*((victoria.*)|vm)-?operator"}
) by (controller,cluster) > 0
for: 15m
labels:
severity: warning
show_at: dashboard
- concurrency: 2
interval: 30s
name: vmsingle
rules:
- alert: DiskRunsOutOfSpaceIn3Days
annotations:
dashboard: >-
grafana.external.host/d/wNf0q_kZk?viewPanel=73&var-instance={{
$labels.instance }}
description: >-
Taking into account current ingestion rate, free disk space will
be enough only for {{ $value | humanizeDuration }} on instance {{
$labels.instance }}.
Consider to limit the ingestion rate, decrease retention or scale the disk space if possible.
summary: Instance {{ $labels.instance }} will run out of disk space soon
expr: |-
sum(vm_free_disk_space_bytes) without(path) /
(
rate(vm_rows_added_to_storage_total[1d]) * (
sum(vm_data_size_bytes{type!~"indexdb.*"}) without(type) /
sum(vm_rows{type!~"indexdb.*"}) without(type)
)
) < 3 * 24 * 3600 > 0
for: 30m
labels:
severity: critical
- alert: NodeBecomesReadonlyIn3Days
annotations:
dashboard: >-
grafana.external.host/d/oS7Bi_0Wz?viewPanel=113&var-instance={{
$labels.instance }}
description: >-
Taking into account current ingestion rate and free disk space
instance {{ $labels.instance }} is writable for {{ $value |
humanizeDuration }}.
Consider to limit the ingestion rate, decrease retention or scale the disk space up if possible.
summary: Instance {{ $labels.instance }} will become read-only in 3 days
expr: >-
sum(vm_free_disk_space_bytes - vm_free_disk_space_limit_bytes)
without(path) /
(
rate(vm_rows_added_to_storage_total[1d]) * (
sum(vm_data_size_bytes{type!~"indexdb.*"}) without(type) /
sum(vm_rows{type!~"indexdb.*"}) without(type)
)
) < 3 * 24 * 3600 > 0
for: 30m
labels:
severity: warning
- alert: DiskRunsOutOfSpace
annotations:
dashboard: >-
grafana.external.host/d/wNf0q_kZk?viewPanel=53&var-instance={{
$labels.instance }}
description: >-
Disk utilisation on instance {{ $labels.instance }} is more than
80%.
Having less than 20% of free disk space could cripple merge processes and overall performance. Consider to limit the ingestion rate, decrease retention or scale the disk space if possible.
summary: >-
Instance {{ $labels.instance }} (job={{ $labels.job }}) will run
out of disk space soon
expr: |-
sum(vm_data_size_bytes) by (job,instance,cluster) /
(
sum(vm_free_disk_space_bytes) by (job,instance,cluster) +
sum(vm_data_size_bytes) by (job,instance,cluster)
) > 0.8
for: 30m
labels:
severity: critical
- alert: RequestErrorsToAPI
annotations:
dashboard: >-
grafana.external.host/d/wNf0q_kZk?viewPanel=35&var-instance={{
$labels.instance }}
description: >-
Requests to path {{ $labels.path }} are receiving errors. Please
verify if clients are sending correct requests.
summary: >-
Too many errors served for path {{ $labels.path }} (instance {{
$labels.instance }})
expr: increase(vm_http_request_errors_total[5m]) > 0
for: 15m
labels:
severity: warning
- alert: TooHighChurnRate
annotations:
dashboard: >-
grafana.external.host/d/wNf0q_kZk?viewPanel=66&var-instance={{
$labels.instance }}
description: |-
VM constantly creates new time series on "{{ $labels.instance }}".
This effect is known as Churn Rate.
High Churn Rate tightly connected with database performance and may result in unexpected OOM's or slow queries.
summary: >-
Churn rate is more than 10% on "{{ $labels.instance }}" for the
last 15m
expr: |-
(
sum(rate(vm_new_timeseries_created_total[5m])) by (instance,cluster)
/
sum(rate(vm_rows_inserted_total[5m])) by (instance,cluster)
) > 0.1
for: 15m
labels:
severity: warning
- alert: TooHighChurnRate24h
annotations:
dashboard: >-
grafana.external.host/d/wNf0q_kZk?viewPanel=66&var-instance={{
$labels.instance }}
description: >-
The number of created new time series over last 24h is 3x times
higher than current number of active series on "{{
$labels.instance }}".
This effect is known as Churn Rate.
High Churn Rate tightly connected with database performance and may result in unexpected OOM's or slow queries.
summary: >-
Too high number of new series on "{{ $labels.instance }}" created
over last 24h
expr: >-
sum(increase(vm_new_timeseries_created_total[24h])) by
(instance,cluster)
>
(sum(vm_cache_entries{type="storage/hour_metric_ids"}) by
(instance,cluster) * 3)
for: 15m
labels:
severity: warning
- alert: TooHighSlowInsertsRate
annotations:
dashboard: >-
grafana.external.host/d/wNf0q_kZk?viewPanel=68&var-instance={{
$labels.instance }}
description: >-
High rate of slow inserts on "{{ $labels.instance }}" may be a
sign of resource exhaustion for the current load. It is likely
more RAM is needed for optimal handling of the current number of
active time series. See also
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/3976#issuecomment-1476883183
summary: >-
Percentage of slow inserts is more than 5% on "{{ $labels.instance
}}" for the last 15m
expr: |-
(
sum(rate(vm_slow_row_inserts_total[5m])) by (instance,cluster)
/
sum(rate(vm_rows_inserted_total[5m])) by (instance,cluster)
) > 0.05
for: 15m
labels:
severity: warning
Обновление кластера управления
Если в кластере управления до обновления был включен “Модуль мониторинга. Компонент централизованного сбора метрик”, то после завершения обновления кластера с версии 2.9.x на 2.10.0 и выше необходимо добавить кастомные ресурсы VMRule, VMAlertmanagerConfig, VMAlert для корректной работы дашбордов в Grafana:
- В графическом интерфейсе кластера управления c помощью импорта манифестов загрузите кастомные ресурсы:
VMAlertmanagerConfig
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMAlertmanagerConfig
metadata:
name: vmalertmanagerconfig-0
namespace: clusterName
spec:
receivers:
- name: devnull
route:
receiver: devnull
Вместо clusterName в параметре namespace укажите имя кластера управления.
VMRule user
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMRule
metadata:
labels:
cluster: clusterName
monitoringid: "0"
role: user
name: vmrule-user-0
namespace: clusterName
spec:
groups: []
Вместо clusterName в параметрах cluster и namespace укажите имя кластера управления.
VMRule system
Вместо clusterName в параметрах cluster и namespace укажите имя кластера управления.
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMRule
metadata:
labels:
cluster: clusterName
monitoringid: "0"
role: system
name: vmrule-system-0
namespace: clusterName
spec:
groups:
- name: shturval-backup
rules:
- alert: VeleroBackupPartialFailures
annotations:
message: Velero backup {{ $labels.schedule }} has {{ $value | humanizePercentage
}} partialy failed backups.
expr: velero_backup_partial_failure_total{schedule!=""} / velero_backup_attempt_total{schedule!=""}
> 0.25
for: 15m
labels:
severity: warning
- alert: VeleroBackupFailures
annotations:
message: Velero backup {{ $labels.schedule }} has {{ $value | humanizePercentage
}} failed backups.
expr: velero_backup_failure_total{schedule!=""} / velero_backup_attempt_total{schedule!=""}
> 0.25
for: 15m
labels:
severity: warning
- name: x509-certificate-exporter.rules
rules:
- alert: X509ExporterReadErrors
annotations:
description: Over the last 15 minutes, this x509-certificate-exporter instance
has experienced errors reading certificate files or querying the Kubernetes
API. This could be caused by a misconfiguration if triggered when the exporter
starts.
summary: Increasing read errors for x509-certificate-exporter
expr: delta(x509_read_errors[15m]) > 0
for: 5m
labels:
severity: warning
- alert: CertificateError
annotations:
description: Certificate could not be decoded {{if $labels.secret_name }}in
Kubernetes secret "{{ $labels.secret_namespace }}/{{ $labels.secret_name
}}"{{else}}at location "{{ $labels.filepath }}"{{end}}
summary: Certificate cannot be decoded
expr: x509_cert_error > 0
for: 15m
labels:
severity: warning
- alert: CertificateRenewal
annotations:
description: Certificate for "{{ $labels.subject_CN }}" should be renewed
{{if $labels.secret_name }}in Kubernetes secret "{{ $labels.secret_namespace
}}/{{ $labels.secret_name }}"{{else}}at location "{{ $labels.filepath }}"{{end}}
summary: Certificate should be renewed
expr: (x509_cert_not_after - time()) < (28 * 86400)
for: 15m
labels:
severity: warning
- alert: CertificateExpiration
annotations:
description: Certificate for "{{ $labels.subject_CN }}" is about to expire
after {{ humanizeDuration $value }} {{if $labels.secret_name }}in Kubernetes
secret "{{ $labels.secret_namespace }}/{{ $labels.secret_name }}"{{else}}at
location "{{ $labels.filepath }}"{{end}}
summary: Certificate is about to expire
expr: (x509_cert_not_after - time()) < (14 * 86400)
for: 15m
labels:
severity: critical
- name: alertmanager.rules
rules:
- alert: AlertmanagerFailedReload
annotations:
description: Configuration has failed to load for {{ $labels.namespace }}/{{
$labels.pod}}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerfailedreload
summary: Reloading an Alertmanager configuration has failed.
expr: |-
# Without max_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
max_over_time(alertmanager_config_last_reload_successful{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m]) == 0
for: 10m
labels:
severity: critical
- alert: AlertmanagerMembersInconsistent
annotations:
description: Alertmanager {{ $labels.namespace }}/{{ $labels.pod}} has only
found {{ $value }} members of the {{$labels.job}} cluster.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagermembersinconsistent
summary: A member of an Alertmanager cluster has not found all other cluster
members.
expr: |-
# Without max_over_time, failed scrapes could create false negatives, see
# https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details.
max_over_time(alertmanager_cluster_members{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m])
< on (namespace,service,cluster) group_left
count by (namespace,service,cluster) (max_over_time(alertmanager_cluster_members{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m]))
for: 15m
labels:
severity: critical
- alert: AlertmanagerFailedToSendAlerts
annotations:
description: Alertmanager {{ $labels.namespace }}/{{ $labels.pod}} failed
to send {{ $value | humanizePercentage }} of notifications to {{ $labels.integration
}}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerfailedtosendalerts
summary: An Alertmanager instance failed to send notifications.
expr: |-
(
rate(alertmanager_notifications_failed_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m])
/
ignoring (reason) group_left rate(alertmanager_notifications_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m])
)
> 0.01
for: 5m
labels:
severity: warning
- alert: AlertmanagerClusterFailedToSendAlerts
annotations:
description: The minimum notification failure rate to {{ $labels.integration
}} sent from any instance in the {{$labels.job}} cluster is {{ $value |
humanizePercentage }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerclusterfailedtosendalerts
summary: All Alertmanager instances in a cluster failed to send notifications
to a critical integration.
expr: |-
min by (namespace,service,integration,cluster) (
rate(alertmanager_notifications_failed_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics", integration=~`.*`}[5m])
/
ignoring (reason) group_left rate(alertmanager_notifications_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics", integration=~`.*`}[5m])
)
> 0.01
for: 5m
labels:
severity: critical
- alert: AlertmanagerClusterFailedToSendAlerts
annotations:
description: The minimum notification failure rate to {{ $labels.integration
}} sent from any instance in the {{$labels.job}} cluster is {{ $value |
humanizePercentage }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerclusterfailedtosendalerts
summary: All Alertmanager instances in a cluster failed to send notifications
to a non-critical integration.
expr: |-
min by (namespace,service,integration,cluster) (
rate(alertmanager_notifications_failed_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics", integration!~`.*`}[5m])
/
ignoring (reason) group_left rate(alertmanager_notifications_total{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics", integration!~`.*`}[5m])
)
> 0.01
for: 5m
labels:
severity: warning
- alert: AlertmanagerConfigInconsistent
annotations:
description: Alertmanager instances within the {{$labels.job}} cluster have
different configurations.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerconfiginconsistent
summary: Alertmanager instances within the same cluster have different configurations.
expr: |-
count by (namespace,service,cluster) (
count_values by (namespace,service,cluster) ("config_hash", alertmanager_config_hash{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"})
)
!= 1
for: 20m
labels:
severity: critical
- alert: AlertmanagerClusterDown
annotations:
description: '{{ $value | humanizePercentage }} of Alertmanager instances
within the {{$labels.job}} cluster have been up for less than half of the
last 5m.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerclusterdown
summary: Half or more of the Alertmanager instances within the same cluster
are down.
expr: |-
(
count by (namespace,service,cluster) (
avg_over_time(up{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[5m]) < 0.5
)
/
count by (namespace,service,cluster) (
up{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}
)
)
>= 0.5
for: 5m
labels:
severity: critical
- alert: AlertmanagerClusterCrashlooping
annotations:
description: '{{ $value | humanizePercentage }} of Alertmanager instances
within the {{$labels.job}} cluster have restarted at least 5 times in the
last 10m.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/alertmanager/alertmanagerclustercrashlooping
summary: Half or more of the Alertmanager instances within the same cluster
are crashlooping.
expr: |-
(
count by (namespace,service,cluster) (
changes(process_start_time_seconds{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}[10m]) > 4
)
/
count by (namespace,service,cluster) (
up{job="vmalertmanager-shturval-metrics-collector",namespace="victoria-metrics"}
)
)
>= 0.5
for: 5m
labels:
severity: critical
- name: etcd
rules:
- alert: etcdMembersDown
annotations:
description: 'etcd cluster "{{ $labels.job }}": members are down ({{ $value
}}).'
summary: etcd cluster members are down.
