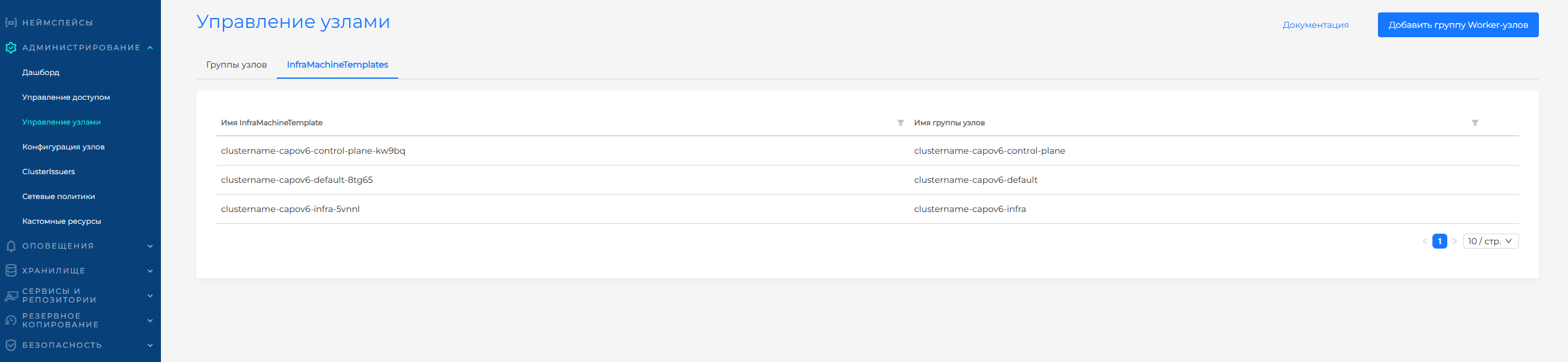
Управление узлами
На странице Управление узлами доступно управление группами узлов, конфигурацией групп узлов, а также управлением объектами healthchecks для групп узлов кластера.
На странице есть 2 вкладки:
- Группы узлов;
- InfraMachineTemplates.
Группы узлов
Страница разделена на блоки:
- Control Plane, в которую входят Master-узлы;
- Workers, в которую входят группы Worker-узлов.
Для группы Master-узлов и каждой группы Worker-узлов отображено:
- количество узлов в группе;
- количество работающих узлов в группе (узлы со статусом ready).
Скриншот
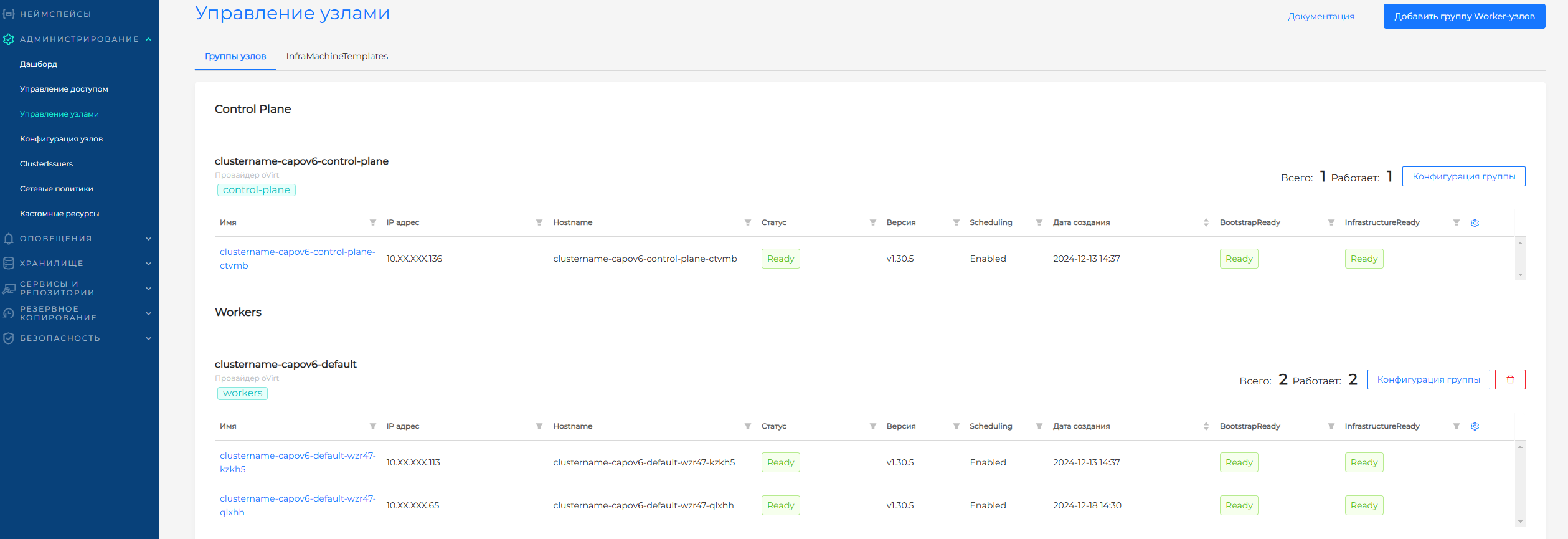
В таблицах для Control Plane и Workers вы можете настроить параметры отображения. Для этого нажмите на шестеренку в правом верхнем углу таблицы отображения узлов и выберите необходимые параметры.
Группам узлов присваивается провайдер, выбранный при создании кластера.
Конфигурация Control Plane
На странице “Управление узлами” клиентского кластера справа от названия группы ControlPlane узлов нажмите на кнопку “Конфигурация группы”. Количество узлов, параметры присоединения узла в группу, сайзинг узлов и machinehealthcheck доступны в конфигурации группы узлов. На открывшейся странице доступны вкладки:
- Конфигурация машин;
- InfraMachineTemplate;
- MachineHealthCheck.
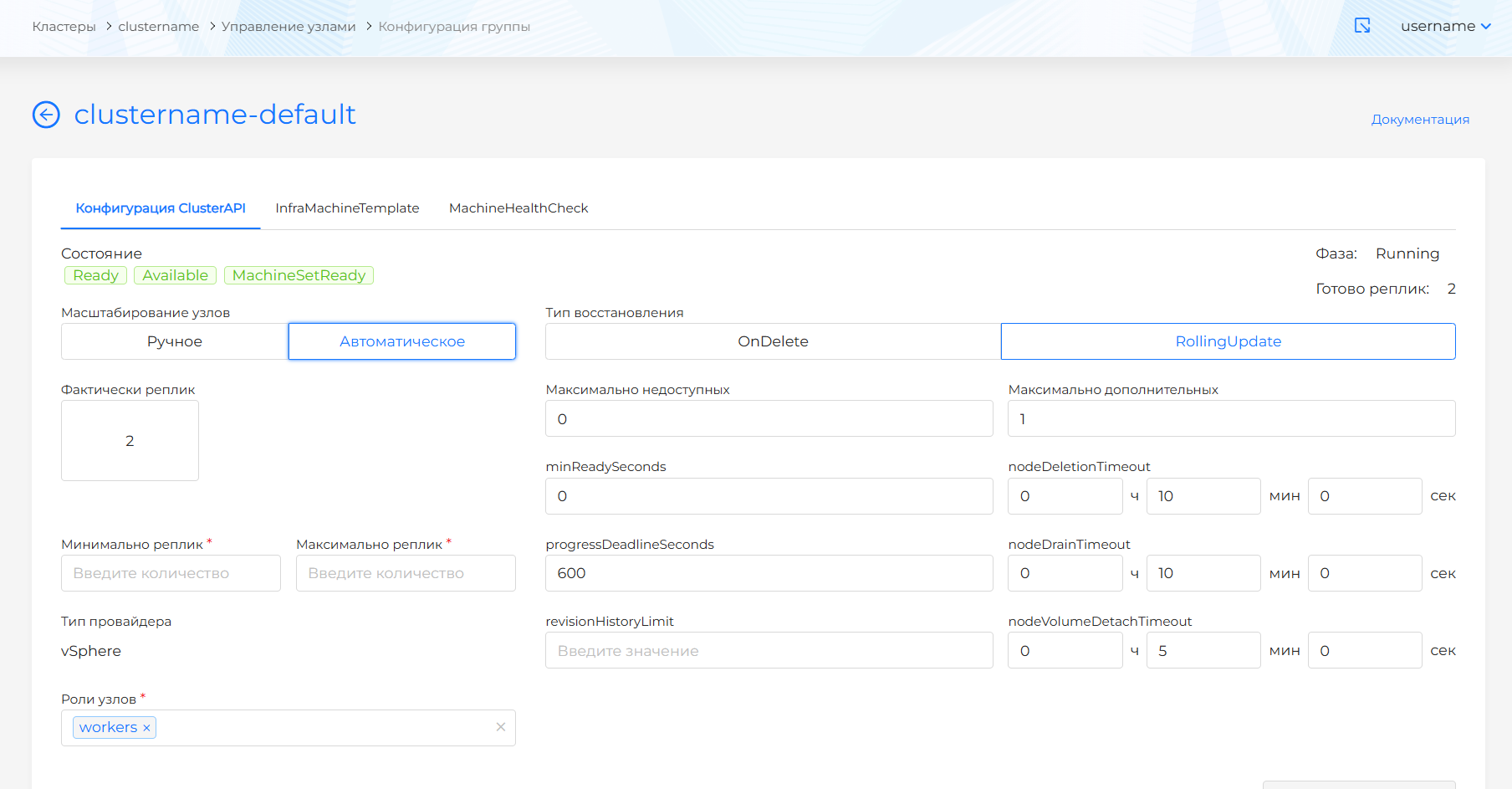
На вкладке “Конфигурация машин” есть возможность указать параметры ClusterAPI, KubeadmControlPlane.