expr: |-
max without (endpoint) (
sum without (instance) (up{job=~".*etcd.*"} == bool 0)
or
count without (To) (
sum without (instance) (rate(etcd_network_peer_sent_failures_total{job=~".*etcd.*"}[120s])) > 0.01
)
)
> 0
for: 10m
labels:
severity: critical
- alert: etcdInsufficientMembers
annotations:
description: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).'
summary: etcd cluster has insufficient number of members.
expr: sum(up{job=~".*etcd.*"} == bool 1) without (instance) < ((count(up{job=~".*etcd.*"})
without (instance) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
description: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance
}} has no leader.'
summary: etcd cluster has no leader.
expr: etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighNumberOfLeaderChanges
annotations:
description: 'etcd cluster "{{ $labels.job }}": {{ $value }} leader changes
within the last 15 minutes. Frequent elections may be a sign of insufficient
resources, high network latency, or disruptions by other components and
should be investigated.'
summary: etcd cluster has high number of leader changes.
expr: increase((max without (instance) (etcd_server_leader_changes_seen_total{job=~".*etcd.*"})
or 0*absent(etcd_server_leader_changes_seen_total{job=~".*etcd.*"}))[15m:1m])
>= 4
for: 5m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
description: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests
for {{ $labels.grpc_method }} failed on etcd instance {{ $labels.instance
}}.'
summary: etcd cluster has high number of failed grpc requests.
expr: |-
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code=~"Unknown|FailedPrecondition|ResourceExhausted|Internal|Unavailable|DataLoss|DeadlineExceeded"}[5m])) without (grpc_type, grpc_code)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) without (grpc_type, grpc_code)
> 1
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
description: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests
for {{ $labels.grpc_method }} failed on etcd instance {{ $labels.instance
}}.'
summary: etcd cluster has high number of failed grpc requests.
expr: |-
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code=~"Unknown|FailedPrecondition|ResourceExhausted|Internal|Unavailable|DataLoss|DeadlineExceeded"}[5m])) without (grpc_type, grpc_code)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) without (grpc_type, grpc_code)
> 5
for: 5m
labels:
severity: critical
- alert: etcdGRPCRequestsSlow
annotations:
description: 'etcd cluster "{{ $labels.job }}": 99th percentile of gRPC requests
is {{ $value }}s on etcd instance {{ $labels.instance }} for {{ $labels.grpc_method
}} method.'
summary: etcd grpc requests are slow
expr: |-
histogram_quantile(0.99, sum(rate(grpc_server_handling_seconds_bucket{job=~".*etcd.*", grpc_method!="Defragment", grpc_type="unary"}[5m])) without(grpc_type))
> 0.15
for: 10m
labels:
severity: critical
- alert: etcdMemberCommunicationSlow
annotations:
description: 'etcd cluster "{{ $labels.job }}": member communication with
{{ $labels.To }} is taking {{ $value }}s on etcd instance {{ $labels.instance
}}.'
summary: etcd cluster member communication is slow.
expr: |-
histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.15
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedProposals
annotations:
description: 'etcd cluster "{{ $labels.job }}": {{ $value }} proposal failures
within the last 30 minutes on etcd instance {{ $labels.instance }}.'
summary: etcd cluster has high number of proposal failures.
expr: rate(etcd_server_proposals_failed_total{job=~".*etcd.*"}[15m]) > 5
for: 15m
labels:
severity: warning
- alert: etcdHighFsyncDurations
annotations:
description: 'etcd cluster "{{ $labels.job }}": 99th percentile fsync durations
are {{ $value }}s on etcd instance {{ $labels.instance }}.'
summary: etcd cluster 99th percentile fsync durations are too high.
expr: |-
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcdHighFsyncDurations
annotations:
description: 'etcd cluster "{{ $labels.job }}": 99th percentile fsync durations
are {{ $value }}s on etcd instance {{ $labels.instance }}.'
summary: etcd cluster 99th percentile fsync durations are too high.
expr: |-
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 1
for: 10m
labels:
severity: critical
- alert: etcdHighCommitDurations
annotations:
description: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
summary: etcd cluster 99th percentile commit durations are too high.
expr: |-
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcdDatabaseQuotaLowSpace
annotations:
description: 'etcd cluster "{{ $labels.job }}": database size exceeds the
defined quota on etcd instance {{ $labels.instance }}, please defrag or
increase the quota as the writes to etcd will be disabled when it is full.'
summary: etcd cluster database is running full.
expr: (last_over_time(etcd_mvcc_db_total_size_in_bytes{job=~".*etcd.*"}[5m])
/ last_over_time(etcd_server_quota_backend_bytes{job=~".*etcd.*"}[5m]))*100
> 95
for: 10m
labels:
severity: critical
- alert: etcdExcessiveDatabaseGrowth
annotations:
description: 'etcd cluster "{{ $labels.job }}": Predicting running out of
disk space in the next four hours, based on write observations within the
past four hours on etcd instance {{ $labels.instance }}, please check as
it might be disruptive.'
summary: etcd cluster database growing very fast.
expr: predict_linear(etcd_mvcc_db_total_size_in_bytes{job=~".*etcd.*"}[4h],
4*60*60) > etcd_server_quota_backend_bytes{job=~".*etcd.*"}
for: 10m
labels:
severity: warning
- alert: etcdDatabaseHighFragmentationRatio
annotations:
description: 'etcd cluster "{{ $labels.job }}": database size in use on instance
{{ $labels.instance }} is {{ $value | humanizePercentage }} of the actual
allocated disk space, please run defragmentation (e.g. etcdctl defrag) to
retrieve the unused fragmented disk space.'
runbook_url: https://etcd.io/docs/v3.5/op-guide/maintenance/#defragmentation
summary: etcd database size in use is less than 50% of the actual allocated
storage.
expr: (last_over_time(etcd_mvcc_db_total_size_in_use_in_bytes{job=~".*etcd.*"}[5m])
/ last_over_time(etcd_mvcc_db_total_size_in_bytes{job=~".*etcd.*"}[5m])) <
0.5 and etcd_mvcc_db_total_size_in_use_in_bytes{job=~".*etcd.*"} > 104857600
for: 10m
labels:
severity: warning
- name: general.rules
rules:
- alert: TargetDown
annotations:
description: '{{ printf "%.4g" $value }}% of the {{ $labels.job }}/{{ $labels.service
}} targets in {{ $labels.namespace }} namespace are down.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/general/targetdown
summary: One or more targets are unreachable.
expr: 100 * (count(up == 0) BY (job,namespace,service,cluster) / count(up) BY
(job,namespace,service,cluster)) > 10
for: 10m
labels:
severity: warning
- alert: Watchdog
annotations:
description: |
This is an alert meant to ensure that the entire alerting pipeline is functional.
This alert is always firing, therefore it should always be firing in Alertmanager
and always fire against a receiver. There are integrations with various notification
mechanisms that send a notification when this alert is not firing. For example the
"DeadMansSnitch" integration in PagerDuty.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/general/watchdog
summary: An alert that should always be firing to certify that Alertmanager
is working properly.
expr: vector(1)
labels:
severity: none
- alert: InfoInhibitor
annotations:
description: |
This is an alert that is used to inhibit info alerts.
By themselves, the info-level alerts are sometimes very noisy, but they are relevant when combined with
other alerts.
This alert fires whenever there's a severity="info" alert, and stops firing when another alert with a
severity of 'warning' or 'critical' starts firing on the same namespace.
This alert should be routed to a null receiver and configured to inhibit alerts with severity="info".
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/general/infoinhibitor
summary: Info-level alert inhibition.
expr: ALERTS{severity = "info"} == 1 unless on (namespace,cluster) ALERTS{alertname
!= "InfoInhibitor", severity =~ "warning|critical", alertstate="firing"} ==
1
labels:
severity: none
- name: k8s.rules.container_cpu_limits
rules:
- expr: |-
kube_pod_container_resource_limits{resource="cpu",job="kube-state-metrics"} * on (namespace,pod,cluster)
group_left() max by (namespace,pod,cluster) (
(kube_pod_status_phase{phase=~"Pending|Running"} == 1)
)
record: cluster:namespace:pod_cpu:active:kube_pod_container_resource_limits
- expr: |-
sum by (namespace,cluster) (
sum by (namespace,pod,cluster) (
max by (namespace,pod,container,cluster) (
kube_pod_container_resource_limits{resource="cpu",job="kube-state-metrics"}
) * on (namespace,pod,cluster) group_left() max by (namespace,pod,cluster) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)
)
)
record: namespace_cpu:kube_pod_container_resource_limits:sum
- name: k8s.rules.container_cpu_requests
rules:
- expr: |-
kube_pod_container_resource_requests{resource="cpu",job="kube-state-metrics"} * on (namespace,pod,cluster)
group_left() max by (namespace,pod,cluster) (
(kube_pod_status_phase{phase=~"Pending|Running"} == 1)
)
record: cluster:namespace:pod_cpu:active:kube_pod_container_resource_requests
- expr: |-
sum by (namespace,cluster) (
sum by (namespace,pod,cluster) (
max by (namespace,pod,container,cluster) (
kube_pod_container_resource_requests{resource="cpu",job="kube-state-metrics"}
) * on (namespace,pod,cluster) group_left() max by (namespace,pod,cluster) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)
)
)
record: namespace_cpu:kube_pod_container_resource_requests:sum
- name: k8s.rules.container_cpu_usage_seconds_total
rules:
- expr: |-
sum by (namespace,pod,container,cluster) (
irate(container_cpu_usage_seconds_total{job="kubelet", metrics_path="/metrics/cadvisor", image!=""}[5m])
) * on (namespace,pod,cluster) group_left(node) topk by (namespace,pod,cluster) (
1, max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate
- name: k8s.rules.container_memory_cache
rules:
- expr: |-
container_memory_cache{job="kubelet", metrics_path="/metrics/cadvisor", image!=""}
* on (namespace,pod,cluster) group_left(node) topk by (namespace,pod,cluster) (1,
max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: node_namespace_pod_container:container_memory_cache
- name: k8s.rules.container_memory_limits
rules:
- expr: |-
kube_pod_container_resource_limits{resource="memory",job="kube-state-metrics"} * on (namespace,pod,cluster)
group_left() max by (namespace,pod,cluster) (
(kube_pod_status_phase{phase=~"Pending|Running"} == 1)
)
record: cluster:namespace:pod_memory:active:kube_pod_container_resource_limits
- expr: |-
sum by (namespace,cluster) (
sum by (namespace,pod,cluster) (
max by (namespace,pod,container,cluster) (
kube_pod_container_resource_limits{resource="memory",job="kube-state-metrics"}
) * on (namespace,pod,cluster) group_left() max by (namespace,pod,cluster) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)
)
)
record: namespace_memory:kube_pod_container_resource_limits:sum
- name: k8s.rules.container_memory_requests
rules:
- expr: |-
kube_pod_container_resource_requests{resource="memory",job="kube-state-metrics"} * on (namespace,pod,cluster)
group_left() max by (namespace,pod,cluster) (
(kube_pod_status_phase{phase=~"Pending|Running"} == 1)
)
record: cluster:namespace:pod_memory:active:kube_pod_container_resource_requests
- expr: |-
sum by (namespace,cluster) (
sum by (namespace,pod,cluster) (
max by (namespace,pod,container,cluster) (
kube_pod_container_resource_requests{resource="memory",job="kube-state-metrics"}
) * on (namespace,pod,cluster) group_left() max by (namespace,pod,cluster) (
kube_pod_status_phase{phase=~"Pending|Running"} == 1
)
)
)
record: namespace_memory:kube_pod_container_resource_requests:sum
- name: k8s.rules.container_memory_rss
rules:
- expr: |-
container_memory_rss{job="kubelet", metrics_path="/metrics/cadvisor", image!=""}
* on (namespace,pod,cluster) group_left(node) topk by (namespace,pod,cluster) (1,
max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: node_namespace_pod_container:container_memory_rss
- name: k8s.rules.container_memory_swap
rules:
- expr: |-
container_memory_swap{job="kubelet", metrics_path="/metrics/cadvisor", image!=""}
* on (namespace,pod,cluster) group_left(node) topk by (namespace,pod,cluster) (1,
max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: node_namespace_pod_container:container_memory_swap
- name: k8s.rules.container_memory_working_set_bytes
rules:
- expr: |-
container_memory_working_set_bytes{job="kubelet", metrics_path="/metrics/cadvisor", image!=""}
* on (namespace,pod,cluster) group_left(node) topk by (namespace,pod,cluster) (1,
max by (namespace,pod,node,cluster) (kube_pod_info{node!=""})
)
record: node_namespace_pod_container:container_memory_working_set_bytes
- name: k8s.rules.pod_owner
rules:
- expr: |-
max by (namespace,workload,pod,cluster) (
label_replace(
label_replace(
kube_pod_owner{job="kube-state-metrics", owner_kind="ReplicaSet"},
"replicaset", "$1", "owner_name", "(.*)"
) * on (replicaset,namespace,cluster) group_left(owner_name) topk by (replicaset,namespace,cluster) (
1, max by (replicaset,namespace,owner_name,cluster) (
kube_replicaset_owner{job="kube-state-metrics"}
)
),
"workload", "$1", "owner_name", "(.*)"
)
)
labels:
workload_type: deployment
record: namespace_workload_pod:kube_pod_owner:relabel
- expr: |-
max by (namespace,workload,pod,cluster) (
label_replace(
kube_pod_owner{job="kube-state-metrics", owner_kind="DaemonSet"},
"workload", "$1", "owner_name", "(.*)"
)
)
labels:
workload_type: daemonset
record: namespace_workload_pod:kube_pod_owner:relabel
- expr: |-
max by (namespace,workload,pod,cluster) (
label_replace(
kube_pod_owner{job="kube-state-metrics", owner_kind="StatefulSet"},
"workload", "$1", "owner_name", "(.*)"
)
)
labels:
workload_type: statefulset
record: namespace_workload_pod:kube_pod_owner:relabel
- expr: |-
max by (namespace,workload,pod,cluster) (
label_replace(
kube_pod_owner{job="kube-state-metrics", owner_kind="Job"},
"workload", "$1", "owner_name", "(.*)"
)
)
labels:
workload_type: job
record: namespace_workload_pod:kube_pod_owner:relabel
- interval: 3m
name: kube-apiserver-availability.rules
rules:
- expr: avg_over_time(code_verb:apiserver_request_total:increase1h[30d]) * 24
* 30
record: code_verb:apiserver_request_total:increase30d
- expr: sum by (code,cluster) (code_verb:apiserver_request_total:increase30d{verb=~"LIST|GET"})
labels:
verb: read
record: code:apiserver_request_total:increase30d
- expr: sum by (code,cluster) (code_verb:apiserver_request_total:increase30d{verb=~"POST|PUT|PATCH|DELETE"})
labels:
verb: write
record: code:apiserver_request_total:increase30d
- expr: sum by (verb,scope,le,cluster) (increase(apiserver_request_sli_duration_seconds_bucket[1h]))
record: cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase1h
- expr: sum by (verb,scope,le,cluster) (avg_over_time(cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase1h[30d])
* 24 * 30)
record: cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d
- expr: sum by (verb,scope,cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase1h{le="+Inf"})
record: cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase1h
- expr: sum by (verb,scope,cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{le="+Inf"})
record: cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d
- expr: |-
1 - (
(
# write too slow
sum by (cluster) (cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d{verb=~"POST|PUT|PATCH|DELETE"})
-
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"POST|PUT|PATCH|DELETE",le=~"1(\\.0)?"})
) +
(
# read too slow
sum by (cluster) (cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d{verb=~"LIST|GET"})
-
(
(
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope=~"resource|",le=~"1(\\.0)?"})
or
vector(0)
)
+
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope="namespace",le=~"5(\\.0)?"})
+
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope="cluster",le=~"30(\\.0)?"})
)
) +
# errors
sum by (cluster) (code:apiserver_request_total:increase30d{code=~"5.."} or vector(0))
)
/
sum by (cluster) (code:apiserver_request_total:increase30d)
labels:
verb: all
record: apiserver_request:availability30d