ClusterAPI
Скриншот
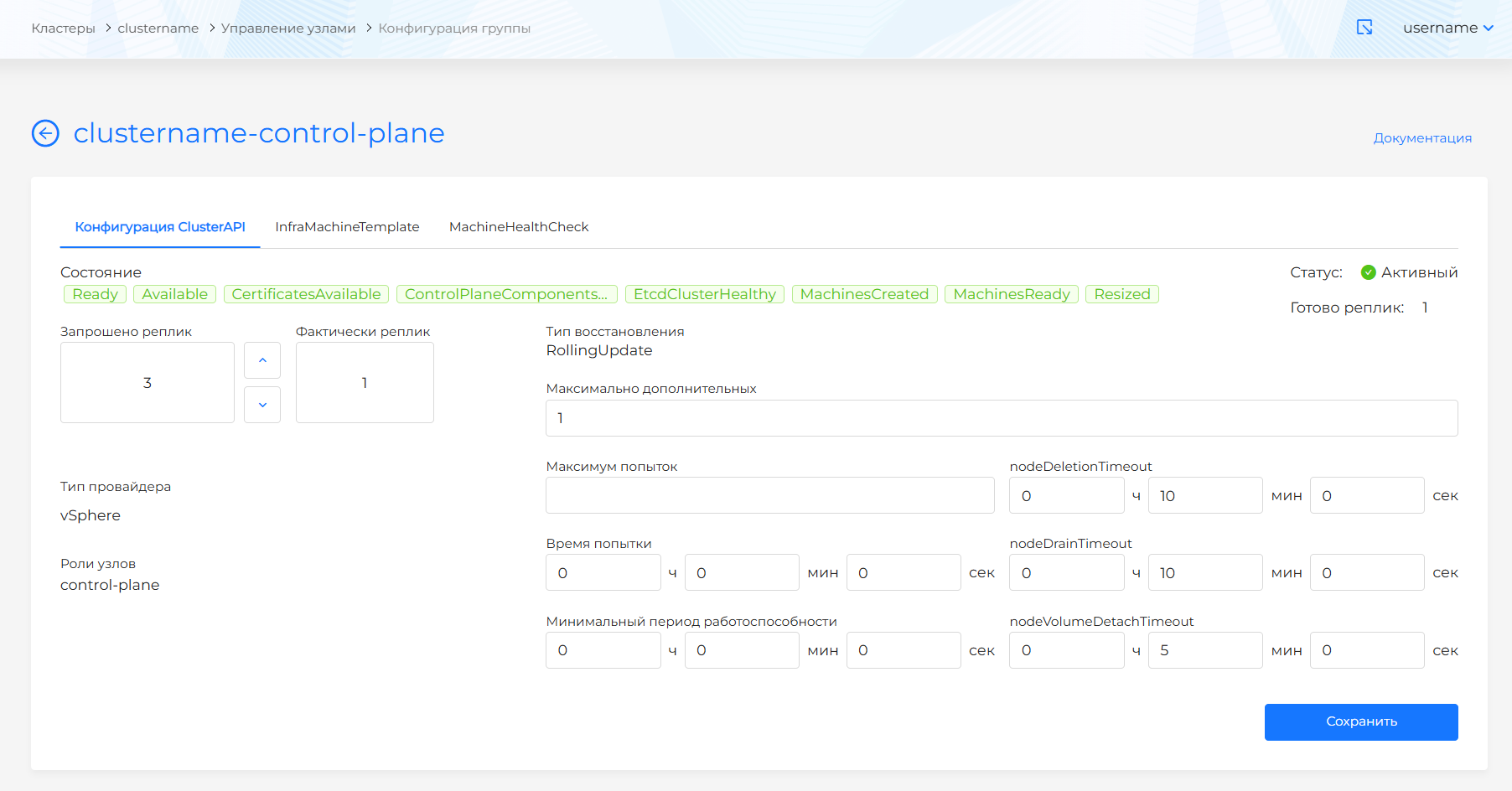
Название группы формируется по принципу название кластера плюс постфикс “-control-plane”.
- запрашиваемое количество количество узлов. Для группы Master-узлов доступно только указание нечетного количества узлов, т.к. etcd размещен на Master-узлах и для получения кворума в etcd требуется нечетное количество узлов. Для обеспечения отказоустойчивости в кластере рекомендуется выделение 3 или 5 Master-узлов.
Обратите внимание! Не рекомендуем уменьшать количество Master-узлов в кластере управления. Это может привести к поломке кластера управления!
- стратегия восстановления: RollingUpdate, т.е. изменения в конфигурации будут применяться последовательно. Для стратегии требуется указать количество дополнительных узлов (MaxSurge). Указать можно в абсолютных (целое) или относительных (в %) значениях.
- nodeDeletionTimeout: определяет, как долго capi-controller-manager будет пытаться удалить узел, после того как ресурс Machine будет помечен на удаление. При значении 0 попытки удаления будут повторяться бесконечно. Если значение не указано, будет использовано значение по умолчанию (10 секунд) для этого свойства ресурса Machine.
- nodeDrainTimeout - это общее количество времени, которое контроллер потратит на слив/освобождение узла. Значение по умолчанию равно 0, что означает, время ожидания освобождения узла не ограниченно по времени и может ожидать сколько угодно. ПРИМЕЧАНИЕ: NodeDrainTimeout отличается от
kubectl drain --timeout. - nodeVolumeDetachTimeout - это общее количество времени, которое контроллер потратит на ожидание отсоединения всех томов (volumes). Значение по умолчанию равно 0, это означает, что тома (volumes) будут ожидать отсоединения без какого-либо ограничения по времени и может ожидать сколько угодно. По умолчанию для ресурса Machine установлено значение 10 секунд.
KubeadmControlPlane
Выберите стратегию ремедиации, т.е. восстановления узла после идентификации его как нездорового. Позволяет детально настроить порядок восстановления для группы ControlPlane. Для управления доступны параметры:
- Максимум попыток (maxRetry) - максимальное количество повторных попыток при попытке исправления неисправной машины. Повторная попытка происходит, когда машина, созданная в качестве замены неисправной машины, также выходит из строя. Если не задано (по умолчанию), попытки исправления будут повторяться бесконечно.
- Время попытки (retryPeriod) - параметр ожидания времени, которое должно пройти перед началом новой попытки создания машины, после неудачной попытки создания машины. По умолчанию не задано, что значит, что новая попытка будет произведена немедленно.
- Минимальный период работоспособности (minHealthyPeriod)- период времени, по прошествии которого считать, что машина здорова. Приводит к сбрасыванию счетчика количества восстановления машины. Если машина помечена как неработоспособная по истечении minHealthyPeriod (по умолчанию 1 ч) с момента предыдущего исправления, это больше не считается повторной попыткой, поскольку предполагается, что новая проблема не связана с предыдущей.
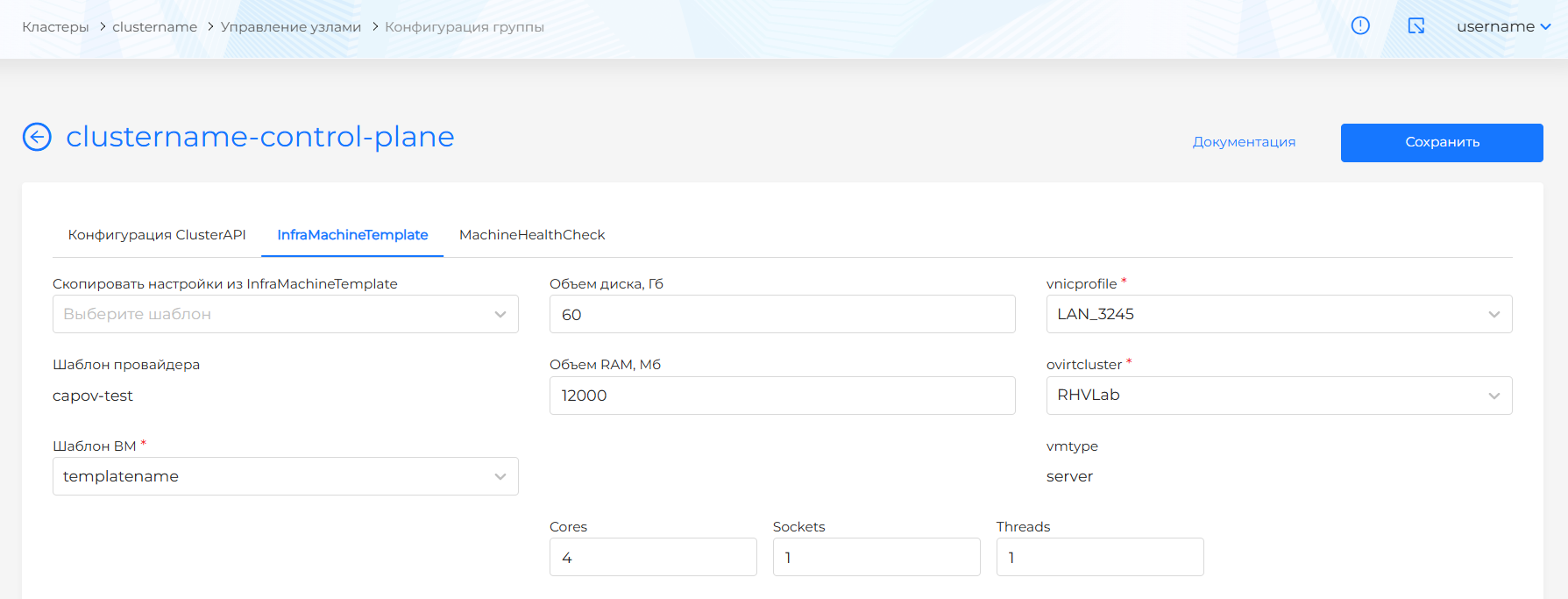
InfraMachineTemplate
На вкладке InfraMachineTemplate есть возможность изменить параметры шаблона инфраструктуры, применив новые значения вручную или скопировав значения из другого существующего шаблона. В зависимости от вида провайдера, происходит редактирование/создание ресурса:
- OVirtMachineTemplate
- VSphereMachineTemplate
- OpenStackMachineTemplate
- BasisMachineTemplate
- ShturvalMachineTemplate
- YandexMachineTemplate
Для OVirtMachineTemplate доступны для конфигурации параметры:
- CPU:
- cores
- sockets
- threads
- Объем RAM, Мб (sizemb)
- Объем диска, Гб (osdisksizegb)
- nics:
- vnicprofile
- Шаблон ВМ (template): доступны шаблоны ВМ экземпляра провайдера, на котором развернут кластер. Подробнее о создании шаблона ВМ здесь.
Скриншот
Для VSphereMachineTemplate доступны для конфигурации параметры:
- datacenter (выпадающий список всех датацентров, доступных для сервисной учетной записи экземпляра провайдера)
- datastore (выпадающий список всех датасторов, доступных для сервисной учетной записи экземпляра провайдера)
- Объем диска, Гб (diskGiB)
- Объем RAM, Мб (memoryMiB)
- Folder (путь до места создания ВМ)
- Количество ядер (numCPUs)
- Имя сети (networkName)
- Ресурсный пул (resourcePool)
- Шаблон ВМ (template): доступны шаблоны ВМ экземпляра провайдера, на котором развернут кластер. Подробнее о создании шаблона ВМ здесь.
Скриншот
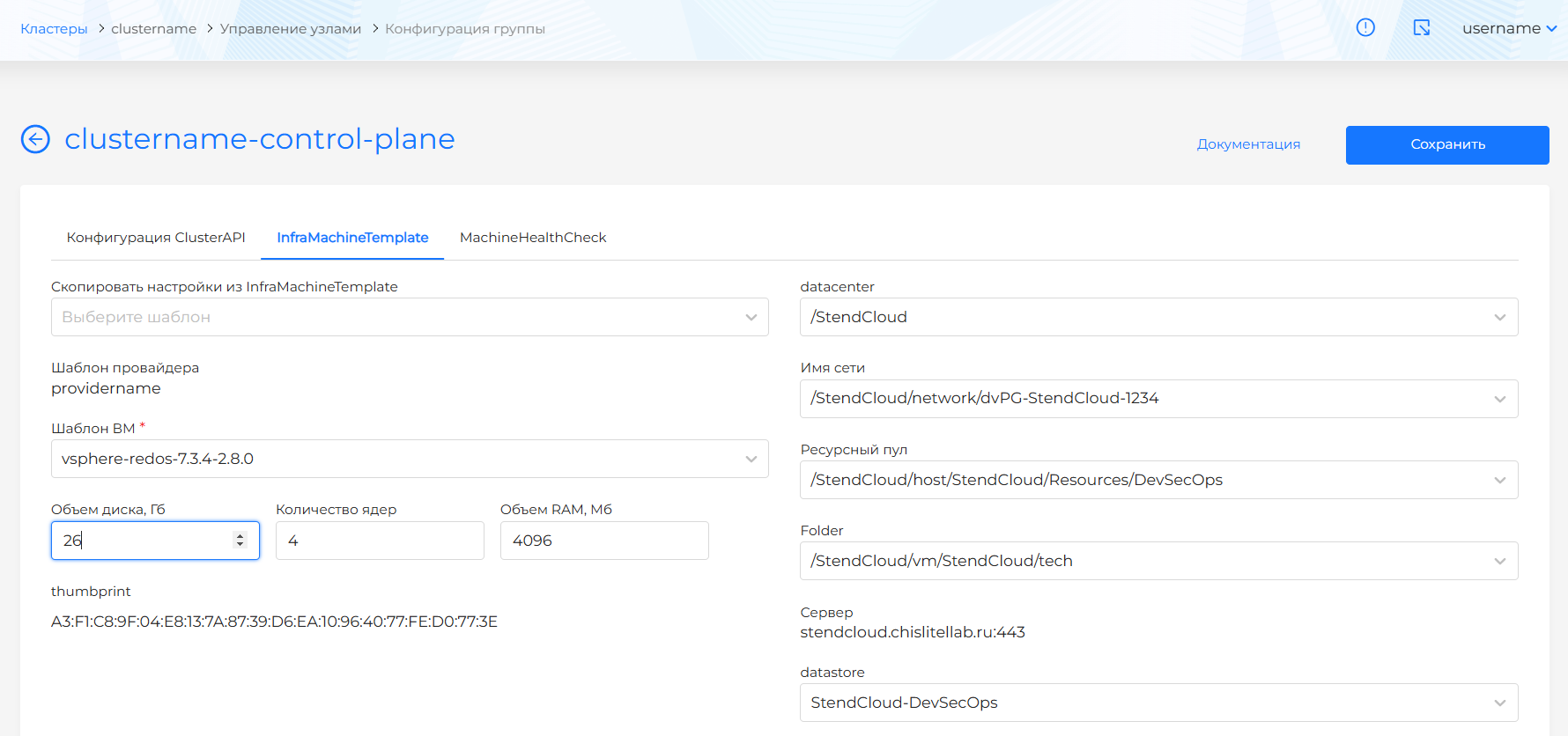
Для OpenStackMachineTemplate доступны для конфигурации параметры:
- cloudName
- flavor (типы ВМ)
- sshKeyName
- volumeType
- Объем диска, Гб
- Шаблон ВМ (template): доступны шаблоны ВМ экземпляра провайдера, на котором развернут кластер. Подробнее о создании шаблона ВМ здесь.
Параметр зоны доступности в OpenStackMachineTemplate доступен только для просмотра. Шаблон ВМ содержит зону доступности, если она была задана в конфигурации Master-узлов на этапе создания кластера.
Скриншот
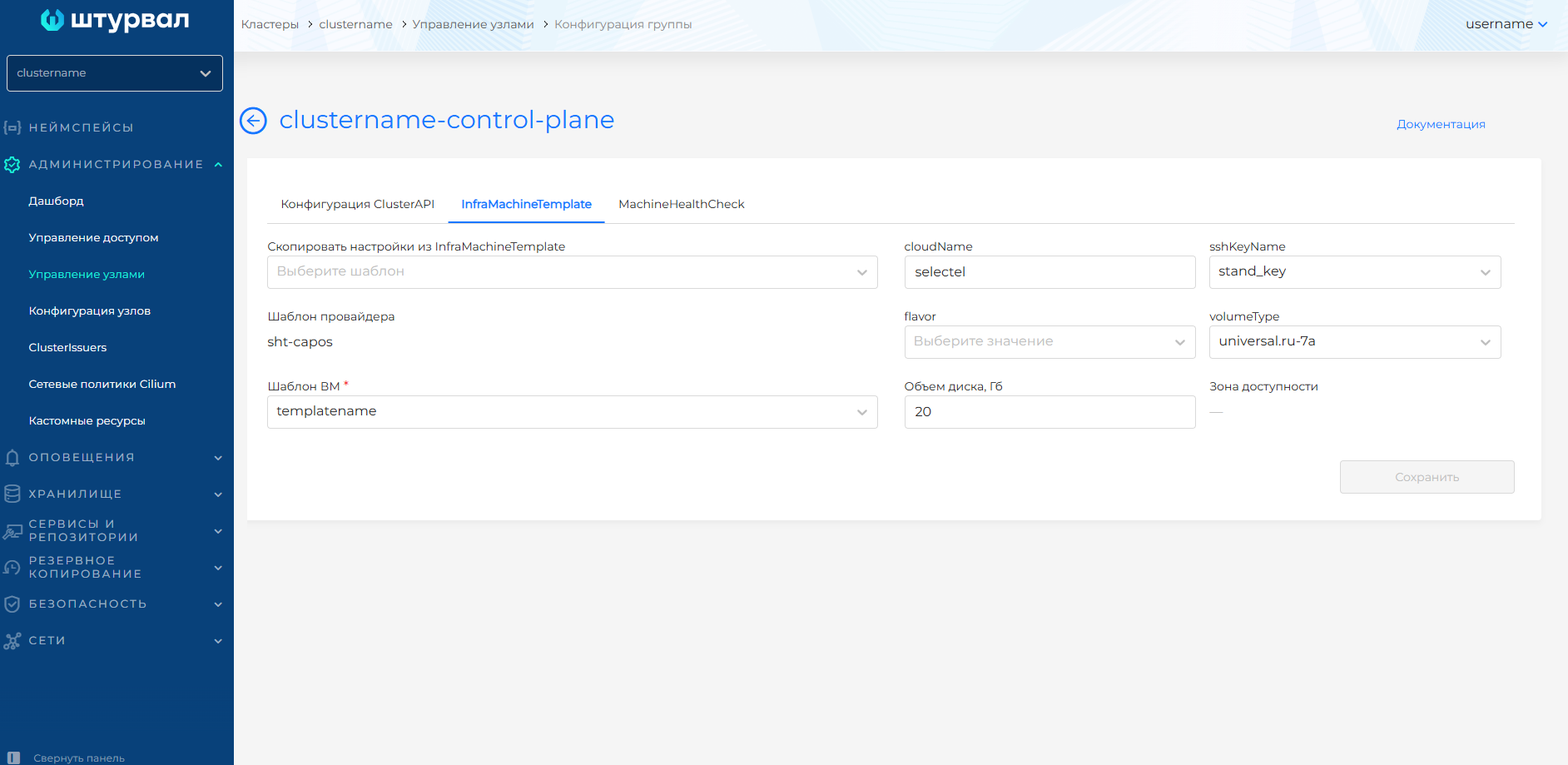
Для BasisMachineTemplate доступны параметры:
- Количество ядер;
- Объем RAM, Мб;
- Объем диска, Гб;
- Ресурсная группа;
- Имя VINS;
- Имя ExtNet.
Скриншот
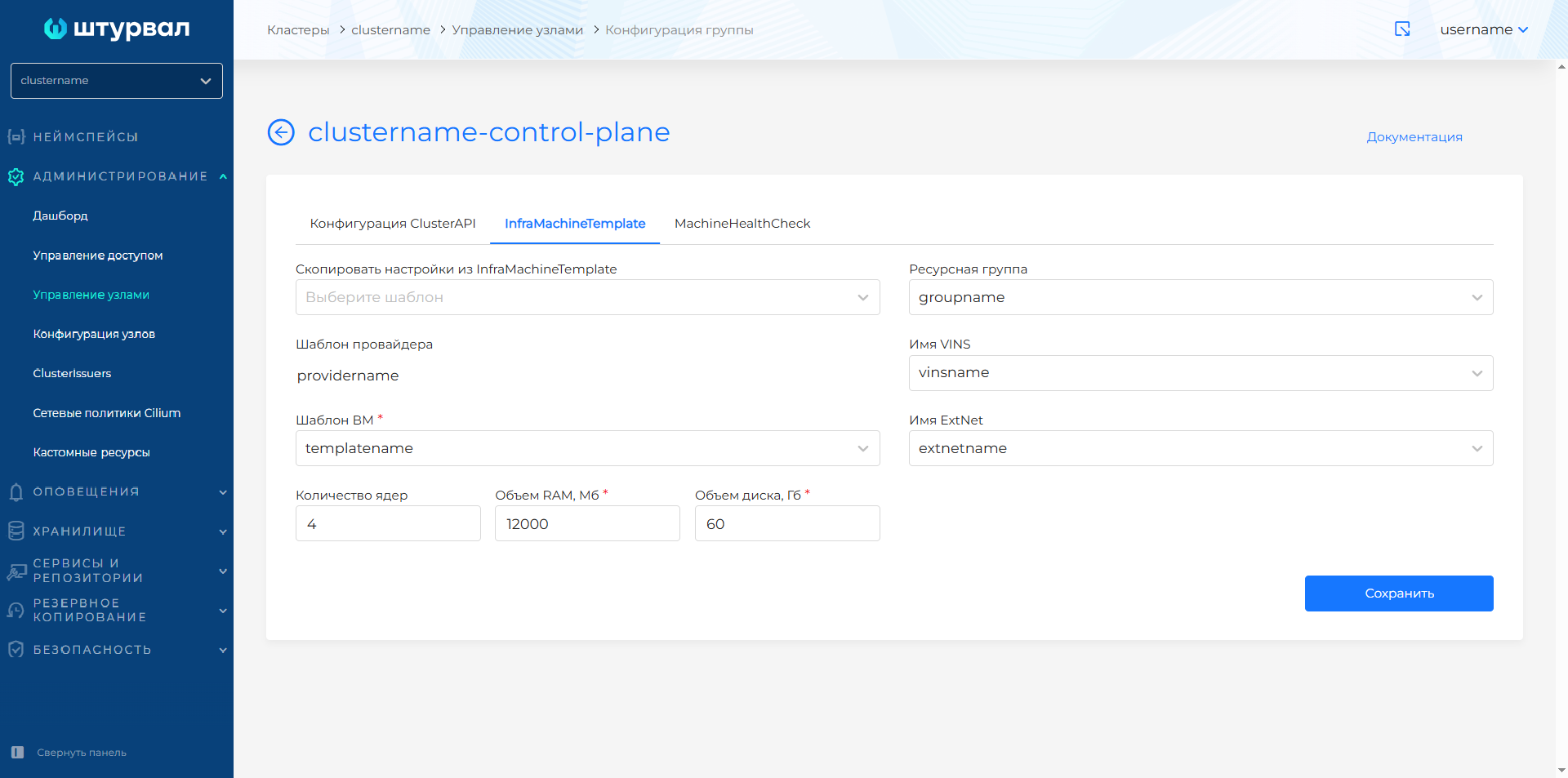
Для ShturvalMachineTemplate доступны параметры конфигурации в базовом режиме и режиме расширенных настроек. По умолчанию включен базовый режим.