- expr: |-
1 - (
sum by (cluster) (cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d{verb=~"LIST|GET"})
-
(
# too slow
(
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope=~"resource|",le=~"1(\\.0)?"})
or
vector(0)
)
+
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope="namespace",le=~"5(\\.0)?"})
+
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"LIST|GET",scope="cluster",le=~"30(\\.0)?"})
)
+
# errors
sum by (cluster) (code:apiserver_request_total:increase30d{verb="read",code=~"5.."} or vector(0))
)
/
sum by (cluster) (code:apiserver_request_total:increase30d{verb="read"})
labels:
verb: read
record: apiserver_request:availability30d
- expr: |-
1 - (
(
# too slow
sum by (cluster) (cluster_verb_scope:apiserver_request_sli_duration_seconds_count:increase30d{verb=~"POST|PUT|PATCH|DELETE"})
-
sum by (cluster) (cluster_verb_scope_le:apiserver_request_sli_duration_seconds_bucket:increase30d{verb=~"POST|PUT|PATCH|DELETE",le=~"1(\\.0)?"})
)
+
# errors
sum by (cluster) (code:apiserver_request_total:increase30d{verb="write",code=~"5.."} or vector(0))
)
/
sum by (cluster) (code:apiserver_request_total:increase30d{verb="write"})
labels:
verb: write
record: apiserver_request:availability30d
- expr: sum by (code,resource,cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[5m]))
labels:
verb: read
record: code_resource:apiserver_request_total:rate5m
- expr: sum by (code,resource,cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
labels:
verb: write
record: code_resource:apiserver_request_total:rate5m
- expr: sum by (code,verb,cluster) (increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"2.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
- expr: sum by (code,verb,cluster) (increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"3.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
- expr: sum by (code,verb,cluster) (increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"4.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
- expr: sum by (code,verb,cluster) (increase(apiserver_request_total{job="apiserver",verb=~"LIST|GET|POST|PUT|PATCH|DELETE",code=~"5.."}[1h]))
record: code_verb:apiserver_request_total:increase1h
- name: kube-apiserver-burnrate.rules
rules:
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[1d]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[1d]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[1d]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[1d]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[1d]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[1d]))
labels:
verb: read
record: apiserver_request:burnrate1d
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[1h]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[1h]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[1h]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[1h]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[1h]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[1h]))
labels:
verb: read
record: apiserver_request:burnrate1h
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[2h]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[2h]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[2h]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[2h]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[2h]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[2h]))
labels:
verb: read
record: apiserver_request:burnrate2h
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[30m]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[30m]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[30m]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[30m]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[30m]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[30m]))
labels:
verb: read
record: apiserver_request:burnrate30m
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[3d]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[3d]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[3d]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[3d]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[3d]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[3d]))
labels:
verb: read
record: apiserver_request:burnrate3d
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[5m]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[5m]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[5m]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[5m]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[5m]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[5m]))
labels:
verb: read
record: apiserver_request:burnrate5m
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[6h]))
-
(
(
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope=~"resource|",le=~"1(\\.0)?"}[6h]))
or
vector(0)
)
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="namespace",le=~"5(\\.0)?"}[6h]))
+
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward",scope="cluster",le=~"30(\\.0)?"}[6h]))
)
)
+
# errors
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[6h]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[6h]))
labels:
verb: read
record: apiserver_request:burnrate6h
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[1d]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[1d]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1d]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1d]))
labels:
verb: write
record: apiserver_request:burnrate1d
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[1h]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[1h]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1h]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1h]))
labels:
verb: write
record: apiserver_request:burnrate1h
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[2h]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[2h]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[2h]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[2h]))
labels:
verb: write
record: apiserver_request:burnrate2h
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[30m]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[30m]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[30m]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[30m]))
labels:
verb: write
record: apiserver_request:burnrate30m
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[3d]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[3d]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[3d]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[3d]))
labels:
verb: write
record: apiserver_request:burnrate3d
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[5m]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[5m]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[5m]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m]))
labels:
verb: write
record: apiserver_request:burnrate5m
- expr: |-
(
(
# too slow
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[6h]))
-
sum by (cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward",le=~"1(\\.0)?"}[6h]))
)
+
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[6h]))
)
/
sum by (cluster) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[6h]))
labels:
verb: write
record: apiserver_request:burnrate6h
- name: kube-apiserver-histogram.rules
rules:
- expr: histogram_quantile(0.99, sum by (le,resource,cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",subresource!~"proxy|attach|log|exec|portforward"}[5m])))
> 0
labels:
quantile: "0.99"
verb: read
record: cluster_quantile:apiserver_request_sli_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.99, sum by (le,resource,cluster) (rate(apiserver_request_sli_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",subresource!~"proxy|attach|log|exec|portforward"}[5m])))
> 0
labels:
quantile: "0.99"
verb: write
record: cluster_quantile:apiserver_request_sli_duration_seconds:histogram_quantile
- name: kube-apiserver-slos
rules:
- alert: KubeAPIErrorBudgetBurn
annotations:
description: The API server is burning too much error budget on cluster {{
$labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapierrorbudgetburn
summary: The API server is burning too much error budget.
expr: |-
sum by (cluster) (apiserver_request:burnrate1h) > (14.40 * 0.01000)
and on (cluster)
sum by (cluster) (apiserver_request:burnrate5m) > (14.40 * 0.01000)
for: 2m
labels:
long: 1h
severity: critical
short: 5m
- alert: KubeAPIErrorBudgetBurn
annotations:
description: The API server is burning too much error budget on cluster {{
$labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapierrorbudgetburn
summary: The API server is burning too much error budget.
expr: |-
sum by (cluster) (apiserver_request:burnrate6h) > (6.00 * 0.01000)
and on (cluster)
sum by (cluster) (apiserver_request:burnrate30m) > (6.00 * 0.01000)
for: 15m
labels:
long: 6h
severity: critical
short: 30m
- alert: KubeAPIErrorBudgetBurn
annotations:
description: The API server is burning too much error budget on cluster {{
$labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapierrorbudgetburn
summary: The API server is burning too much error budget.
expr: |-
sum by (cluster) (apiserver_request:burnrate1d) > (3.00 * 0.01000)
and on (cluster)
sum by (cluster) (apiserver_request:burnrate2h) > (3.00 * 0.01000)
for: 1h
labels:
long: 1d
severity: warning
short: 2h
- alert: KubeAPIErrorBudgetBurn
annotations:
description: The API server is burning too much error budget on cluster {{
$labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapierrorbudgetburn
summary: The API server is burning too much error budget.
expr: |-
sum by (cluster) (apiserver_request:burnrate3d) > (1.00 * 0.01000)
and on (cluster)
sum by (cluster) (apiserver_request:burnrate6h) > (1.00 * 0.01000)
for: 3h
labels:
long: 3d
severity: warning
short: 6h
- name: kube-prometheus-general.rules
rules:
- expr: count without(instance, pod, node) (up == 1)
record: count:up1
- expr: count without(instance, pod, node) (up == 0)
record: count:up0
- name: kube-prometheus-node-recording.rules
rules:
- expr: sum(rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal"}[3m]))
BY (instance,cluster)
record: instance:node_cpu:rate:sum
- expr: sum(rate(node_network_receive_bytes_total[3m])) BY (instance,cluster)
record: instance:node_network_receive_bytes:rate:sum
- expr: sum(rate(node_network_transmit_bytes_total[3m])) BY (instance,cluster)
record: instance:node_network_transmit_bytes:rate:sum
- expr: sum(rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal"}[5m]))
WITHOUT (cpu, mode) / ON (instance,cluster) GROUP_LEFT() count(sum(node_cpu_seconds_total)
BY (instance,cpu,cluster)) BY (instance,cluster)
record: instance:node_cpu:ratio
- expr: sum(rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal"}[5m]))
BY (cluster)
record: cluster:node_cpu:sum_rate5m
- expr: cluster:node_cpu:sum_rate5m / count(sum(node_cpu_seconds_total) BY (instance,cpu,cluster))
BY (cluster)
record: cluster:node_cpu:ratio
- name: kube-scheduler.rules
rules:
- expr: histogram_quantile(0.99, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: "0.99"
record: cluster_quantile:scheduler_e2e_scheduling_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.99, sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: "0.99"
record: cluster_quantile:scheduler_scheduling_algorithm_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.99, sum(rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: "0.99"
record: cluster_quantile:scheduler_binding_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.9, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: "0.9"
record: cluster_quantile:scheduler_e2e_scheduling_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.9, sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: "0.9"
record: cluster_quantile:scheduler_scheduling_algorithm_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.9, sum(rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: "0.9"
record: cluster_quantile:scheduler_binding_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.5, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: "0.5"
record: cluster_quantile:scheduler_e2e_scheduling_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.5, sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: "0.5"
record: cluster_quantile:scheduler_scheduling_algorithm_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.5, sum(rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m]))
without(instance, pod))
labels:
quantile: "0.5"
record: cluster_quantile:scheduler_binding_duration_seconds:histogram_quantile
- name: kube-state-metrics
rules:
- alert: KubeStateMetricsListErrors
annotations:
description: kube-state-metrics is experiencing errors at an elevated rate
in list operations. This is likely causing it to not be able to expose metrics
about Kubernetes objects correctly or at all.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kube-state-metrics/kubestatemetricslisterrors
summary: kube-state-metrics is experiencing errors in list operations.
expr: |-
(sum(rate(kube_state_metrics_list_total{job="kube-state-metrics",result="error"}[5m])) by (cluster)
/
sum(rate(kube_state_metrics_list_total{job="kube-state-metrics"}[5m])) by (cluster))
> 0.01
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsWatchErrors
annotations:
description: kube-state-metrics is experiencing errors at an elevated rate
in watch operations. This is likely causing it to not be able to expose
metrics about Kubernetes objects correctly or at all.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kube-state-metrics/kubestatemetricswatcherrors
summary: kube-state-metrics is experiencing errors in watch operations.
expr: |-
(sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics",result="error"}[5m])) by (cluster)
/
sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics"}[5m])) by (cluster))
> 0.01
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsShardingMismatch
annotations:
description: kube-state-metrics pods are running with different --total-shards
configuration, some Kubernetes objects may be exposed multiple times or
not exposed at all.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kube-state-metrics/kubestatemetricsshardingmismatch
summary: kube-state-metrics sharding is misconfigured.
expr: stdvar (kube_state_metrics_total_shards{job="kube-state-metrics"}) by
(cluster) != 0
for: 15m
labels:
severity: critical
- alert: KubeStateMetricsShardsMissing
annotations:
description: kube-state-metrics shards are missing, some Kubernetes objects
are not being exposed.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kube-state-metrics/kubestatemetricsshardsmissing
summary: kube-state-metrics shards are missing.
expr: |-
2^max(kube_state_metrics_total_shards{job="kube-state-metrics"}) by (cluster) - 1
-
sum( 2 ^ max by (shard_ordinal,cluster) (kube_state_metrics_shard_ordinal{job="kube-state-metrics"}) ) by (cluster)
!= 0
for: 15m
labels:
severity: critical
- name: kubelet.rules
rules:
- expr: histogram_quantile(0.99, sum(rate(kubelet_pleg_relist_duration_seconds_bucket{job="kubelet",
metrics_path="/metrics"}[5m])) by (instance,le,cluster) * on (instance,cluster)
group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"})
labels:
quantile: "0.99"
record: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.9, sum(rate(kubelet_pleg_relist_duration_seconds_bucket{job="kubelet",
metrics_path="/metrics"}[5m])) by (instance,le,cluster) * on (instance,cluster)
group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"})
labels:
quantile: "0.9"
record: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
- expr: histogram_quantile(0.5, sum(rate(kubelet_pleg_relist_duration_seconds_bucket{job="kubelet",
metrics_path="/metrics"}[5m])) by (instance,le,cluster) * on (instance,cluster)
group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"})
labels:
quantile: "0.5"
record: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
- name: kubernetes-apps
rules:
- alert: KubePodCrashLooping
annotations:
description: 'Pod {{ $labels.namespace }}/{{ $labels.pod }} ({{ $labels.container
}}) is in waiting state (reason: "CrashLoopBackOff") on cluster {{ $labels.cluster
}}.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepodcrashlooping
summary: Pod is crash looping.
expr: max_over_time(kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff",
job="kube-state-metrics", namespace=~".*"}[5m]) >= 1
for: 15m
labels:
severity: warning
- alert: KubePodNotReady
annotations:
description: Pod {{ $labels.namespace }}/{{ $labels.pod }} has been in a non-ready
state for longer than 15 minutes on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepodnotready
summary: Pod has been in a non-ready state for more than 15 minutes.
expr: |-
sum by (namespace,pod,cluster) (
max by (namespace,pod,cluster) (
kube_pod_status_phase{job="kube-state-metrics", namespace=~".*", phase=~"Pending|Unknown|Failed"}
) * on (namespace,pod,cluster) group_left(owner_kind) topk by (namespace,pod,cluster) (
1, max by (namespace,pod,owner_kind,cluster) (kube_pod_owner{owner_kind!="Job"})
)
) > 0
for: 15m
labels:
severity: warning
- alert: KubeDeploymentGenerationMismatch
annotations:
description: Deployment generation for {{ $labels.namespace }}/{{ $labels.deployment
}} does not match, this indicates that the Deployment has failed but has
not been rolled back on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedeploymentgenerationmismatch
summary: Deployment generation mismatch due to possible roll-back
expr: |-
kube_deployment_status_observed_generation{job="kube-state-metrics", namespace=~".*"}
!=
kube_deployment_metadata_generation{job="kube-state-metrics", namespace=~".*"}
for: 15m
labels:
severity: warning
- alert: KubeDeploymentReplicasMismatch
annotations:
description: Deployment {{ $labels.namespace }}/{{ $labels.deployment }} has
not matched the expected number of replicas for longer than 15 minutes on
cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedeploymentreplicasmismatch
summary: Deployment has not matched the expected number of replicas.
expr: |-
(
kube_deployment_spec_replicas{job="kube-state-metrics", namespace=~".*"}
>
kube_deployment_status_replicas_available{job="kube-state-metrics", namespace=~".*"}
) and (
changes(kube_deployment_status_replicas_updated{job="kube-state-metrics", namespace=~".*"}[10m])
==
0
)
for: 15m
labels:
severity: warning
- alert: KubeDeploymentRolloutStuck
annotations:
description: Rollout of deployment {{ $labels.namespace }}/{{ $labels.deployment
}} is not progressing for longer than 15 minutes on cluster {{ $labels.cluster
}}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedeploymentrolloutstuck
summary: Deployment rollout is not progressing.
expr: |-
kube_deployment_status_condition{condition="Progressing", status="false",job="kube-state-metrics", namespace=~".*"}
!= 0
for: 15m
labels:
severity: warning
- alert: KubeStatefulSetReplicasMismatch
annotations:
description: StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }}
has not matched the expected number of replicas for longer than 15 minutes
on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubestatefulsetreplicasmismatch
summary: StatefulSet has not matched the expected number of replicas.
expr: |-
(
kube_statefulset_status_replicas_ready{job="kube-state-metrics", namespace=~".*"}
!=
kube_statefulset_status_replicas{job="kube-state-metrics", namespace=~".*"}
) and (
changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics", namespace=~".*"}[10m])
==
0
)
for: 15m
labels:
severity: warning
- alert: KubeStatefulSetGenerationMismatch
annotations:
description: StatefulSet generation for {{ $labels.namespace }}/{{ $labels.statefulset
}} does not match, this indicates that the StatefulSet has failed but has
not been rolled back on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubestatefulsetgenerationmismatch
summary: StatefulSet generation mismatch due to possible roll-back
expr: |-
kube_statefulset_status_observed_generation{job="kube-state-metrics", namespace=~".*"}
!=
kube_statefulset_metadata_generation{job="kube-state-metrics", namespace=~".*"}
for: 15m
labels:
severity: warning
- alert: KubeStatefulSetUpdateNotRolledOut
annotations:
description: StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }}
update has not been rolled out on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubestatefulsetupdatenotrolledout
summary: StatefulSet update has not been rolled out.
expr: |-
(
max by (namespace,statefulset,job,cluster) (
kube_statefulset_status_current_revision{job="kube-state-metrics", namespace=~".*"}
unless
kube_statefulset_status_update_revision{job="kube-state-metrics", namespace=~".*"}
)
*
(
kube_statefulset_replicas{job="kube-state-metrics", namespace=~".*"}
!=
kube_statefulset_status_replicas_updated{job="kube-state-metrics", namespace=~".*"}
)
) and (
changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics", namespace=~".*"}[5m])
==
0
)
for: 15m
labels:
severity: warning
- alert: KubeDaemonSetRolloutStuck
annotations:
description: DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} has
not finished or progressed for at least 15m on cluster {{ $labels.cluster
}}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedaemonsetrolloutstuck
summary: DaemonSet rollout is stuck.
expr: |-
(
(
kube_daemonset_status_current_number_scheduled{job="kube-state-metrics", namespace=~".*"}
!=
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics", namespace=~".*"}
) or (
kube_daemonset_status_number_misscheduled{job="kube-state-metrics", namespace=~".*"}
!=
0
) or (
kube_daemonset_status_updated_number_scheduled{job="kube-state-metrics", namespace=~".*"}
!=
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics", namespace=~".*"}
) or (
kube_daemonset_status_number_available{job="kube-state-metrics", namespace=~".*"}
!=
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics", namespace=~".*"}
)
) and (
changes(kube_daemonset_status_updated_number_scheduled{job="kube-state-metrics", namespace=~".*"}[5m])
==
0
)
for: 15m
labels:
severity: warning
- alert: KubeContainerWaiting
annotations:
description: 'pod/{{ $labels.pod }} in namespace {{ $labels.namespace }} on
container {{ $labels.container}} has been in waiting state for longer than
1 hour. (reason: "{{ $labels.reason }}") on cluster {{ $labels.cluster }}.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubecontainerwaiting
summary: Pod container waiting longer than 1 hour
expr: kube_pod_container_status_waiting_reason{reason!="CrashLoopBackOff", job="kube-state-metrics",
namespace=~".*"} > 0
for: 1h
labels:
severity: warning
- alert: KubeDaemonSetNotScheduled
annotations:
description: '{{ $value }} Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset
}} are not scheduled on cluster {{ $labels.cluster }}.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedaemonsetnotscheduled
summary: DaemonSet pods are not scheduled.
expr: |-
kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics", namespace=~".*"}
-
kube_daemonset_status_current_number_scheduled{job="kube-state-metrics", namespace=~".*"} > 0
for: 10m
labels:
severity: warning
- alert: KubeDaemonSetMisScheduled
annotations:
description: '{{ $value }} Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset
}} are running where they are not supposed to run on cluster {{ $labels.cluster
}}.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubedaemonsetmisscheduled
summary: DaemonSet pods are misscheduled.
expr: kube_daemonset_status_number_misscheduled{job="kube-state-metrics", namespace=~".*"}
> 0
for: 15m
labels:
severity: warning
- alert: KubeJobNotCompleted
annotations:
description: Job {{ $labels.namespace }}/{{ $labels.job_name }} is taking
more than {{ "43200" | humanizeDuration }} to complete on cluster {{ $labels.cluster
}}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubejobnotcompleted
summary: Job did not complete in time
expr: |-
time() - max by (namespace,job_name,cluster) (kube_job_status_start_time{job="kube-state-metrics", namespace=~".*"}
and
kube_job_status_active{job="kube-state-metrics", namespace=~".*"} > 0) > 43200
labels:
severity: warning
- alert: KubeJobFailed
annotations:
description: Job {{ $labels.namespace }}/{{ $labels.job_name }} failed to
complete. Removing failed job after investigation should clear this alert
on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubejobfailed
summary: Job failed to complete.
expr: kube_job_failed{job="kube-state-metrics", namespace=~".*"} > 0
for: 15m
labels:
severity: warning
- alert: KubeHpaReplicasMismatch
annotations:
description: HPA {{ $labels.namespace }}/{{ $labels.horizontalpodautoscaler }}
has not matched the desired number of replicas for longer than 15 minutes
on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubehpareplicasmismatch
summary: HPA has not matched desired number of replicas.
expr: |-
(kube_horizontalpodautoscaler_status_desired_replicas{job="kube-state-metrics", namespace=~".*"}
!=
kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics", namespace=~".*"})
and
(kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics", namespace=~".*"}
>
kube_horizontalpodautoscaler_spec_min_replicas{job="kube-state-metrics", namespace=~".*"})
and
(kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics", namespace=~".*"}
<
kube_horizontalpodautoscaler_spec_max_replicas{job="kube-state-metrics", namespace=~".*"})
and
changes(kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics", namespace=~".*"}[15m]) == 0
for: 15m
labels:
severity: warning
- alert: KubeHpaMaxedOut
annotations:
description: HPA {{ $labels.namespace }}/{{ $labels.horizontalpodautoscaler }}
has been running at max replicas for longer than 15 minutes on cluster {{
$labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubehpamaxedout
summary: HPA is running at max replicas
expr: |-
kube_horizontalpodautoscaler_status_current_replicas{job="kube-state-metrics", namespace=~".*"}
==
kube_horizontalpodautoscaler_spec_max_replicas{job="kube-state-metrics", namespace=~".*"}
for: 15m
labels:
severity: warning
- name: kubernetes-resources
rules:
- alert: KubeCPUOvercommit
annotations:
description: Cluster {{ $labels.cluster }} has overcommitted CPU resource
requests for Pods by {{ $value }} CPU shares and cannot tolerate node failure.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubecpuovercommit
summary: Cluster has overcommitted CPU resource requests.
expr: |-
sum(namespace_cpu:kube_pod_container_resource_requests:sum{}) by (cluster) - (sum(kube_node_status_allocatable{job="kube-state-metrics",resource="cpu"}) by (cluster) - max(kube_node_status_allocatable{job="kube-state-metrics",resource="cpu"}) by (cluster)) > 0
and
(sum(kube_node_status_allocatable{job="kube-state-metrics",resource="cpu"}) by (cluster) - max(kube_node_status_allocatable{job="kube-state-metrics",resource="cpu"}) by (cluster)) > 0
for: 10m
labels:
severity: warning
- alert: KubeMemoryOvercommit
annotations:
description: Cluster {{ $labels.cluster }} has overcommitted memory resource
requests for Pods by {{ $value | humanize }} bytes and cannot tolerate node
failure.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubememoryovercommit
summary: Cluster has overcommitted memory resource requests.
expr: |-
sum(namespace_memory:kube_pod_container_resource_requests:sum{}) by (cluster) - (sum(kube_node_status_allocatable{resource="memory", job="kube-state-metrics"}) by (cluster) - max(kube_node_status_allocatable{resource="memory", job="kube-state-metrics"}) by (cluster)) > 0
and
(sum(kube_node_status_allocatable{resource="memory", job="kube-state-metrics"}) by (cluster) - max(kube_node_status_allocatable{resource="memory", job="kube-state-metrics"}) by (cluster)) > 0
for: 10m
labels:
severity: warning
- alert: KubeCPUQuotaOvercommit
annotations:
description: Cluster {{ $labels.cluster }} has overcommitted CPU resource
requests for Namespaces.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubecpuquotaovercommit
summary: Cluster has overcommitted CPU resource requests.
expr: |-
sum(min without(resource) (kube_resourcequota{job="kube-state-metrics", type="hard", resource=~"(cpu|requests.cpu)"})) by (cluster)
/
sum(kube_node_status_allocatable{resource="cpu", job="kube-state-metrics"}) by (cluster)
> 1.5
for: 5m
labels:
severity: warning
- alert: KubeMemoryQuotaOvercommit
annotations:
description: Cluster {{ $labels.cluster }} has overcommitted memory resource
requests for Namespaces.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubememoryquotaovercommit
summary: Cluster has overcommitted memory resource requests.
expr: |-
sum(min without(resource) (kube_resourcequota{job="kube-state-metrics", type="hard", resource=~"(memory|requests.memory)"})) by (cluster)
/
sum(kube_node_status_allocatable{resource="memory", job="kube-state-metrics"}) by (cluster)
> 1.5
for: 5m
labels:
severity: warning
- alert: KubeQuotaAlmostFull
annotations:
description: Namespace {{ $labels.namespace }} is using {{ $value | humanizePercentage
}} of its {{ $labels.resource }} quota on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubequotaalmostfull
summary: Namespace quota is going to be full.
expr: |-
kube_resourcequota{job="kube-state-metrics", type="used"}
/ ignoring(instance, job, type)
(kube_resourcequota{job="kube-state-metrics", type="hard"} > 0)
> 0.9 < 1
for: 15m
labels:
severity: info
- alert: KubeQuotaFullyUsed
annotations:
description: Namespace {{ $labels.namespace }} is using {{ $value | humanizePercentage
}} of its {{ $labels.resource }} quota on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubequotafullyused
summary: Namespace quota is fully used.
expr: |-
kube_resourcequota{job="kube-state-metrics", type="used"}
/ ignoring(instance, job, type)
(kube_resourcequota{job="kube-state-metrics", type="hard"} > 0)
== 1
for: 15m
labels:
severity: info
- alert: KubeQuotaExceeded
annotations:
description: Namespace {{ $labels.namespace }} is using {{ $value | humanizePercentage
}} of its {{ $labels.resource }} quota on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubequotaexceeded
summary: Namespace quota has exceeded the limits.
expr: |-
kube_resourcequota{job="kube-state-metrics", type="used"}
/ ignoring(instance, job, type)
(kube_resourcequota{job="kube-state-metrics", type="hard"} > 0)
> 1
for: 15m
labels:
severity: warning
- alert: CPUThrottlingHigh
annotations:
description: '{{ $value | humanizePercentage }} throttling of CPU in namespace
{{ $labels.namespace }} for container {{ $labels.container }} in pod {{
$labels.pod }} on cluster {{ $labels.cluster }}.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/cputhrottlinghigh
summary: Processes experience elevated CPU throttling.