В базовом режиме выберите роль хостов, чтобы определить присоединение только хостов с выбранной ролью при масштабировании группы узлов. После выбора роли в блоке Потенциально доступные хосты будут отображены свободные хосты с заданной ролью.
Скриншот
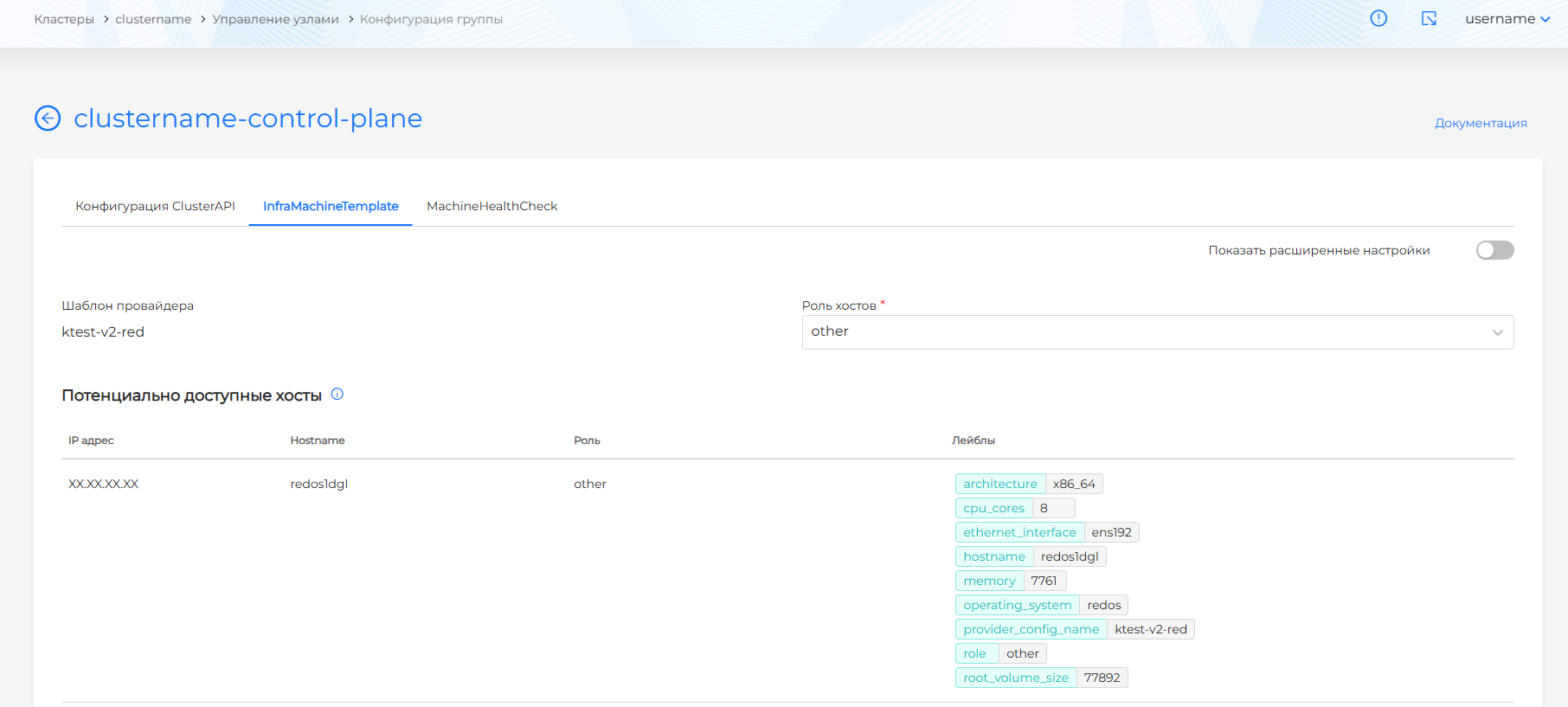
Для включения режима расширенных настроек переведите тумблер Показать расширенные настройки в активное состояние. При переходе из режима расширенных настроек в базовый режим, изменения будут утеряны.
В расширенных настройках вы можете задать совпадающие лейблы и выражения, чтобы определить доступные хосты для присоединения при масштабировании группы узлов:
- при добавлении лейбла хоста в открывшемся окне выберите ключ. Автоматически будет задано значение, соответствующее ключу лейбла существующего хоста в экземпляре провайдера Shturval v2.
- при добавлении лейбла хоста в открывшемся окне выберите ключ и оператора. Доступные операторы:
- In - будут выбраны хосты с совпадающим ключом и значением. Значение будет заполнено автоматически или предложено на выбор в соответствии с указанным ключом лейбла хоста, без возможности изменения;
- NotIn - не выбираются хосты с совпадающим ключом и значением. Значение будет заполнено автоматически или предложено на выбор в соответствии со значением указанного ключа лейбла, без возможности изменения;
- Exists - будут выбраны хосты с совпадающим ключом. Указывать значение не требуется;
- DoesNotExist - не выбираются хосты с совпадающим ключом. Указывать значение не требуется;
При указании нескольких совпадающих выражений, будут отображены доступные хосты, соответствующие всем выражениям.
Скриншот
Обратите внимание!
- Изменение конфигурации InfraMachineTemplate приведет к пересозданию узлов.
- Лейблы, указанные в селекторе в качестве совпадающих в одной группе узлов, должны быть указаны в совпадающих выражениях в качестве исключения в других группах узлов.
Для YandexMachineTemplate доступны для конфигурации параметры:
- Тип платформы;
- Тип диска;
- Объем RAM. Доступен выбор единицы измерения: Gi, Mi;
- Объем диска. Доступен выбор единицы измерения: Gi, Mi;
- cpuCores;
- Шаблон ВМ (template): доступны шаблоны ВМ экземпляра провайдера, на котором развернут кластер. Подробнее о создании шаблона ВМ здесь.
Скриншот
MachineHealthCheck
Скриншот
Для Master-узлов на вкладке MachineHealthCheck можно:
- настроить разные конфигурации MachineHealthCheck для проверки работоспособности машин. При инсталляции клиентского кластера монтируется дефолтная MachineHealthCheck для групп Master-узлов. Для конфигурации дополнительных MachineHealthChecks, нажмите + Добавить. Когда создано несколько конфигураций, на вкладке отображается список MachineHealthChecks.
- перейти к просмотру и редактированию конфигурации MachineHealthCheck.
Чтобы настроить конфигурацию MachineHealthCheck:
- задайте название MachineHealthCheck. После сохранения название нельзя изменить.
- можно задать maxUnhealthy в %. Параметр определяет максимальный процент нездоровых узлов в группе.
Обратите внимание! MachineHealthCheck не будет восстанавливать узлы, если количество нездоровых Master-узлов в группе больше, чем задано в maxUnhealthy.
Примеры
1. Значение maxUnhealthy - 90%:
В группе 3 Master-узла, где 2 узла нездоровы. Следовательно, количество нездоровых узлов = 66%, что меньше установленного значения *maxUnhealthy*. В этом случае узлы будут восстановлены.
2. Значение maxUnhealthy - 40%:
В группе 3 Master-узла, где 2 узла нездоровы. Следовательно, количество нездоровых узлов = 66%, что больше установленного значения *maxUnhealthy*. В этом случае узлы не будут восстановлены.
- можно задать nodeStartupTimeout время ожидания присоединения узла к кластеру. Слишком маленькое значение может привести к тому, что виртуальной машине не хватит времени для создания и присоединения, попытки присоединить узел уйдут в цикл.
Пример
Значение nodeStartupTimeout - 10 мин:
В этом случае, прежде чем считать узел нездоровым, должно пройти 10 минут.
Ожидается, что этого времени достаточно для присоединения узла к кластеру.
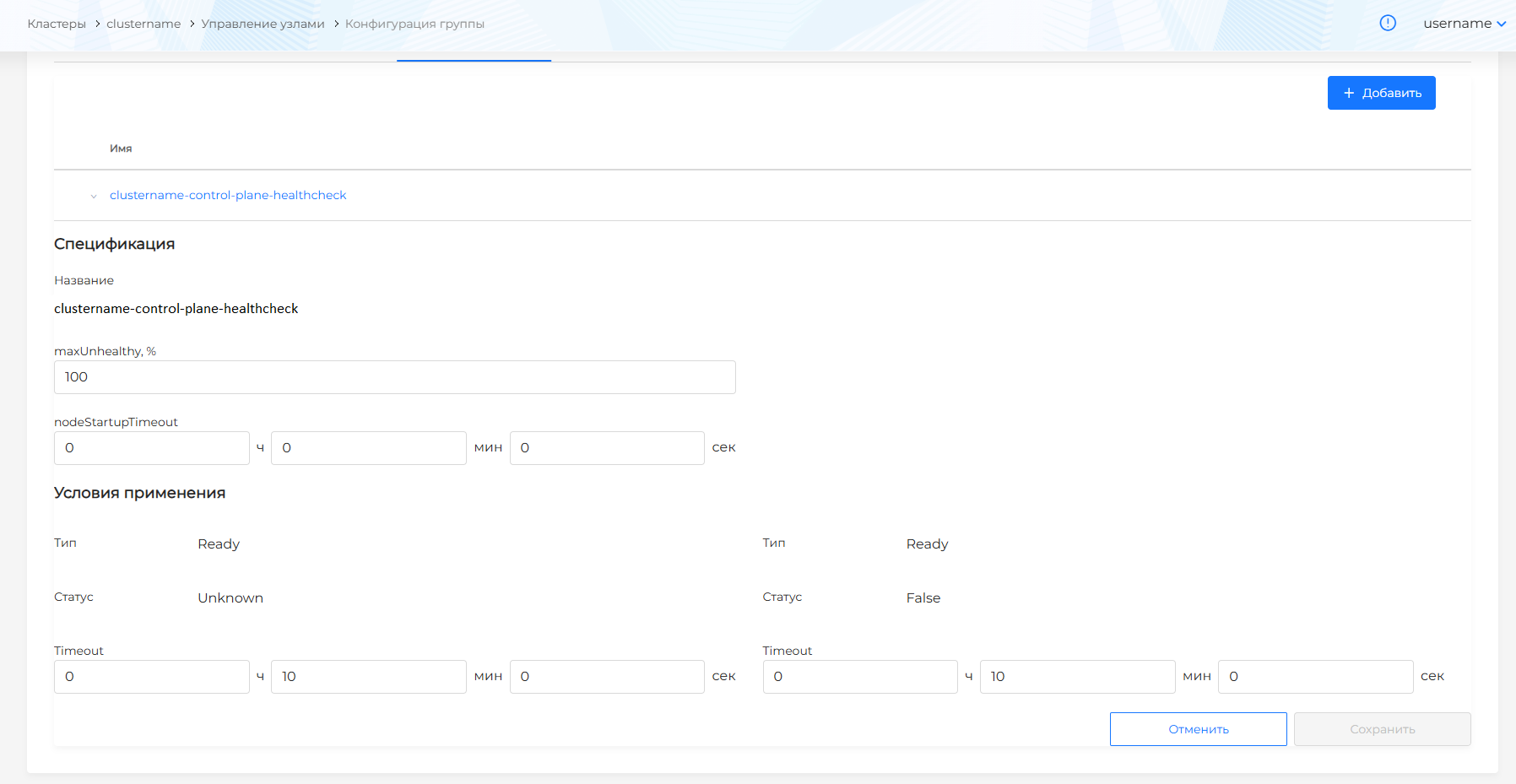
- в блоке Условия применения (unhealthyConditions) настройте параметры проверки узлов, при соблюдении которых узел будет считаться нездоровым:
- выберите Тип состояния узла. Доступные типы: NetworkUnavailable, DiskPressure, MemoryPressure, PIDPressure, Ready.