expr: |-
sum(increase(container_cpu_cfs_throttled_periods_total{container!="", job="kubelet", metrics_path="/metrics/cadvisor", }[5m])) without (id, metrics_path, name, image, endpoint, job, node)
/
sum(increase(container_cpu_cfs_periods_total{job="kubelet", metrics_path="/metrics/cadvisor", }[5m])) without (id, metrics_path, name, image, endpoint, job, node)
> ( 25 / 100 )
for: 15m
labels:
severity: info
- name: kubernetes-storage
rules:
- alert: KubePersistentVolumeFillingUp
annotations:
description: The PersistentVolume claimed by {{ $labels.persistentvolumeclaim
}} in Namespace {{ $labels.namespace }} {{ with $labels.cluster -}} on Cluster
{{ . }} {{- end }} is only {{ $value | humanizePercentage }} free.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumefillingup
summary: PersistentVolume is filling up.
expr: |-
(
kubelet_volume_stats_available_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
/
kubelet_volume_stats_capacity_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
) < 0.03
and
kubelet_volume_stats_used_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"} > 0
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_access_mode{ access_mode="ReadOnlyMany"} == 1
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_labels{label_excluded_from_alerts="true"} == 1
for: 1m
labels:
severity: critical
- alert: KubePersistentVolumeFillingUp
annotations:
description: Based on recent sampling, the PersistentVolume claimed by {{
$labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace }} {{
with $labels.cluster -}} on Cluster {{ . }} {{- end }} is expected to fill
up within four days. Currently {{ $value | humanizePercentage }} is available.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumefillingup
summary: PersistentVolume is filling up.
expr: |-
(
kubelet_volume_stats_available_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
/
kubelet_volume_stats_capacity_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
) < 0.15
and
kubelet_volume_stats_used_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"} > 0
and
predict_linear(kubelet_volume_stats_available_bytes{job="kubelet", namespace=~".*", metrics_path="/metrics"}[6h], 4 * 24 * 3600) < 0
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_access_mode{ access_mode="ReadOnlyMany"} == 1
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_labels{label_excluded_from_alerts="true"} == 1
for: 1h
labels:
severity: warning
- alert: KubePersistentVolumeInodesFillingUp
annotations:
description: The PersistentVolume claimed by {{ $labels.persistentvolumeclaim
}} in Namespace {{ $labels.namespace }} {{ with $labels.cluster -}} on Cluster
{{ . }} {{- end }} only has {{ $value | humanizePercentage }} free inodes.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumeinodesfillingup
summary: PersistentVolumeInodes are filling up.
expr: |-
(
kubelet_volume_stats_inodes_free{job="kubelet", namespace=~".*", metrics_path="/metrics"}
/
kubelet_volume_stats_inodes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
) < 0.03
and
kubelet_volume_stats_inodes_used{job="kubelet", namespace=~".*", metrics_path="/metrics"} > 0
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_access_mode{ access_mode="ReadOnlyMany"} == 1
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_labels{label_excluded_from_alerts="true"} == 1
for: 1m
labels:
severity: critical
- alert: KubePersistentVolumeInodesFillingUp
annotations:
description: Based on recent sampling, the PersistentVolume claimed by {{
$labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace }} {{
with $labels.cluster -}} on Cluster {{ . }} {{- end }} is expected to run
out of inodes within four days. Currently {{ $value | humanizePercentage
}} of its inodes are free.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumeinodesfillingup
summary: PersistentVolumeInodes are filling up.
expr: |-
(
kubelet_volume_stats_inodes_free{job="kubelet", namespace=~".*", metrics_path="/metrics"}
/
kubelet_volume_stats_inodes{job="kubelet", namespace=~".*", metrics_path="/metrics"}
) < 0.15
and
kubelet_volume_stats_inodes_used{job="kubelet", namespace=~".*", metrics_path="/metrics"} > 0
and
predict_linear(kubelet_volume_stats_inodes_free{job="kubelet", namespace=~".*", metrics_path="/metrics"}[6h], 4 * 24 * 3600) < 0
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_access_mode{ access_mode="ReadOnlyMany"} == 1
unless on (namespace,persistentvolumeclaim,cluster)
kube_persistentvolumeclaim_labels{label_excluded_from_alerts="true"} == 1
for: 1h
labels:
severity: warning
- alert: KubePersistentVolumeErrors
annotations:
description: The persistent volume {{ $labels.persistentvolume }} {{ with
$labels.cluster -}} on Cluster {{ . }} {{- end }} has status {{ $labels.phase
}}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepersistentvolumeerrors
summary: PersistentVolume is having issues with provisioning.
expr: kube_persistentvolume_status_phase{phase=~"Failed|Pending",job="kube-state-metrics"}
> 0
for: 5m
labels:
severity: critical
- name: kubernetes-system
rules:
- alert: KubeVersionMismatch
annotations:
description: There are {{ $value }} different semantic versions of Kubernetes
components running on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeversionmismatch
summary: Different semantic versions of Kubernetes components running.
expr: count by (cluster) (count by (git_version,cluster) (label_replace(kubernetes_build_info{job!~"kube-dns|coredns"},"git_version","$1","git_version","(v[0-9]*.[0-9]*).*")))
> 1
for: 15m
labels:
severity: warning
- alert: KubeClientErrors
annotations:
description: Kubernetes API server client '{{ $labels.job }}/{{ $labels.instance
}}' is experiencing {{ $value | humanizePercentage }} errors on cluster
{{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeclienterrors
summary: Kubernetes API server client is experiencing errors.
expr: |-
(sum(rate(rest_client_requests_total{job="apiserver",code=~"5.."}[5m])) by (instance,job,namespace,cluster)
/
sum(rate(rest_client_requests_total{job="apiserver"}[5m])) by (instance,job,namespace,cluster))
> 0.01
for: 15m
labels:
severity: warning
- name: kubernetes-system-apiserver
rules:
- alert: KubeClientCertificateExpiration
annotations:
description: A client certificate used to authenticate to kubernetes apiserver
is expiring in less than 7.0 days on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeclientcertificateexpiration
summary: Client certificate is about to expire.
expr: |-
histogram_quantile(0.01, sum without (namespace, service, endpoint) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 604800
and
on (job,instance,cluster) apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0
for: 5m
labels:
severity: warning
- alert: KubeClientCertificateExpiration
annotations:
description: A client certificate used to authenticate to kubernetes apiserver
is expiring in less than 24.0 hours on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeclientcertificateexpiration
summary: Client certificate is about to expire.
expr: |-
histogram_quantile(0.01, sum without (namespace, service, endpoint) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 86400
and
on (job,instance,cluster) apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0
for: 5m
labels:
severity: critical
- alert: KubeAggregatedAPIErrors
annotations:
description: Kubernetes aggregated API {{ $labels.instance }}/{{ $labels.name
}} has reported {{ $labels.reason }} errors on cluster {{ $labels.cluster
}}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeaggregatedapierrors
summary: Kubernetes aggregated API has reported errors.
expr: sum by (instance,name,reason,cluster)(increase(aggregator_unavailable_apiservice_total{job="apiserver"}[1m]))
> 0
for: 10m
labels:
severity: warning
- alert: KubeAggregatedAPIDown
annotations:
description: Kubernetes aggregated API {{ $labels.name }}/{{ $labels.namespace
}} has been only {{ $value | humanize }}% available over the last 10m on
cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeaggregatedapidown
summary: Kubernetes aggregated API is down.
expr: (1 - max by (name,namespace,cluster)(avg_over_time(aggregator_unavailable_apiservice{job="apiserver"}[10m])))
* 100 < 85
for: 5m
labels:
severity: warning
- alert: KubeAPIDown
annotations:
description: KubeAPI has disappeared from Prometheus target discovery.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapidown
summary: Target disappeared from Prometheus target discovery.
expr: absent(up{job="apiserver"} == 1)
for: 15m
labels:
severity: critical
- alert: KubeAPITerminatedRequests
annotations:
description: The kubernetes apiserver has terminated {{ $value | humanizePercentage
}} of its incoming requests on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeapiterminatedrequests
summary: The kubernetes apiserver has terminated {{ $value | humanizePercentage
}} of its incoming requests.
expr: sum by (cluster) (rate(apiserver_request_terminations_total{job="apiserver"}[10m]))
/ ( sum by (cluster) (rate(apiserver_request_total{job="apiserver"}[10m]))
+ sum by (cluster) (rate(apiserver_request_terminations_total{job="apiserver"}[10m]))
) > 0.20
for: 5m
labels:
severity: warning
- name: kubernetes-system-controller-manager
rules:
- alert: KubeControllerManagerDown
annotations:
description: KubeControllerManager has disappeared from Prometheus target
discovery.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubecontrollermanagerdown
summary: Target disappeared from Prometheus target discovery.
expr: absent(up{job="kube-controller-manager"} == 1)
for: 15m
labels:
severity: critical
- name: kubernetes-system-kubelet
rules:
- alert: KubeNodeNotReady
annotations:
description: '{{ $labels.node }} has been unready for more than 15 minutes
on cluster {{ $labels.cluster }}.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubenodenotready
summary: Node is not ready.
expr: kube_node_status_condition{job="kube-state-metrics",condition="Ready",status="true"}
== 0
for: 15m
labels:
severity: warning
- alert: KubeNodeUnreachable
annotations:
description: '{{ $labels.node }} is unreachable and some workloads may be
rescheduled on cluster {{ $labels.cluster }}.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubenodeunreachable
summary: Node is unreachable.
expr: (kube_node_spec_taint{job="kube-state-metrics",key="node.kubernetes.io/unreachable",effect="NoSchedule"}
unless ignoring(key,value) kube_node_spec_taint{job="kube-state-metrics",key=~"ToBeDeletedByClusterAutoscaler|cloud.google.com/impending-node-termination|aws-node-termination-handler/spot-itn"})
== 1
for: 15m
labels:
severity: warning
- alert: KubeletTooManyPods
annotations:
description: Kubelet '{{ $labels.node }}' is running at {{ $value | humanizePercentage
}} of its Pod capacity on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubelettoomanypods
summary: Kubelet is running at capacity.
expr: |-
count by (node,cluster) (
(kube_pod_status_phase{job="kube-state-metrics", phase="Running"} == 1)
* on (namespace,pod,cluster) group_left (node)
group by (namespace,pod,node,cluster) (
kube_pod_info{job="kube-state-metrics"}
)
)
/
max by (node,cluster) (
kube_node_status_capacity{job="kube-state-metrics", resource="pods"} != 1
) > 0.95
for: 15m
labels:
severity: info
- alert: KubeNodeReadinessFlapping
annotations:
description: The readiness status of node {{ $labels.node }} has changed {{
$value }} times in the last 15 minutes on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubenodereadinessflapping
summary: Node readiness status is flapping.
expr: sum(changes(kube_node_status_condition{job="kube-state-metrics",status="true",condition="Ready"}[15m]))
by (node,cluster) > 2
for: 15m
labels:
severity: warning
- alert: KubeletPlegDurationHigh
annotations:
description: The Kubelet Pod Lifecycle Event Generator has a 99th percentile
duration of {{ $value }} seconds on node {{ $labels.node }} on cluster {{
$labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletplegdurationhigh
summary: Kubelet Pod Lifecycle Event Generator is taking too long to relist.
expr: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile{quantile="0.99"}
>= 10
for: 5m
labels:
severity: warning
- alert: KubeletPodStartUpLatencyHigh
annotations:
description: Kubelet Pod startup 99th percentile latency is {{ $value }} seconds
on node {{ $labels.node }} on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletpodstartuplatencyhigh
summary: Kubelet Pod startup latency is too high.
expr: histogram_quantile(0.99, sum(rate(kubelet_pod_worker_duration_seconds_bucket{job="kubelet",
metrics_path="/metrics"}[5m])) by (instance,le,cluster)) * on (instance,cluster)
group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"}
> 60
for: 15m
labels:
severity: warning
- alert: KubeletClientCertificateExpiration
annotations:
description: Client certificate for Kubelet on node {{ $labels.node }} expires
in {{ $value | humanizeDuration }} on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletclientcertificateexpiration
summary: Kubelet client certificate is about to expire.
expr: kubelet_certificate_manager_client_ttl_seconds < 604800
labels:
severity: warning
- alert: KubeletClientCertificateExpiration
annotations:
description: Client certificate for Kubelet on node {{ $labels.node }} expires
in {{ $value | humanizeDuration }} on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletclientcertificateexpiration
summary: Kubelet client certificate is about to expire.
expr: kubelet_certificate_manager_client_ttl_seconds < 86400
labels:
severity: critical
- alert: KubeletServerCertificateExpiration
annotations:
description: Server certificate for Kubelet on node {{ $labels.node }} expires
in {{ $value | humanizeDuration }} on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletservercertificateexpiration
summary: Kubelet server certificate is about to expire.
expr: kubelet_certificate_manager_server_ttl_seconds < 604800
labels:
severity: warning
- alert: KubeletServerCertificateExpiration
annotations:
description: Server certificate for Kubelet on node {{ $labels.node }} expires
in {{ $value | humanizeDuration }} on cluster {{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletservercertificateexpiration
summary: Kubelet server certificate is about to expire.
expr: kubelet_certificate_manager_server_ttl_seconds < 86400
labels:
severity: critical
- alert: KubeletClientCertificateRenewalErrors
annotations:
description: Kubelet on node {{ $labels.node }} has failed to renew its client
certificate ({{ $value | humanize }} errors in the last 5 minutes) on cluster
{{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletclientcertificaterenewalerrors
summary: Kubelet has failed to renew its client certificate.