- выберите Статус состояния узла: True, False, Unknown.
- задайте Timeout - время ожидания, по истечению которого статус узла будет считаться действительным. Рекомендуется не устанавливать слишком короткий период Timeout, чтобы не происходило ложного перезапуска, пока узел переходит в исправное состояние. Длительный период Timeout может привести к простоям рабочей нагрузки на неработоспособном узле.
Пример
Условия применения:
Тип - Ready
Статус - Unknown
Timeout - 5 мин
Тип - Ready
Статус - False
Timeout - 5 мин
MachineHealthCheck сработает, если при проверке выявлено, что по истечении 5 минут наступит хотя бы одно из условий:
- узел находится в состоянии Ready-Unknown;
- узел будет в состоянии Ready-False.
После создания MachineHealthCheck будет добавлен в список проверок на вкладке MachineHealthCheck.
Чтобы перейти к просмотру и редактированию, нажмите на строчку с названием MachineHealthCheck. В открывшемся окне можно изменить параметры maxUnhealthy, nodeStartupTimeout и Timeout в условиях применения MachineHealthCheck.
По завершению внесения изменений нажмите Сохранить.
Конфигурация группы Worker-узлов
На странице есть возможность добавить новую или изменить параметры конфигурации ранее созданных групп Worker-узлов. Название группы формируется по правилу: название клиентского кластера с добавлением запрашиваемого названия группы. Количество узлов, параметры присоединения узла в группу, сайзинг узлов и machinehealthcheck доступны в конфигурации группы узлов.
ClusterAPI
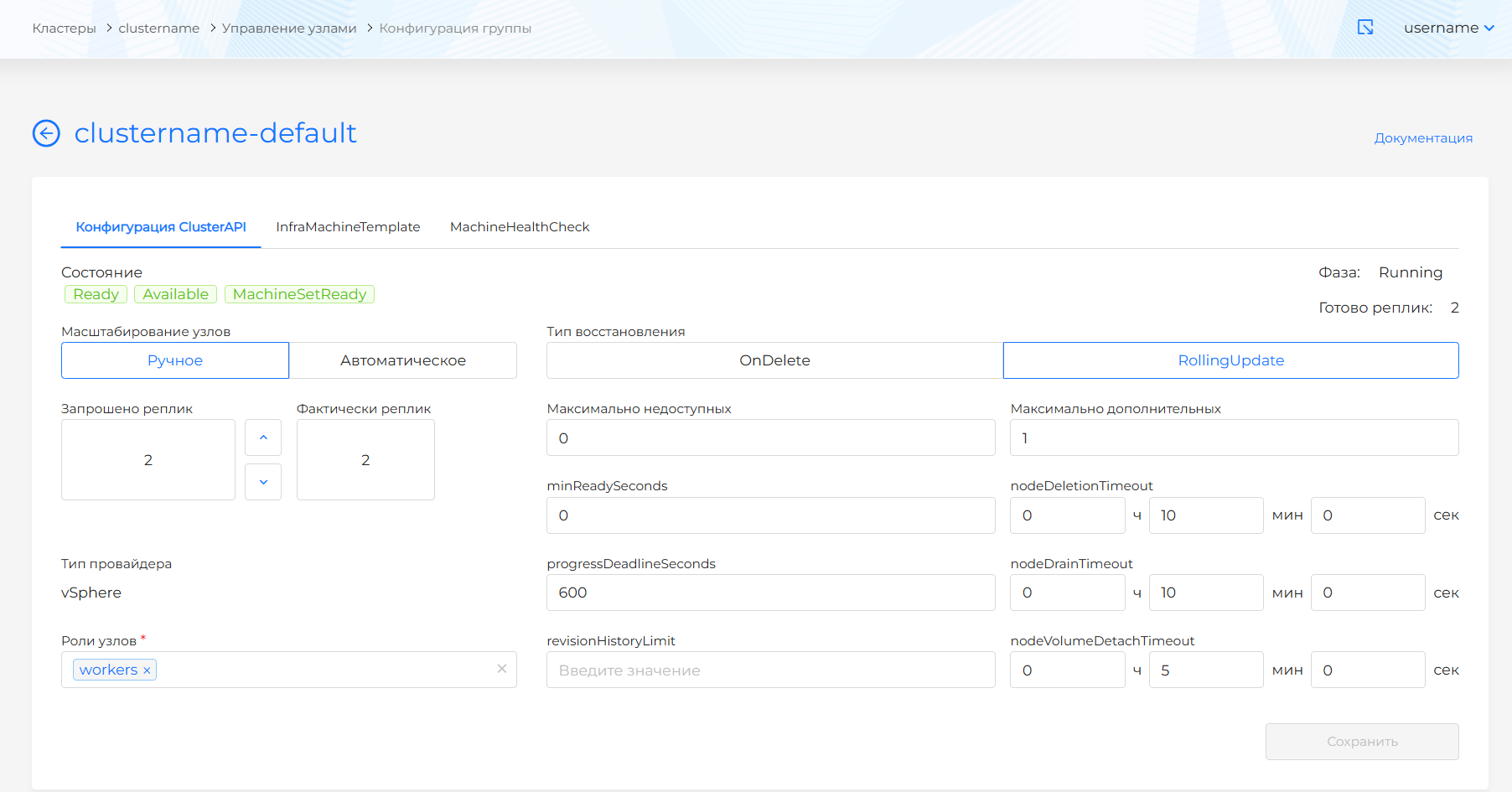
- Выбор способа масштабирования узлов в группе:
- Ручное. При этом доступно директивное указание запрашиваемого количества узлов в группе: в поле “Запрошено реплик” укажите желаемое количество узлов в группе.
Скриншот
- Автоматическое. При этом доступно указание диапазона узлов для группы: укажите минимальное и максимальное количества узлов в группе. Количество узлов будет увеличиваться или уменьшаться в пределах заданного диапазона в зависимости от нагрузки.
Скриншот
При автоматическом масштабировании минимально количество узлов может быть 2. В графическом интерфейсе ограничена возможность задать менее 2-х реплик.
Обратите внимание!
- В случае необходимости выведения конкретного хоста с провайдером Shturval v2 из группы узлов воспользуйтесь инструкцией.
- В случае превышения лимита по количеству Worker-узлов согласно лицензии, на всех страницах графического интерфейса отобразится уведомление с просьбой обратится к вендору для изменения пакета лицензии.
- Тип восстановления:
- OnDelete. При наличии изменений старые узлы удаляются и поднимаются новые.
- RollingUpdate. При наличии изменений новые узлы создаются с последовательной заменой старых. Рекомендуемый вариант. При этом требуется указать максимальное количество недоступных и дополнительных узлов.
- minReadySeconds - минимальное количество секунд, в течение которых узел для созданной машины должен быть готов, прежде чем считать реплику доступной. По умолчанию 0 (машина будет считаться доступной, как только узел будет готов).
- progressDeadlineSeconds - максимальное время в секундах, необходимое для выполнения развертывания, прежде чем оно будет считаться неудавшимся. Контроллер развертывания продолжит обработку неудавшихся развертываний. В состоянии Cluster API будет отображено условие с причиной ProgressDeadlineExceeded. По умолчанию 600 с.
- revisionHistoryLimit - количество MachineSets, которые нужно сохранить для возможности отката. По умолчанию 1.
- nodeDeletionTimeout: определяет, как долго capi-controller-manager будет пытаться удалить узел, после того как ресурс Machine будет помечен на удаление. При значении 0 попытки удаления будут повторяться бесконечно. Если значение не указано, будет использовано значение по умолчанию (10 секунд) для этого свойства ресурса Machine.
- nodeDrainTimeout - это общее количество времени, которое контроллер потратит на слив/освобождение узла. Значение по умолчанию равно 0, что означает, время ожидания освобождения узла не ограниченно по времени и может ожидать сколько угодно. ПРИМЕЧАНИЕ: NodeDrainTimeout отличается от
kubectl drain --timeout. - nodeVolumeDetachTimeout - это общее количество времени, которое контроллер потратит на ожидание отсоединения всех томов (volumes). Значение по умолчанию равно 0, это означает, что тома (volumes) будут ожидать отсоединения без какого-либо ограничения по времени и может ожидать сколько угодно. По умолчанию для ресурса Machine установлено значение 10 секунд.
- роли: укажите через запятую роли, которые будут назначены группе. Каждая назначенная роль будет прописана в после “/” лейбл узла
node-role.kubernetes.io/.