expr: increase(kubelet_certificate_manager_client_expiration_renew_errors[5m])
> 0
for: 15m
labels:
severity: warning
- alert: KubeletServerCertificateRenewalErrors
annotations:
description: Kubelet on node {{ $labels.node }} has failed to renew its server
certificate ({{ $value | humanize }} errors in the last 5 minutes) on cluster
{{ $labels.cluster }}.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletservercertificaterenewalerrors
summary: Kubelet has failed to renew its server certificate.
expr: increase(kubelet_server_expiration_renew_errors[5m]) > 0
for: 15m
labels:
severity: warning
- alert: KubeletDown
annotations:
description: Kubelet has disappeared from Prometheus target discovery.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeletdown
summary: Target disappeared from Prometheus target discovery.
expr: absent(up{job="kubelet", metrics_path="/metrics"} == 1)
for: 15m
labels:
severity: critical
- name: kubernetes-system-scheduler
rules:
- alert: KubeSchedulerDown
annotations:
description: KubeScheduler has disappeared from Prometheus target discovery.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubeschedulerdown
summary: Target disappeared from Prometheus target discovery.
expr: absent(up{job="kube-scheduler"} == 1)
for: 15m
labels:
severity: critical
- name: node-exporter
rules:
- alert: NodeFilesystemSpaceFillingUp
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint
}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available
space left and is filling up.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemspacefillingup
summary: Filesystem is predicted to run out of space within the next 24 hours.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 15
and
predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""}[6h], 24*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: warning
- alert: NodeFilesystemSpaceFillingUp
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint
}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available
space left and is filling up fast.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemspacefillingup
summary: Filesystem is predicted to run out of space within the next 4 hours.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 10
and
predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""}[6h], 4*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: critical
- alert: NodeFilesystemAlmostOutOfSpace
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint
}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available
space left.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemalmostoutofspace
summary: Filesystem has less than 5% space left.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 5
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 30m
labels:
severity: warning
- alert: NodeFilesystemAlmostOutOfSpace
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint
}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available
space left.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemalmostoutofspace
summary: Filesystem has less than 3% space left.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 3
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 30m
labels:
severity: critical
- alert: NodeFilesystemFilesFillingUp
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint
}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available
inodes left and is filling up.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemfilesfillingup
summary: Filesystem is predicted to run out of inodes within the next 24 hours.
expr: |-
(
node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_files{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 40
and
predict_linear(node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""}[6h], 24*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: warning
- alert: NodeFilesystemFilesFillingUp
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint
}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available
inodes left and is filling up fast.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemfilesfillingup
summary: Filesystem is predicted to run out of inodes within the next 4 hours.
expr: |-
(
node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_files{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 20
and
predict_linear(node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""}[6h], 4*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: critical
- alert: NodeFilesystemAlmostOutOfFiles
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint
}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available
inodes left.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemalmostoutoffiles
summary: Filesystem has less than 5% inodes left.
expr: |-
(
node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_files{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 5
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: warning
- alert: NodeFilesystemAlmostOutOfFiles
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint
}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available
inodes left.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemalmostoutoffiles
summary: Filesystem has less than 3% inodes left.
expr: |-
(
node_filesystem_files_free{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_files{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 3
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: critical
- alert: NodeNetworkReceiveErrs
annotations:
description: '{{ $labels.instance }} interface {{ $labels.device }} has encountered
{{ printf "%.0f" $value }} receive errors in the last two minutes.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodenetworkreceiveerrs
summary: Network interface is reporting many receive errors.
expr: rate(node_network_receive_errs_total{job="node-exporter"}[2m]) / rate(node_network_receive_packets_total{job="node-exporter"}[2m])
> 0.01
for: 1h
labels:
severity: warning
- alert: NodeNetworkTransmitErrs
annotations:
description: '{{ $labels.instance }} interface {{ $labels.device }} has encountered
{{ printf "%.0f" $value }} transmit errors in the last two minutes.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodenetworktransmiterrs
summary: Network interface is reporting many transmit errors.
expr: rate(node_network_transmit_errs_total{job="node-exporter"}[2m]) / rate(node_network_transmit_packets_total{job="node-exporter"}[2m])
> 0.01
for: 1h
labels:
severity: warning
- alert: NodeHighNumberConntrackEntriesUsed
annotations:
description: '{{ $labels.instance }} {{ $value | humanizePercentage }} of
conntrack entries are used.'
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodehighnumberconntrackentriesused
summary: Number of conntrack are getting close to the limit.
expr: (node_nf_conntrack_entries{job="node-exporter"} / node_nf_conntrack_entries_limit)
> 0.75
labels:
severity: warning
- alert: NodeTextFileCollectorScrapeError
annotations:
description: Node Exporter text file collector on {{ $labels.instance }} failed
to scrape.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodetextfilecollectorscrapeerror
summary: Node Exporter text file collector failed to scrape.
expr: node_textfile_scrape_error{job="node-exporter"} == 1
labels:
severity: warning
- alert: NodeClockSkewDetected
annotations:
description: Clock at {{ $labels.instance }} is out of sync by more than 0.05s.
Ensure NTP is configured correctly on this host.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodeclockskewdetected
summary: Clock skew detected.
expr: |-
(
node_timex_offset_seconds{job="node-exporter"} > 0.05
and
deriv(node_timex_offset_seconds{job="node-exporter"}[5m]) >= 0
)
or
(
node_timex_offset_seconds{job="node-exporter"} < -0.05
and
deriv(node_timex_offset_seconds{job="node-exporter"}[5m]) <= 0
)
for: 10m
labels:
severity: warning
- alert: NodeClockNotSynchronising
annotations:
description: Clock at {{ $labels.instance }} is not synchronising. Ensure
NTP is configured on this host.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodeclocknotsynchronising
summary: Clock not synchronising.
expr: |-
min_over_time(node_timex_sync_status{job="node-exporter"}[5m]) == 0
and
node_timex_maxerror_seconds{job="node-exporter"} >= 16
for: 10m
labels:
severity: warning
- alert: NodeRAIDDegraded
annotations:
description: RAID array '{{ $labels.device }}' at {{ $labels.instance }} is
in degraded state due to one or more disks failures. Number of spare drives
is insufficient to fix issue automatically.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/noderaiddegraded
summary: RAID Array is degraded.
expr: node_md_disks_required{job="node-exporter",device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}
- ignoring (state) (node_md_disks{state="active",job="node-exporter",device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"})
> 0
for: 15m
labels:
severity: critical
- alert: NodeRAIDDiskFailure
annotations:
description: At least one device in RAID array at {{ $labels.instance }} failed.
Array '{{ $labels.device }}' needs attention and possibly a disk swap.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/noderaiddiskfailure
summary: Failed device in RAID array.
expr: node_md_disks{state="failed",job="node-exporter",device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}
> 0
labels:
severity: warning
- alert: NodeFileDescriptorLimit
annotations:
description: File descriptors limit at {{ $labels.instance }} is currently
at {{ printf "%.2f" $value }}%.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefiledescriptorlimit
summary: Kernel is predicted to exhaust file descriptors limit soon.
expr: |-
(
node_filefd_allocated{job="node-exporter"} * 100 / node_filefd_maximum{job="node-exporter"} > 70
)
for: 15m
labels:
severity: warning
- alert: NodeFileDescriptorLimit
annotations:
description: File descriptors limit at {{ $labels.instance }} is currently
at {{ printf "%.2f" $value }}%.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefiledescriptorlimit
summary: Kernel is predicted to exhaust file descriptors limit soon.
expr: |-
(
node_filefd_allocated{job="node-exporter"} * 100 / node_filefd_maximum{job="node-exporter"} > 90
)
for: 15m
labels:
severity: critical
- alert: NodeCPUHighUsage
annotations:
description: |
CPU usage at {{ $labels.instance }} has been above 90% for the last 15 minutes, is currently at {{ printf "%.2f" $value }}%.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodecpuhighusage
summary: High CPU usage.
expr: sum without(mode) (avg without (cpu) (rate(node_cpu_seconds_total{job="node-exporter",
mode!~"idle|iowait"}[2m]))) * 100 > 90
for: 15m
labels:
severity: info
- alert: NodeSystemSaturation
annotations:
description: |
System load per core at {{ $labels.instance }} has been above 2 for the last 15 minutes, is currently at {{ printf "%.2f" $value }}.
This might indicate this instance resources saturation and can cause it becoming unresponsive.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodesystemsaturation
summary: System saturated, load per core is very high.
expr: |-
node_load1{job="node-exporter"}
/ count without (cpu, mode) (node_cpu_seconds_total{job="node-exporter", mode="idle"}) > 2
for: 15m
labels:
severity: warning
- alert: NodeMemoryMajorPagesFaults
annotations:
description: |
Memory major pages are occurring at very high rate at {{ $labels.instance }}, 500 major page faults per second for the last 15 minutes, is currently at {{ printf "%.2f" $value }}.
Please check that there is enough memory available at this instance.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodememorymajorpagesfaults
summary: Memory major page faults are occurring at very high rate.
expr: rate(node_vmstat_pgmajfault{job="node-exporter"}[5m]) > 500
for: 15m
labels:
severity: warning
- alert: NodeMemoryHighUtilization
annotations:
description: |
Memory is filling up at {{ $labels.instance }}, has been above 90% for the last 15 minutes, is currently at {{ printf "%.2f" $value }}%.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodememoryhighutilization
summary: Host is running out of memory.
expr: 100 - (node_memory_MemAvailable_bytes{job="node-exporter"} / node_memory_MemTotal_bytes{job="node-exporter"}
* 100) > 90
for: 15m
labels:
severity: warning
- alert: NodeDiskIOSaturation
annotations:
description: |
Disk IO queue (aqu-sq) is high on {{ $labels.device }} at {{ $labels.instance }}, has been above 10 for the last 30 minutes, is currently at {{ printf "%.2f" $value }}.
This symptom might indicate disk saturation.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodediskiosaturation
summary: Disk IO queue is high.
expr: rate(node_disk_io_time_weighted_seconds_total{job="node-exporter", device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}[5m])
> 10
for: 30m
labels:
severity: warning
- alert: NodeSystemdServiceFailed
annotations:
description: Systemd service {{ $labels.name }} has entered failed state at
{{ $labels.instance }}
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodesystemdservicefailed
summary: Systemd service has entered failed state.
expr: node_systemd_unit_state{job="node-exporter", state="failed"} == 1
for: 5m
labels:
severity: warning
- alert: NodeBondingDegraded
annotations:
description: Bonding interface {{ $labels.master }} on {{ $labels.instance
}} is in degraded state due to one or more slave failures.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodebondingdegraded
summary: Bonding interface is degraded
expr: (node_bonding_slaves - node_bonding_active) != 0
for: 5m
labels:
severity: warning
- name: node-exporter.rules
rules:
- expr: |-
count without (cpu, mode) (
node_cpu_seconds_total{job="node-exporter",mode="idle"}
)
record: instance:node_num_cpu:sum
- expr: |-
1 - avg without (cpu) (
sum without (mode) (rate(node_cpu_seconds_total{job="node-exporter", mode=~"idle|iowait|steal"}[5m]))
)
record: instance:node_cpu_utilisation:rate5m
- expr: |-
(
node_load1{job="node-exporter"}
/
instance:node_num_cpu:sum{job="node-exporter"}
)
record: instance:node_load1_per_cpu:ratio
- expr: |-
1 - (
(
node_memory_MemAvailable_bytes{job="node-exporter"}
or
(
node_memory_Buffers_bytes{job="node-exporter"}
+
node_memory_Cached_bytes{job="node-exporter"}
+
node_memory_MemFree_bytes{job="node-exporter"}
+
node_memory_Slab_bytes{job="node-exporter"}
)
)
/
node_memory_MemTotal_bytes{job="node-exporter"}
)
record: instance:node_memory_utilisation:ratio
- expr: rate(node_vmstat_pgmajfault{job="node-exporter"}[5m])
record: instance:node_vmstat_pgmajfault:rate5m
- expr: rate(node_disk_io_time_seconds_total{job="node-exporter", device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}[5m])
record: instance_device:node_disk_io_time_seconds:rate5m
- expr: rate(node_disk_io_time_weighted_seconds_total{job="node-exporter", device=~"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|md.+|dasd.+)"}[5m])
record: instance_device:node_disk_io_time_weighted_seconds:rate5m
- expr: |-
sum without (device) (
rate(node_network_receive_bytes_total{job="node-exporter", device!="lo"}[5m])
)
record: instance:node_network_receive_bytes_excluding_lo:rate5m
- expr: |-
sum without (device) (
rate(node_network_transmit_bytes_total{job="node-exporter", device!="lo"}[5m])
)
record: instance:node_network_transmit_bytes_excluding_lo:rate5m
- expr: |-
sum without (device) (
rate(node_network_receive_drop_total{job="node-exporter", device!="lo"}[5m])
)
record: instance:node_network_receive_drop_excluding_lo:rate5m
- expr: |-
sum without (device) (
rate(node_network_transmit_drop_total{job="node-exporter", device!="lo"}[5m])
)
record: instance:node_network_transmit_drop_excluding_lo:rate5m
- name: node-network
rules:
- alert: NodeNetworkInterfaceFlapping
annotations:
description: Network interface "{{ $labels.device }}" changing its up status
often on node-exporter {{ $labels.namespace }}/{{ $labels.pod }}
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/general/nodenetworkinterfaceflapping
summary: Network interface is often changing its status
expr: changes(node_network_up{job="node-exporter",device!~"veth.+"}[2m]) > 2
for: 2m
labels:
severity: warning
- name: node.rules
rules:
- expr: |-
topk by (namespace,pod,cluster) (1,
max by (node,namespace,pod,cluster) (
label_replace(kube_pod_info{job="kube-state-metrics",node!=""}, "pod", "$1", "pod", "(.*)")
))
record: 'node_namespace_pod:kube_pod_info:'
- expr: |-
count by (node,cluster) (
node_cpu_seconds_total{mode="idle",job="node-exporter"}
* on (namespace,pod,cluster) group_left(node)
topk by (namespace,pod,cluster) (1, node_namespace_pod:kube_pod_info:)
)
record: node:node_num_cpu:sum
- expr: |-
sum(
node_memory_MemAvailable_bytes{job="node-exporter"} or
(
node_memory_Buffers_bytes{job="node-exporter"} +
node_memory_Cached_bytes{job="node-exporter"} +
node_memory_MemFree_bytes{job="node-exporter"} +
node_memory_Slab_bytes{job="node-exporter"}
)
) by (cluster)
record: :node_memory_MemAvailable_bytes:sum
- expr: |-
avg by (node,cluster) (
sum without (mode) (
rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal",job="node-exporter"}[5m])
)
)
record: node:node_cpu_utilization:ratio_rate5m
- expr: |-
avg by (cluster) (
node:node_cpu_utilization:ratio_rate5m
)
record: cluster:node_cpu:ratio_rate5m
- name: vm-health
rules:
- alert: TooManyRestarts
annotations:
description: |
Job {{ $labels.job }} (instance {{ $labels.instance }}) has restarted more than twice in the last 15 minutes. It might be crashlooping.
summary: '{{ $labels.job }} too many restarts (instance {{ $labels.instance
}})'
expr: changes(process_start_time_seconds{job=~".*(victoriametrics|vmselect|vminsert|vmstorage|vmagent|vmalert|vmsingle|vmalertmanager|vmauth).*"}[15m])
> 2
labels:
severity: critical
- alert: ServiceDown
annotations:
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down
for more than 2 minutes.'
summary: Service {{ $labels.job }} is down on {{ $labels.instance }}
expr: up{job=~".*(victoriametrics|vmselect|vminsert|vmstorage|vmagent|vmalert|vmsingle|vmalertmanager|vmauth).*"}
== 0
for: 2m
labels:
severity: critical
- alert: ProcessNearFDLimits
annotations:
description: |
Exhausting OS file descriptors limit can cause severe degradation of the process.