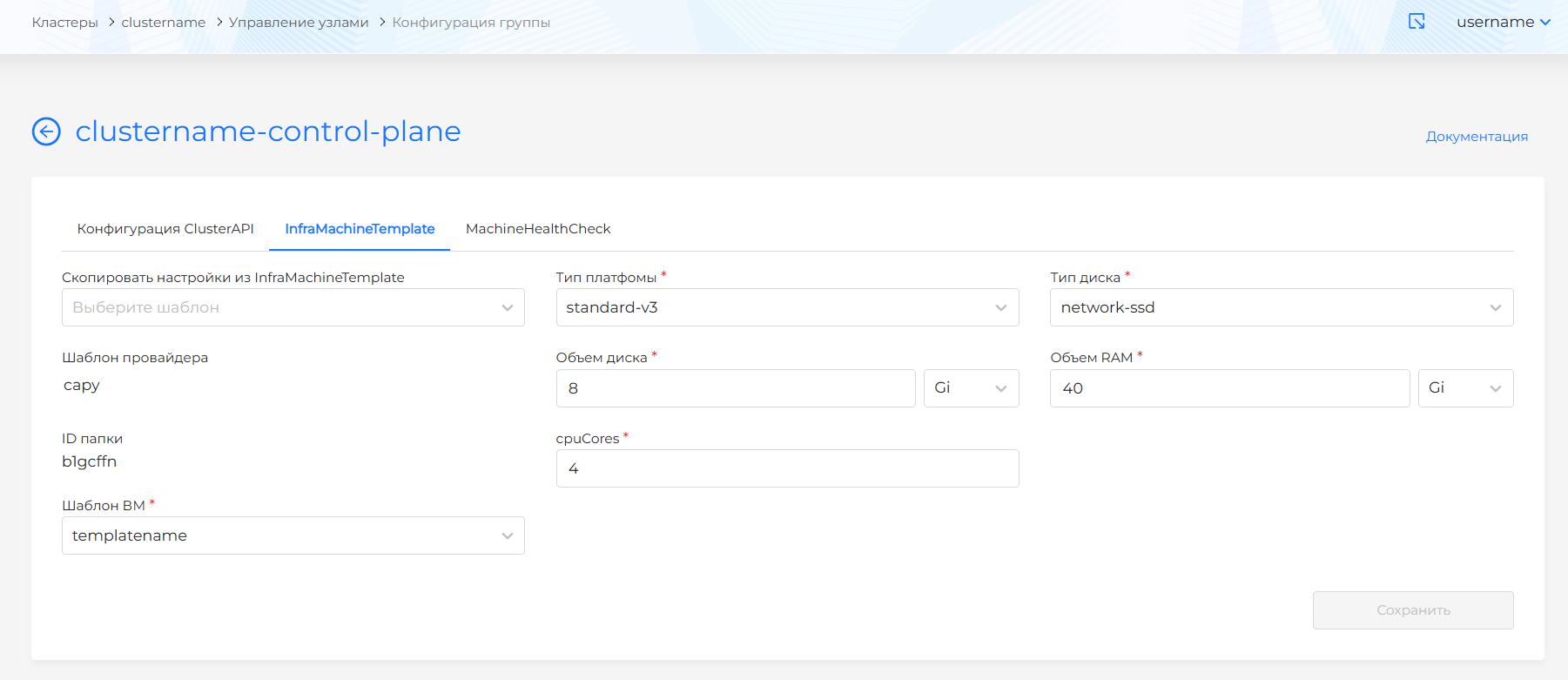
InfraMachineTemplate
На вкладке InfraMachineTemplate есть возможность изменить параметры шаблона инфраструктуры, применив новые значения вручную или скопировав значения из другого существующего шаблона. В зависимости от вида провайдера, происходит редактирование/создание ресурса:
- OVirtMachineTemplate
- VSphereMachineTemplate
- OpenStackMachineTemplate
- BasisMachineTemplate
- ShturvalMachineTemplate
- YandexMachineTemplate
Для OVirtMachineTemplate доступны для конфигурации параметры:
- CPU:
- cores
- sockets
- threads
- Объем RAM, Мб (sizemb)
- Объем диска, Гб (osdisksizegb)
- nics:
- vnicprofile
- Шаблон ВМ (template): доступны шаблоны ВМ экземпляра провайдера, на котором развернут кластер. Рекомендуется использовать шаблоны ВМ с одной операционной системой в рамках одного кластера. В случае использования шаблонов ВМ на разных ОС в рамках одного кластера могут возникать ошибки в процессе обновления кластера. Подробнее о создании шаблона ВМ здесь.
Скриншот
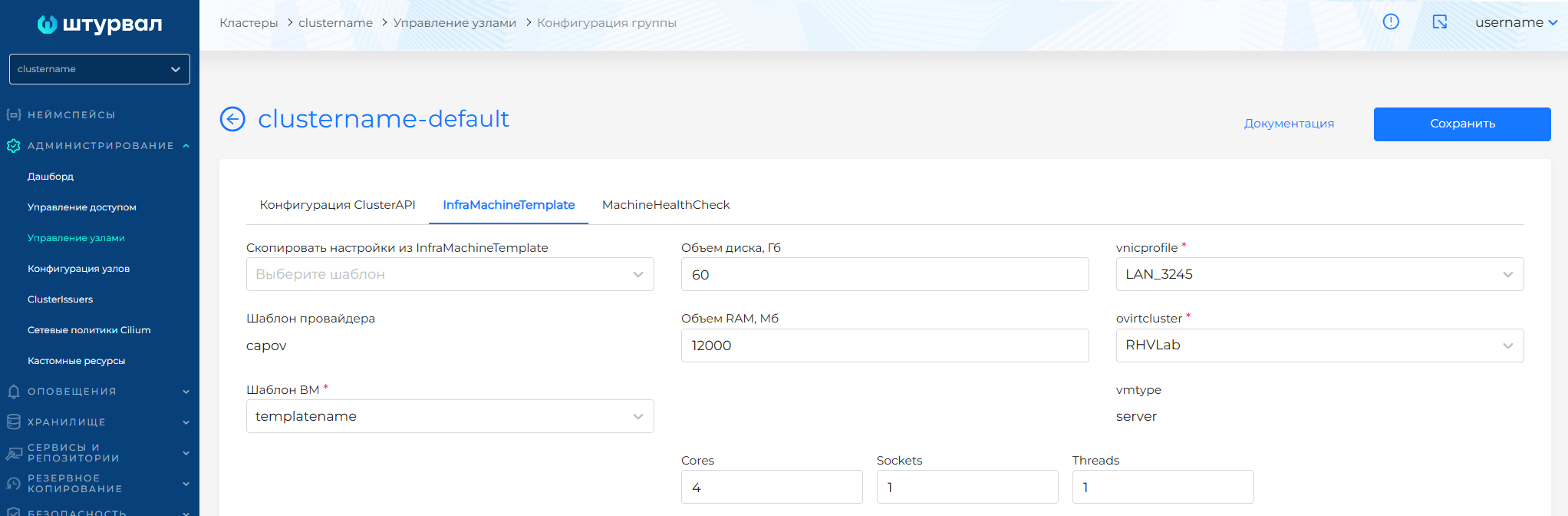
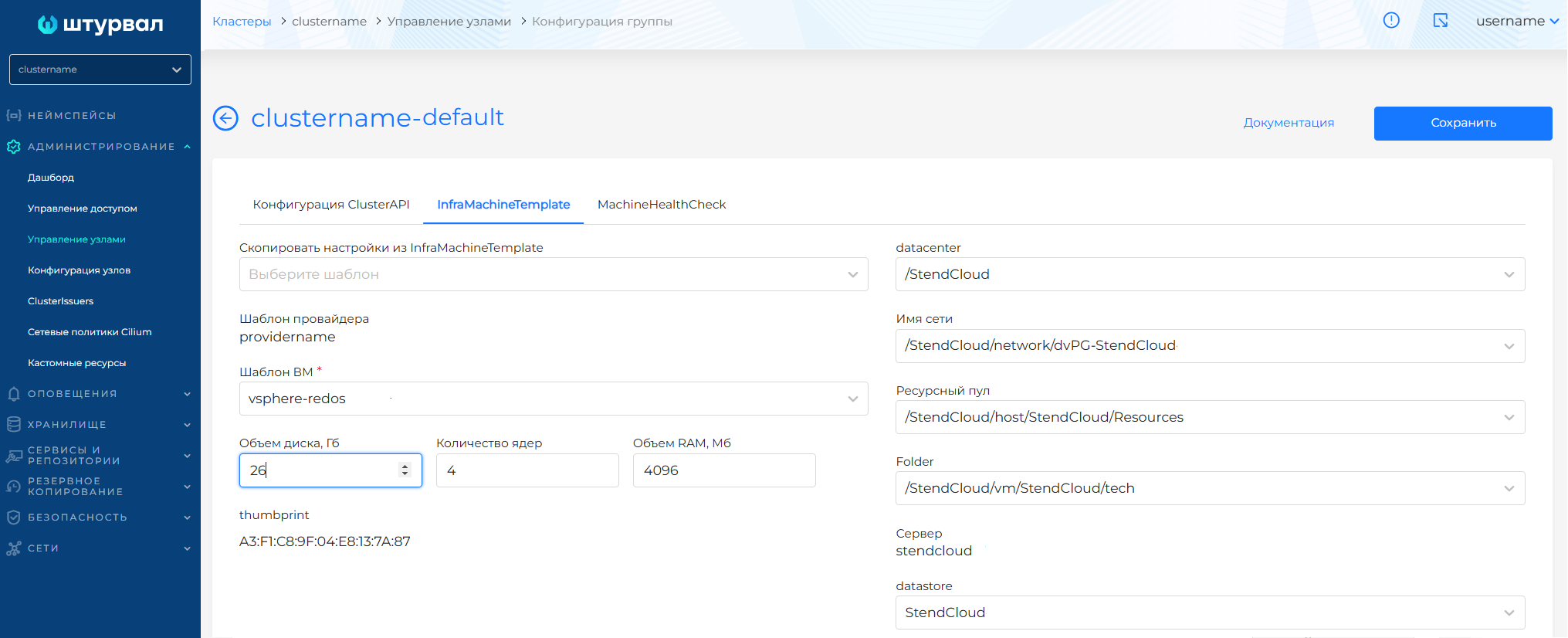
Для VSphereMachineTemplate доступны для конфигурации параметры:
- datacenter (выпадающий список всех датацентров, доступных для сервисной учетной записи экземпляра провайдера)
- datastore (выпадающий список всех датасторов, доступных для сервисной учетной записи экземпляра провайдера)
- Объем диска, Гб (diskGiB)
- Объем RAM, Мб (memoryMiB)
- Folder (путь до места создания ВМ)
- Количество ядер (numCPUs)
- Имя сети (networkName)
- Ресурсный пул (resourcePool)
- Шаблон ВМ (template): доступны шаблоны ВМ экземпляра провайдера, на котором развернут кластер. Рекомендуется использовать шаблоны ВМ с одной операционной системой в рамках одного кластера. В случае использования шаблонов ВМ на разных ОС в рамках одного кластера могут возникать ошибки в процессе обновления кластера. Подробнее о создании шаблона ВМ здесь.
Скриншот
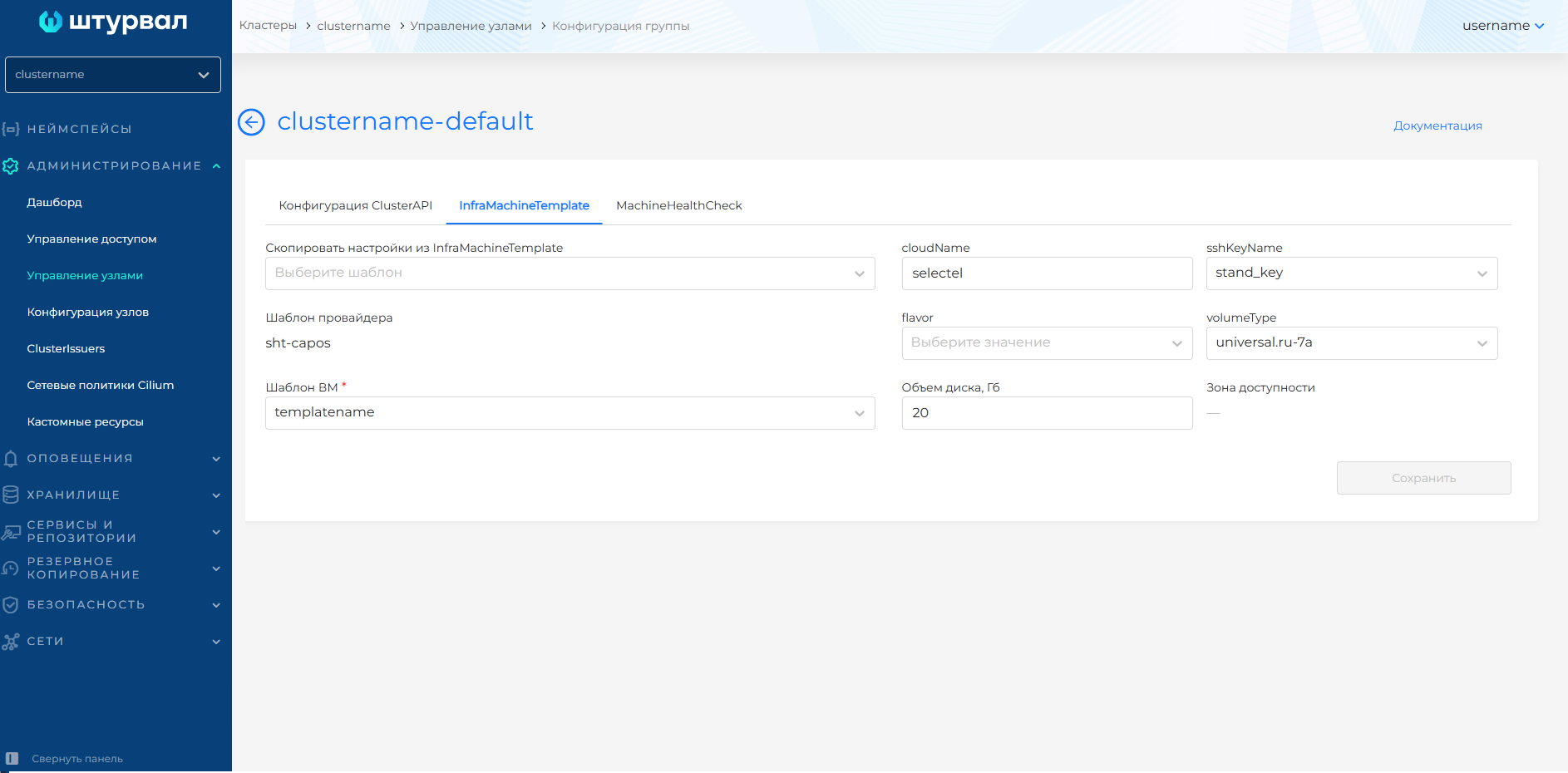
Для OpenStackMachineTemplate доступны для конфигурации параметры:
- cloudName
- flavor (типы ВМ)
- sshKeyName
- volumeType
- Объем диска, Гб
- Шаблон ВМ (template): доступны шаблоны ВМ экземпляра провайдера, на котором развернут кластер. Рекомендуется использовать шаблоны ВМ с одной операционной системой в рамках одного кластера. В случае использования шаблонов ВМ на разных ОС в рамках одного кластера могут возникать ошибки в процессе обновления кластера. Подробнее о создании шаблона ВМ здесь.
Параметр зоны доступности в OpenStackMachineTemplate доступен только для просмотра. Шаблон ВМ содержит зону доступности, если она была задана в конфигурации Worker-узлов на этапе создания кластера.
Скриншот
Для BasisMachineTemplate доступны параметры:
- Количество ядер;
- Объем RAM, Мб;
- Объем диска, Гб;
- Ресурсная группа;
- Имя VINS;
- Имя ExtNet.
Скриншот
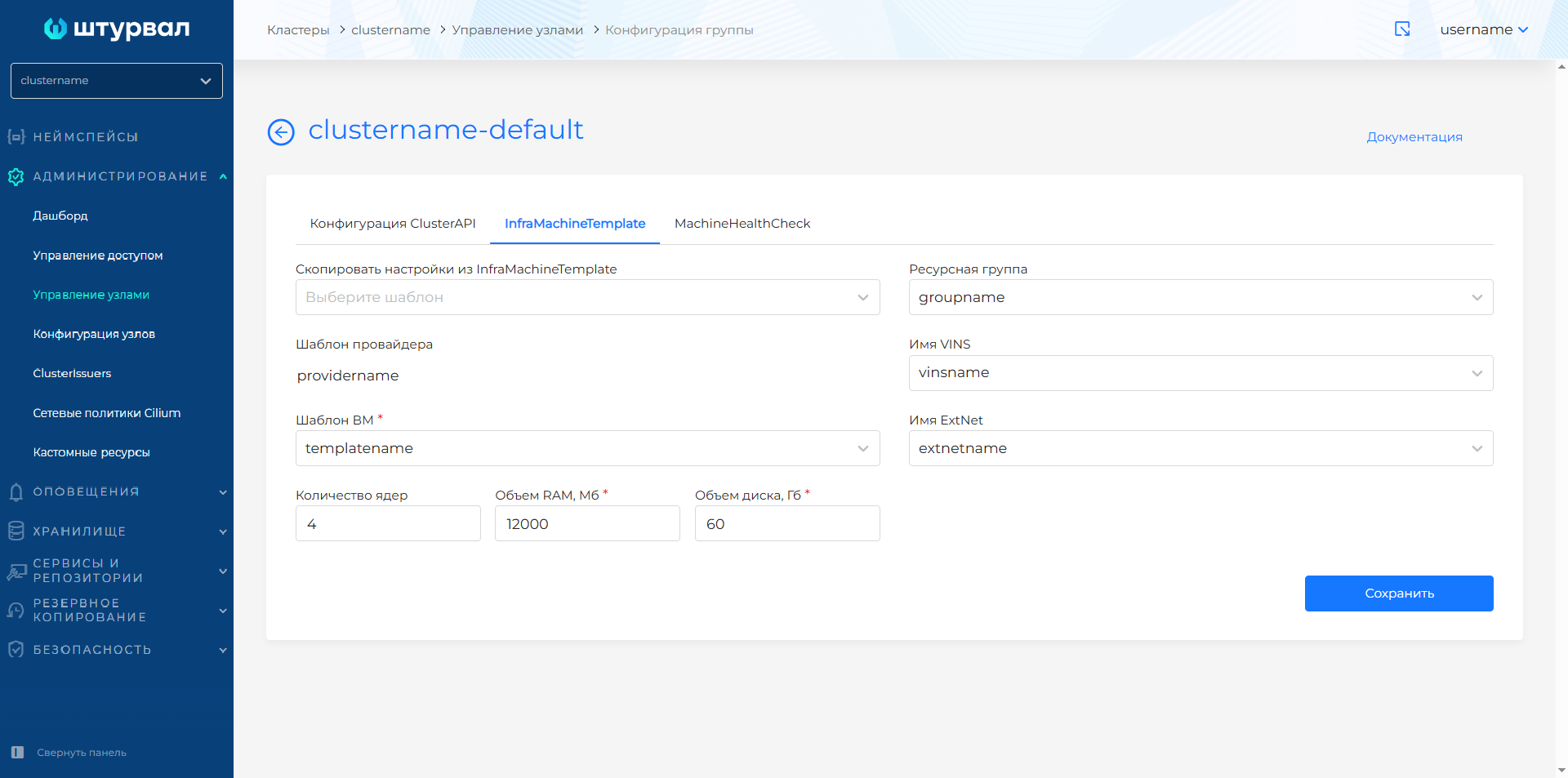
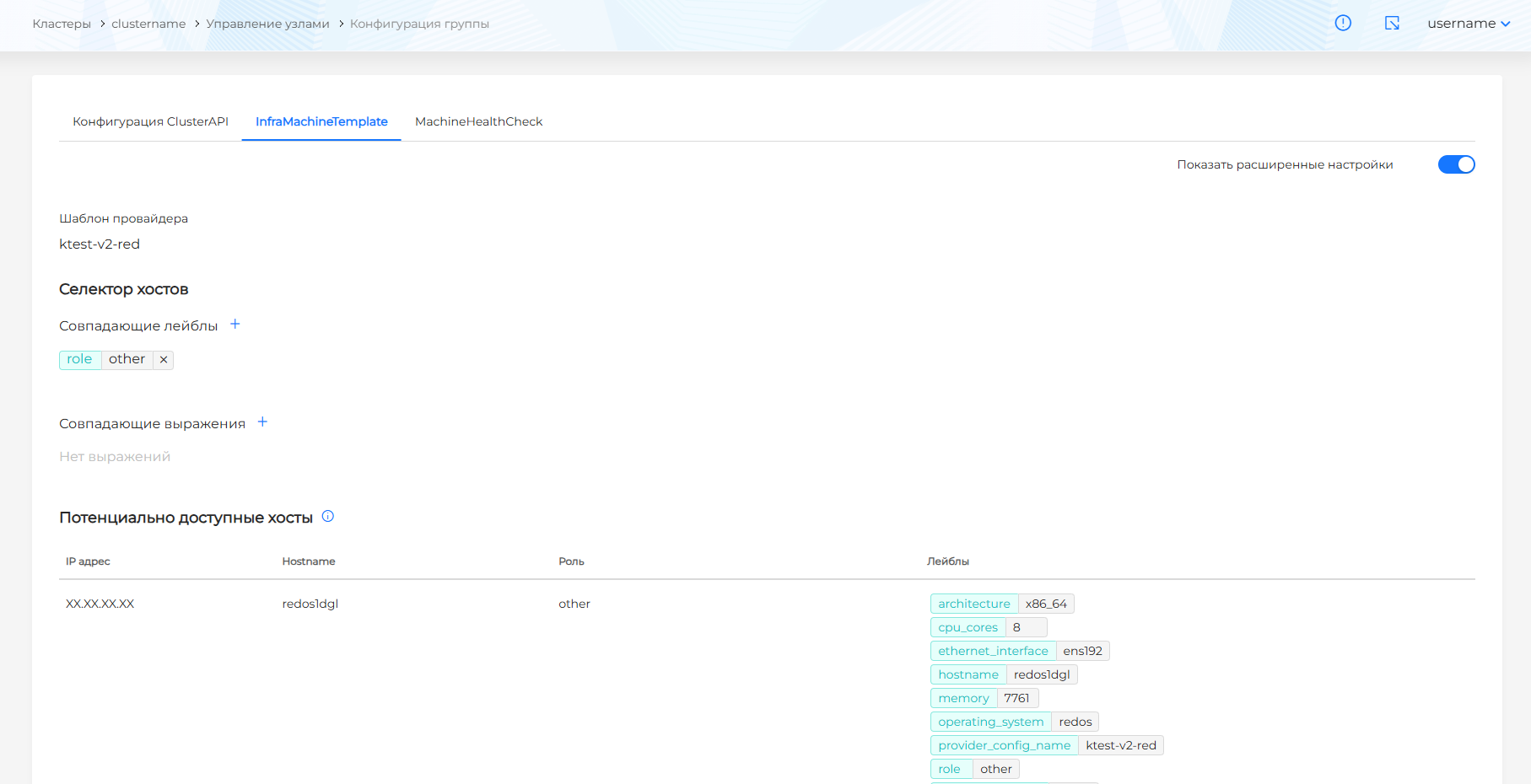
Для ShturvalMachineTemplate доступны параметры конфигурации в базовом режиме и режиме расширенных настроек. По умолчанию включен базовый режим.