Consider to increase the limit as fast as possible.
summary: Number of free file descriptors is less than 100 for "{{ $labels.job
}}"("{{ $labels.instance }}") for the last 5m
expr: (process_max_fds - process_open_fds) < 100
for: 5m
labels:
severity: critical
- alert: TooHighMemoryUsage
annotations:
description: |
Too high memory usage may result into multiple issues such as OOMs or degraded performance.
Consider to either increase available memory or decrease the load on the process.
summary: It is more than 80% of memory used by "{{ $labels.job }}"("{{ $labels.instance
}}")
expr: (min_over_time(process_resident_memory_anon_bytes[10m]) / vm_available_memory_bytes)
> 0.8
for: 5m
labels:
severity: critical
- alert: TooHighCPUUsage
annotations:
description: |
Too high CPU usage may be a sign of insufficient resources and make process unstable. Consider to either increase available CPU resources or decrease the load on the process.
summary: More than 90% of CPU is used by "{{ $labels.job }}"("{{ $labels.instance
}}") during the last 5m
expr: rate(process_cpu_seconds_total[5m]) / process_cpu_cores_available > 0.9
for: 5m
labels:
severity: critical
- alert: TooHighGoroutineSchedulingLatency
annotations:
description: |
Go runtime is unable to schedule goroutines execution in acceptable time. This is usually a sign of insufficient CPU resources or CPU throttling. Verify that service has enough CPU resources. Otherwise, the service could work unreliably with delays in processing.
summary: '"{{ $labels.job }}"("{{ $labels.instance }}") has insufficient CPU
resources for >15m'
expr: histogram_quantile(0.99, sum(rate(go_sched_latencies_seconds_bucket[5m]))
by (le,job,instance,cluster)) > 0.1
for: 15m
labels:
severity: critical
- alert: TooManyLogs
annotations:
description: |
Logging rate for job \"{{ $labels.job }}\" ({{ $labels.instance }}) is {{ $value }} for last 15m. Worth to check logs for specific error messages.
summary: Too many logs printed for job "{{ $labels.job }}" ({{ $labels.instance
}})
expr: sum(increase(vm_log_messages_total{level="error"}[5m])) without (app_version,
location) > 0
for: 15m
labels:
severity: warning
- alert: TooManyTSIDMisses
annotations:
description: |
The rate of TSID misses during query lookups is too high for \"{{ $labels.job }}\" ({{ $labels.instance }}).
Make sure you're running VictoriaMetrics of v1.85.3 or higher.
Related issue https://github.com/VictoriaMetrics/VictoriaMetrics/issues/3502
summary: Too many TSID misses for job "{{ $labels.job }}" ({{ $labels.instance
}})
expr: rate(vm_missing_tsids_for_metric_id_total[5m]) > 0
for: 10m
labels:
severity: critical
- alert: ConcurrentInsertsHitTheLimit
annotations:
description: |
The limit of concurrent inserts on instance {{ $labels.instance }} depends on the number of CPUs.
Usually, when component constantly hits the limit it is likely the component is overloaded and requires more CPU.
In some cases for components like vmagent or vminsert the alert might trigger if there are too many clients
making write attempts. If vmagent's or vminsert's CPU usage and network saturation are at normal level, then
it might be worth adjusting `-maxConcurrentInserts` cmd-line flag.
summary: '{{ $labels.job }} on instance {{ $labels.instance }} is constantly
hitting concurrent inserts limit'
expr: avg_over_time(vm_concurrent_insert_current[1m]) >= vm_concurrent_insert_capacity
for: 15m
labels:
severity: warning
- alert: IndexDBRecordsDrop
annotations:
description: |
VictoriaMetrics could skip registering new timeseries during ingestion if they fail the validation process.
For example, `reason=too_long_item` means that time series cannot exceed 64KB. Please, reduce the number
of labels or label values for such series. Or enforce these limits via `-maxLabelsPerTimeseries` and
`-maxLabelValueLen` command-line flags.
summary: IndexDB skipped registering items during data ingestion with reason={{
$labels.reason }}.
expr: increase(vm_indexdb_items_dropped_total[5m]) > 0
labels:
severity: critical
- alert: RowsRejectedOnIngestion
annotations:
description: 'Ingested rows on instance "{{ $labels.instance }}" are rejected
due to the following reason: "{{ $labels.reason }}"'
summary: Some rows are rejected on "{{ $labels.instance }}" on ingestion attempt
expr: rate(vm_rows_ignored_total[5m]) > 0
for: 15m
labels:
severity: warning
- concurrency: 2
interval: 30s
name: vmagent
rules:
- alert: PersistentQueueIsDroppingData
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=49&var-instance={{
$labels.instance }}
description: Vmagent dropped {{ $value | humanize1024 }} from persistent queue
on instance {{ $labels.instance }} for the last 10m.
summary: Instance {{ $labels.instance }} is dropping data from persistent
queue
expr: sum(increase(vm_persistentqueue_bytes_dropped_total[5m])) without (path)
> 0
for: 10m
labels:
severity: critical
- alert: RejectedRemoteWriteDataBlocksAreDropped
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=79&var-instance={{
$labels.instance }}
description: Job "{{ $labels.job }}" on instance {{ $labels.instance }} drops
the rejected by remote-write server data blocks. Check the logs to find
the reason for rejects.
summary: Vmagent is dropping data blocks that are rejected by remote storage
expr: sum(increase(vmagent_remotewrite_packets_dropped_total[5m])) without (url)
> 0
for: 15m
labels:
severity: warning
- alert: TooManyScrapeErrors
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=31&var-instance={{
$labels.instance }}
description: Job "{{ $labels.job }}" on instance {{ $labels.instance }} fails
to scrape targets for last 15m
summary: Vmagent fails to scrape one or more targets
expr: increase(vm_promscrape_scrapes_failed_total[5m]) > 0
for: 15m
labels:
severity: warning
- alert: TooManyWriteErrors
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=77&var-instance={{
$labels.instance }}
description: Job "{{ $labels.job }}" on instance {{ $labels.instance }} responds
with errors to write requests for last 15m.
summary: Vmagent responds with too many errors on data ingestion protocols
expr: |-
(sum(increase(vm_ingestserver_request_errors_total[5m])) without (name,net,type)
+
sum(increase(vmagent_http_request_errors_total[5m])) without (path,protocol)) > 0
for: 15m
labels:
severity: warning
- alert: TooManyRemoteWriteErrors
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=61&var-instance={{
$labels.instance }}
description: |-
Vmagent fails to push data via remote write protocol to destination "{{ $labels.url }}"
Ensure that destination is up and reachable.
summary: Job "{{ $labels.job }}" on instance {{ $labels.instance }} fails
to push to remote storage
expr: rate(vmagent_remotewrite_retries_count_total[5m]) > 0
for: 15m
labels:
severity: warning
- alert: RemoteWriteConnectionIsSaturated
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=84&var-instance={{
$labels.instance }}
description: |-
The remote write connection between vmagent "{{ $labels.job }}" (instance {{ $labels.instance }}) and destination "{{ $labels.url }}" is saturated by more than 90% and vmagent won't be able to keep up.
This usually means that `-remoteWrite.queues` command-line flag must be increased in order to increase the number of connections per each remote storage.
summary: Remote write connection from "{{ $labels.job }}" (instance {{ $labels.instance
}}) to {{ $labels.url }} is saturated
expr: |-
(
rate(vmagent_remotewrite_send_duration_seconds_total[5m])
/
vmagent_remotewrite_queues
) > 0.9
for: 15m
labels:
severity: warning
- alert: PersistentQueueForWritesIsSaturated
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=98&var-instance={{
$labels.instance }}
description: Persistent queue writes for vmagent "{{ $labels.job }}" (instance
{{ $labels.instance }}) are saturated by more than 90% and vmagent won't
be able to keep up with flushing data on disk. In this case, consider to
decrease load on the vmagent or improve the disk throughput.
summary: Persistent queue writes for instance {{ $labels.instance }} are saturated
expr: rate(vm_persistentqueue_write_duration_seconds_total[5m]) > 0.9
for: 15m
labels:
severity: warning
- alert: PersistentQueueForReadsIsSaturated
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=99&var-instance={{
$labels.instance }}
description: Persistent queue reads for vmagent "{{ $labels.job }}" (instance
{{ $labels.instance }}) are saturated by more than 90% and vmagent won't
be able to keep up with reading data from the disk. In this case, consider
to decrease load on the vmagent or improve the disk throughput.
summary: Persistent queue reads for instance {{ $labels.instance }} are saturated
expr: rate(vm_persistentqueue_read_duration_seconds_total[5m]) > 0.9
for: 15m
labels:
severity: warning
- alert: SeriesLimitHourReached
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=88&var-instance={{
$labels.instance }}
description: Max series limit set via -remoteWrite.maxHourlySeries flag is
close to reaching the max value. Then samples for new time series will be
dropped instead of sending them to remote storage systems.
summary: Instance {{ $labels.instance }} reached 90% of the limit
expr: (vmagent_hourly_series_limit_current_series / vmagent_hourly_series_limit_max_series)
> 0.9
labels:
severity: critical
- alert: SeriesLimitDayReached
annotations:
dashboard: grafana.external.host/d/G7Z9GzMGz?viewPanel=90&var-instance={{
$labels.instance }}
description: Max series limit set via -remoteWrite.maxDailySeries flag is
close to reaching the max value. Then samples for new time series will be
dropped instead of sending them to remote storage systems.
summary: Instance {{ $labels.instance }} reached 90% of the limit
expr: (vmagent_daily_series_limit_current_series / vmagent_daily_series_limit_max_series)
> 0.9
labels:
severity: critical
- alert: ConfigurationReloadFailure
annotations:
description: Configuration hot-reload failed for vmagent on instance {{ $labels.instance
}}. Check vmagent's logs for detailed error message.
summary: Configuration reload failed for vmagent instance {{ $labels.instance
}}
expr: |-
vm_promscrape_config_last_reload_successful != 1
or
vmagent_relabel_config_last_reload_successful != 1
labels:
severity: warning
- alert: StreamAggrFlushTimeout
annotations:
description: 'Stream aggregation process can''t keep up with the load and
might produce incorrect aggregation results. Check logs for more details.
Possible solutions: increase aggregation interval; aggregate smaller number
of series; reduce samples'' ingestion rate to stream aggregation.'
summary: Streaming aggregation at "{{ $labels.job }}" (instance {{ $labels.instance
}}) can't be finished within the configured aggregation interval.
expr: increase(vm_streamaggr_flush_timeouts_total[5m]) > 0
labels:
severity: warning
- alert: StreamAggrDedupFlushTimeout
annotations:
description: 'Deduplication process can''t keep up with the load and might
produce incorrect results. Check docs https://docs.victoriametrics.com/stream-aggregation/#deduplication
and logs for more details. Possible solutions: increase deduplication interval;
deduplicate smaller number of series; reduce samples'' ingestion rate.'
summary: Deduplication "{{ $labels.job }}" (instance {{ $labels.instance }})
can't be finished within configured deduplication interval.
expr: increase(vm_streamaggr_dedup_flush_timeouts_total[5m]) > 0
labels:
severity: warning
- concurrency: 2
interval: 30s
name: vmcluster
rules:
- alert: DiskRunsOutOfSpaceIn3Days
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=113&var-instance={{
$labels.instance }}
description: |-
Taking into account current ingestion rate, free disk space will be enough only for {{ $value | humanizeDuration }} on instance {{ $labels.instance }}.
Consider to limit the ingestion rate, decrease retention or scale the disk space up if possible.
summary: Instance {{ $labels.instance }} will run out of disk space in 3 days
expr: |-
sum(vm_free_disk_space_bytes) without(path) /
(
rate(vm_rows_added_to_storage_total[1d]) * (
sum(vm_data_size_bytes{type!~"indexdb.*"}) without(type) /
sum(vm_rows{type!~"indexdb.*"}) without(type)
)
) < 3 * 24 * 3600 > 0
for: 30m
labels:
severity: critical
- alert: NodeBecomesReadonlyIn3Days
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=113&var-instance={{
$labels.instance }}
description: |-
Taking into account current ingestion rate, free disk space and -storage.minFreeDiskSpaceBytes instance {{ $labels.instance }} will remain writable for {{ $value | humanizeDuration }}.
Consider to limit the ingestion rate, decrease retention or scale the disk space up if possible.
summary: Instance {{ $labels.instance }} will become read-only in 3 days
expr: |-
sum(vm_free_disk_space_bytes - vm_free_disk_space_limit_bytes) without(path) /
(
rate(vm_rows_added_to_storage_total[1d]) * (
sum(vm_data_size_bytes{type!~"indexdb.*"}) without(type) /
sum(vm_rows{type!~"indexdb.*"}) without(type)
)
) < 3 * 24 * 3600 > 0
for: 30m
labels:
severity: warning
- alert: DiskRunsOutOfSpace
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=200&var-instance={{
$labels.instance }}
description: |-
Disk utilisation on instance {{ $labels.instance }} is more than 80%.
Having less than 20% of free disk space could cripple merges processes and overall performance. Consider to limit the ingestion rate, decrease retention or scale the disk space if possible.
summary: Instance {{ $labels.instance }} (job={{ $labels.job }}) will run
out of disk space soon
expr: |-
sum(vm_data_size_bytes) by (job,instance,cluster) /
(
sum(vm_free_disk_space_bytes) by (job,instance,cluster) +
sum(vm_data_size_bytes) by (job,instance,cluster)
) > 0.8
for: 30m
labels:
severity: critical
- alert: RequestErrorsToAPI
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=52&var-instance={{
$labels.instance }}
description: Requests to path {{ $labels.path }} are receiving errors. Please
verify if clients are sending correct requests.
summary: Too many errors served for {{ $labels.job }} path {{ $labels.path
}} (instance {{ $labels.instance }})
expr: increase(vm_http_request_errors_total[5m]) > 0
for: 15m
labels:
severity: warning
show_at: dashboard
- alert: RPCErrors
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=44&var-instance={{
$labels.instance }}
description: |-
RPC errors are interconnection errors between cluster components.
Possible reasons for errors are misconfiguration, overload, network blips or unreachable components.
summary: Too many RPC errors for {{ $labels.job }} (instance {{ $labels.instance
}})
expr: |-
(
sum(increase(vm_rpc_connection_errors_total[5m])) by (job,instance,cluster)
+
sum(increase(vm_rpc_dial_errors_total[5m])) by (job,instance,cluster)
+
sum(increase(vm_rpc_handshake_errors_total[5m])) by (job,instance,cluster)
) > 0
for: 15m
labels:
severity: warning
show_at: dashboard
- alert: TooHighChurnRate
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=102
description: |-
VM constantly creates new time series.
This effect is known as Churn Rate.
High Churn Rate tightly connected with database performance and may result in unexpected OOM's or slow queries.
summary: Churn rate is more than 10% for the last 15m
expr: |-
(
sum(rate(vm_new_timeseries_created_total[5m])) by (job,cluster)
/
sum(rate(vm_rows_inserted_total[5m])) by (job,cluster)
) > 0.1
for: 15m
labels:
severity: warning
- alert: TooHighChurnRate24h
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=102
description: |-
The number of created new time series over last 24h is 3x times higher than current number of active series.
This effect is known as Churn Rate.
High Churn Rate tightly connected with database performance and may result in unexpected OOM's or slow queries.
summary: Too high number of new series created over last 24h
expr: |-
sum(increase(vm_new_timeseries_created_total[24h])) by (job,cluster)
>
(sum(vm_cache_entries{type="storage/hour_metric_ids"}) by (job,cluster) * 3)
for: 15m
labels:
severity: warning
- alert: TooHighSlowInsertsRate
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=108
description: High rate of slow inserts may be a sign of resource exhaustion
for the current load. It is likely more RAM is needed for optimal handling
of the current number of active time series. See also https://github.com/VictoriaMetrics/VictoriaMetrics/issues/3976#issuecomment-1476883183
summary: Percentage of slow inserts is more than 5% for the last 15m
expr: |-
(
sum(rate(vm_slow_row_inserts_total[5m])) by (job,cluster)
/
sum(rate(vm_rows_inserted_total[5m])) by (job,cluster)
) > 0.05
for: 15m
labels:
severity: warning
- alert: VminsertVmstorageConnectionIsSaturated
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=139&var-instance={{
$labels.instance }}
description: |-
The connection between vminsert (instance {{ $labels.instance }}) and vmstorage (instance {{ $labels.addr }}) is saturated by more than 90% and vminsert won't be able to keep up.
This usually means that more vminsert or vmstorage nodes must be added to the cluster in order to increase the total number of vminsert -> vmstorage links.
summary: Connection between vminsert on {{ $labels.instance }} and vmstorage
on {{ $labels.addr }} is saturated
expr: rate(vm_rpc_send_duration_seconds_total[5m]) > 0.9
for: 15m
labels:
severity: warning
show_at: dashboard
- name: vmoperator
rules:
- alert: LogErrors
annotations:
dashboard: '{{ $externalURL }}/d/1H179hunk/victoriametrics-operator?ds={{
$labels.dc }}&orgId=1&viewPanel=16'
description: 'Operator has too many errors at logs: {{ $value}}, check operator
logs'
summary: 'Too many errors at logs of operator: {{ $value}}'
expr: |-
sum(
rate(
operator_log_messages_total{
level="error",job=~".*((victoria.*)|vm)-?operator"
}[5m]
)
) by (cluster) > 0
for: 15m
labels:
severity: warning
show_at: dashboard
- alert: ReconcileErrors
annotations:
dashboard: '{{ $externalURL }}/d/1H179hunk/victoriametrics-operator?ds={{
$labels.dc }}&orgId=1&viewPanel=10'
description: 'Operator cannot parse response from k8s api server, possible
bug: {{ $value }}, check operator logs'
summary: 'Too many errors at reconcile loop of operator: {{ $value}}'
expr: |-
sum(
rate(
controller_runtime_reconcile_errors_total{
job=~".*((victoria.*)|vm)-?operator"
}[5m]
)
) by (cluster) > 0
for: 10m
labels:
severity: warning
show_at: dashboard
- alert: HighQueueDepth
annotations:
dashboard: '{{ $externalURL }}/d/1H179hunk/victoriametrics-operator?ds={{
$labels.dc }}&orgId=1&viewPanel=20'
description: 'Operator cannot handle reconciliation load for controller: `{{-
$labels.name }}`, current depth: {{ $value }}'
summary: 'Too many `{{- $labels.name }}` in queue: {{ $value }}'
expr: |-
sum(
workqueue_depth{
job=~".*((victoria.*)|vm)-?operator",
name=~"(vmagent|vmalert|vmalertmanager|vmauth|vmcluster|vmnodescrape|vmpodscrape|vmprobe|vmrule|vmservicescrape|vmsingle|vmstaticscrape)"
}
) by (name,cluster) > 10
for: 15m
labels:
severity: warning
show_at: dashboard
- alert: BadObjects
annotations:
dashboard: '{{ $externalURL }}/d/1H179hunk/victoriametrics-operator?ds={{
$labels.dc }}&orgId=1'
description: Operator got incorrect resources in controller {{ $labels.controller
}}, check operator logs
summary: Incorrect `{{ $labels.controller }}` resources in the cluster
expr: |-
sum(
operator_controller_bad_objects_count{job=~".*((victoria.*)|vm)-?operator"}
) by (controller,cluster) > 0
for: 15m
labels:
severity: warning
show_at: dashboard
- concurrency: 2
interval: 30s
name: vmsingle
rules:
- alert: DiskRunsOutOfSpaceIn3Days
annotations:
dashboard: grafana.external.host/d/wNf0q_kZk?viewPanel=73&var-instance={{
$labels.instance }}
description: |-
Taking into account current ingestion rate, free disk space will be enough only for {{ $value | humanizeDuration }} on instance {{ $labels.instance }}.
Consider to limit the ingestion rate, decrease retention or scale the disk space if possible.
summary: Instance {{ $labels.instance }} will run out of disk space soon
expr: |-
sum(vm_free_disk_space_bytes) without(path) /
(
rate(vm_rows_added_to_storage_total[1d]) * (
sum(vm_data_size_bytes{type!~"indexdb.*"}) without(type) /
sum(vm_rows{type!~"indexdb.*"}) without(type)
)
) < 3 * 24 * 3600 > 0
for: 30m
labels:
severity: critical
- alert: NodeBecomesReadonlyIn3Days
annotations:
dashboard: grafana.external.host/d/oS7Bi_0Wz?viewPanel=113&var-instance={{
$labels.instance }}
description: |-
Taking into account current ingestion rate and free disk space instance {{ $labels.instance }} is writable for {{ $value | humanizeDuration }}.
Consider to limit the ingestion rate, decrease retention or scale the disk space up if possible.
summary: Instance {{ $labels.instance }} will become read-only in 3 days
expr: |-
sum(vm_free_disk_space_bytes - vm_free_disk_space_limit_bytes) without(path) /
(
rate(vm_rows_added_to_storage_total[1d]) * (
sum(vm_data_size_bytes{type!~"indexdb.*"}) without(type) /
sum(vm_rows{type!~"indexdb.*"}) without(type)
)
) < 3 * 24 * 3600 > 0
for: 30m
labels:
severity: warning
- alert: DiskRunsOutOfSpace
annotations:
dashboard: grafana.external.host/d/wNf0q_kZk?viewPanel=53&var-instance={{
$labels.instance }}
description: |-
Disk utilisation on instance {{ $labels.instance }} is more than 80%.
Having less than 20% of free disk space could cripple merge processes and overall performance. Consider to limit the ingestion rate, decrease retention or scale the disk space if possible.
summary: Instance {{ $labels.instance }} (job={{ $labels.job }}) will run
out of disk space soon
expr: |-
sum(vm_data_size_bytes) by (job,instance,cluster) /
(
sum(vm_free_disk_space_bytes) by (job,instance,cluster) +
sum(vm_data_size_bytes) by (job,instance,cluster)
) > 0.8
for: 30m
labels:
severity: critical
- alert: RequestErrorsToAPI
annotations:
dashboard: grafana.external.host/d/wNf0q_kZk?viewPanel=35&var-instance={{
$labels.instance }}
description: Requests to path {{ $labels.path }} are receiving errors. Please
verify if clients are sending correct requests.
summary: Too many errors served for path {{ $labels.path }} (instance {{ $labels.instance
}})
expr: increase(vm_http_request_errors_total[5m]) > 0
for: 15m
labels:
severity: warning
- alert: TooHighChurnRate
annotations:
dashboard: grafana.external.host/d/wNf0q_kZk?viewPanel=66&var-instance={{
$labels.instance }}
description: |-
VM constantly creates new time series on "{{ $labels.instance }}".
This effect is known as Churn Rate.
High Churn Rate tightly connected with database performance and may result in unexpected OOM's or slow queries.
summary: Churn rate is more than 10% on "{{ $labels.instance }}" for the last
15m
expr: |-
(
sum(rate(vm_new_timeseries_created_total[5m])) by (instance,cluster)
/
sum(rate(vm_rows_inserted_total[5m])) by (instance,cluster)
) > 0.1
for: 15m
labels:
severity: warning
- alert: TooHighChurnRate24h
annotations:
dashboard: grafana.external.host/d/wNf0q_kZk?viewPanel=66&var-instance={{
$labels.instance }}
description: |-
The number of created new time series over last 24h is 3x times higher than current number of active series on "{{ $labels.instance }}".
This effect is known as Churn Rate.
High Churn Rate tightly connected with database performance and may result in unexpected OOM's or slow queries.
summary: Too high number of new series on "{{ $labels.instance }}" created
over last 24h
expr: |-
sum(increase(vm_new_timeseries_created_total[24h])) by (instance,cluster)
>
(sum(vm_cache_entries{type="storage/hour_metric_ids"}) by (instance,cluster) * 3)
for: 15m
labels:
severity: warning
- alert: TooHighSlowInsertsRate
annotations:
dashboard: grafana.external.host/d/wNf0q_kZk?viewPanel=68&var-instance={{
$labels.instance }}
description: High rate of slow inserts on "{{ $labels.instance }}" may be
a sign of resource exhaustion for the current load. It is likely more RAM
is needed for optimal handling of the current number of active time series.
See also https://github.com/VictoriaMetrics/VictoriaMetrics/issues/3976#issuecomment-1476883183
summary: Percentage of slow inserts is more than 5% on "{{ $labels.instance
}}" for the last 15m
expr: |-
(
sum(rate(vm_slow_row_inserts_total[5m])) by (instance,cluster)
/
sum(rate(vm_rows_inserted_total[5m])) by (instance,cluster)
) > 0.05
for: 15m
labels:
severity: warning
VMAlert
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMAlert
metadata:
labels:
cluster: clusterName
name: vmalert-0
namespace: clusterName
spec:
datasource:
url: http://shturval-monitoring-vmselect.victoria-metrics:8481/select/2107312257/prometheus
evaluationInterval: 30s
image: {}
notifiers:
- url: http://vmalertmanager-shturval-metrics-collector.victoria-metrics:9093
remoteRead:
url: http://shturval-monitoring-vmselect.victoria-metrics:8481/select/2107312257/prometheus
remoteWrite:
url: http://shturval-monitoring-vminsert.victoria-metrics:8480/insert/2107312257/prometheus
resources:
limits:
cpu: 200m
memory: 256Mi
requests:
cpu: 100m
memory: 128Mi
ruleSelector:
matchLabels:
monitoringid: "0"
Вместо clusterName в параметрах cluster и namespace укажите имя кластера управления.
Troubleshooting
При обновлении на версию 2.10.0 могут возникать ситуации, когда не все узлы кластера с провайдером Shturval v2 обновляются самостоятельно на новую версию. Для исправления ситуации необходимо в обновляемом кластере:
- В разделе “Администрирование” перейти на страницу “Конфигурация узлов”.
- В списке созданных конфигураций найдите объекты, содержащие префикс “kubernetes-update”, проставьте каждому объекту приоритет 100.
Оставшиеся узлы обновятся самостоятельно.