В базовом режиме выберите роль хостов, чтобы определить присоединение только хостов с выбранной ролью при масштабировании группы узлов. После выбора роли в блоке Потенциально доступные хосты будут отображены свободные хосты с заданной ролью.
Скриншот
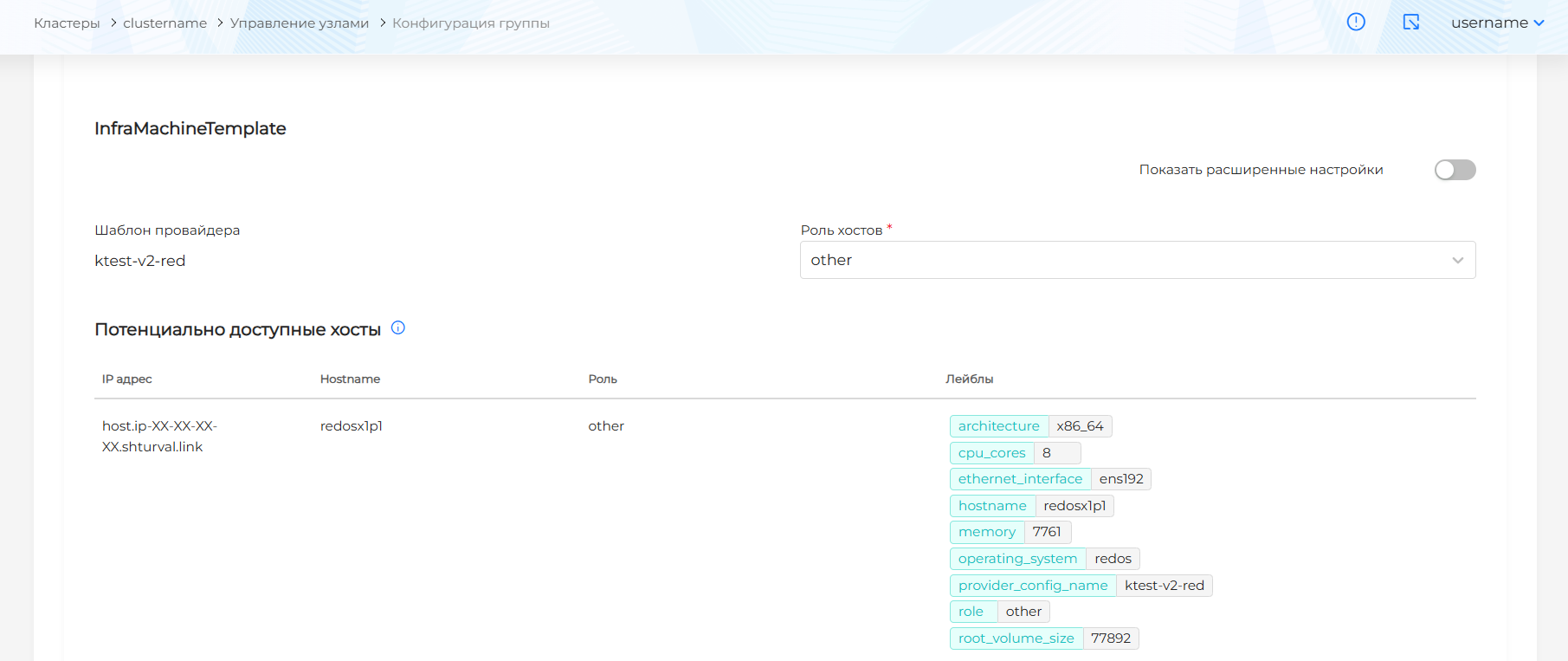
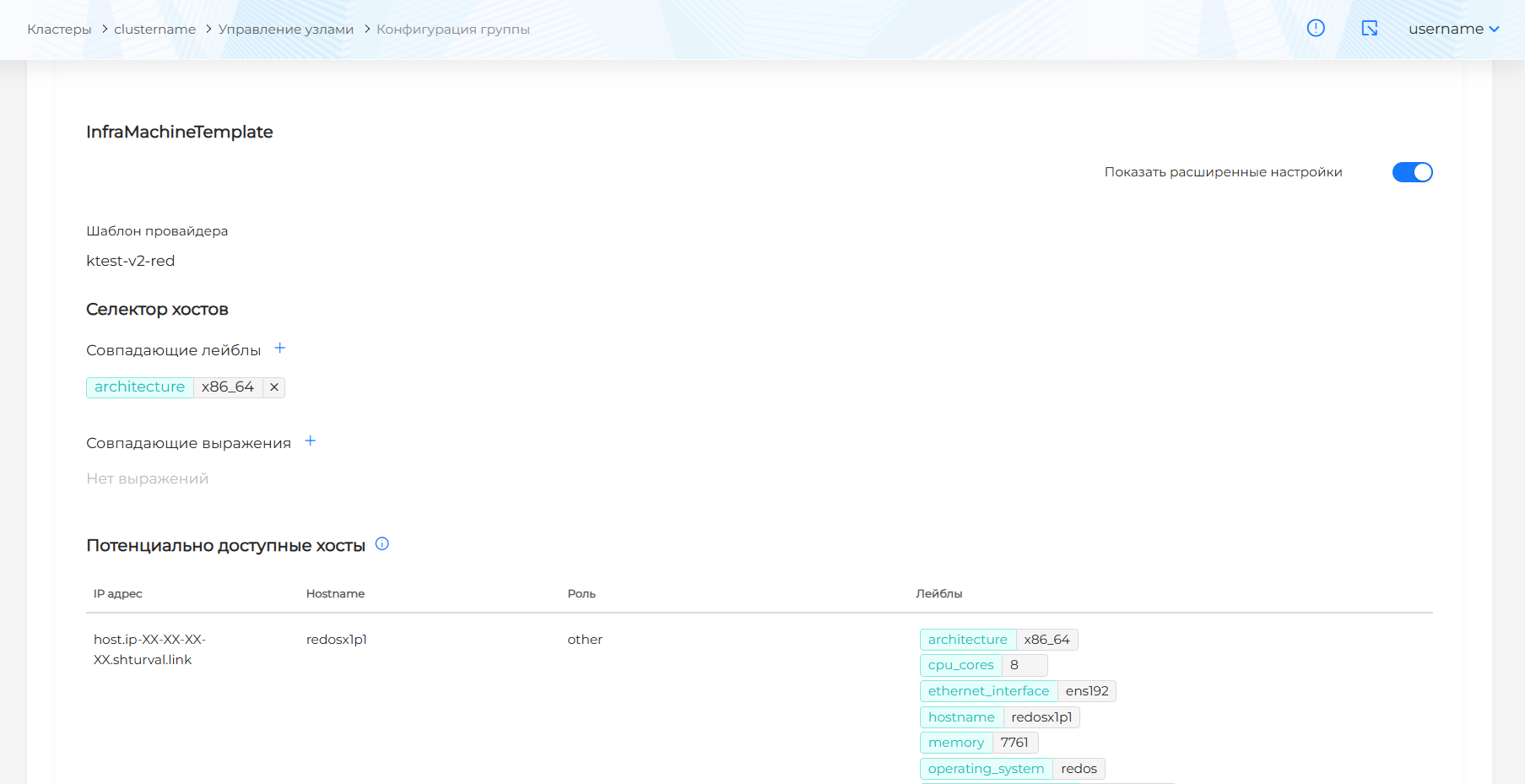
Для включения режима расширенных настроек переведите тумблер Показать расширенные настройки в активное состояние. При переходе из режима расширенных настроек в базовый режим, изменения будут утеряны.
В расширенных настройках вы можете задать совпадающие лейблы и выражения, чтобы определить доступные хосты для присоединения при масштабировании группы узлов:
- при добавлении лейбла хоста в открывшемся окне выберите ключ. Автоматически будет задано значение, соответствующее ключу лейбла существующего хоста в шаблоне провайдера Shturval v2.
- при добавлении лейбла хоста в открывшемся окне выберите ключ и оператора. Доступные операторы:
- In - будут выбраны хосты с совпадающим ключом и значением. Значение будет заполнено автоматически или предложено на выбор в соответствии с указанным ключом лейбла хоста, без возможности изменения;
- NotIn - не выбираются хосты с совпадающим ключом и значением. Значение будет заполнено автоматически или предложено на выбор в соответствии со значением указанного ключа лейбла, без возможности изменения;
- Exists - будут выбраны хосты с совпадающим ключом. Указывать значение не требуется;
- DoesNotExist - не выбираются хосты с совпадающим ключом. Указывать значение не требуется;
При указании нескольких совпадающих выражений, будут отображены доступные хосты, соответствующие всем выражениям.
Скриншот
Обратите внимание!
-
Изменение конфигурации InfraMachineTemplate в ранее созданной группе узлов приведет к пересозданию узлов.
-
Лейблы, указанные в селекторе в качестве совпадающих в одной группе узлов, должны быть указаны в совпадающих выражениях в качестве исключения в других группах по принципу:
-
ключ = выбранный в другой группе ключ лейбла;
-
оператор = NotIn;
-
значение = выбранное в другой группе значение лейбла.
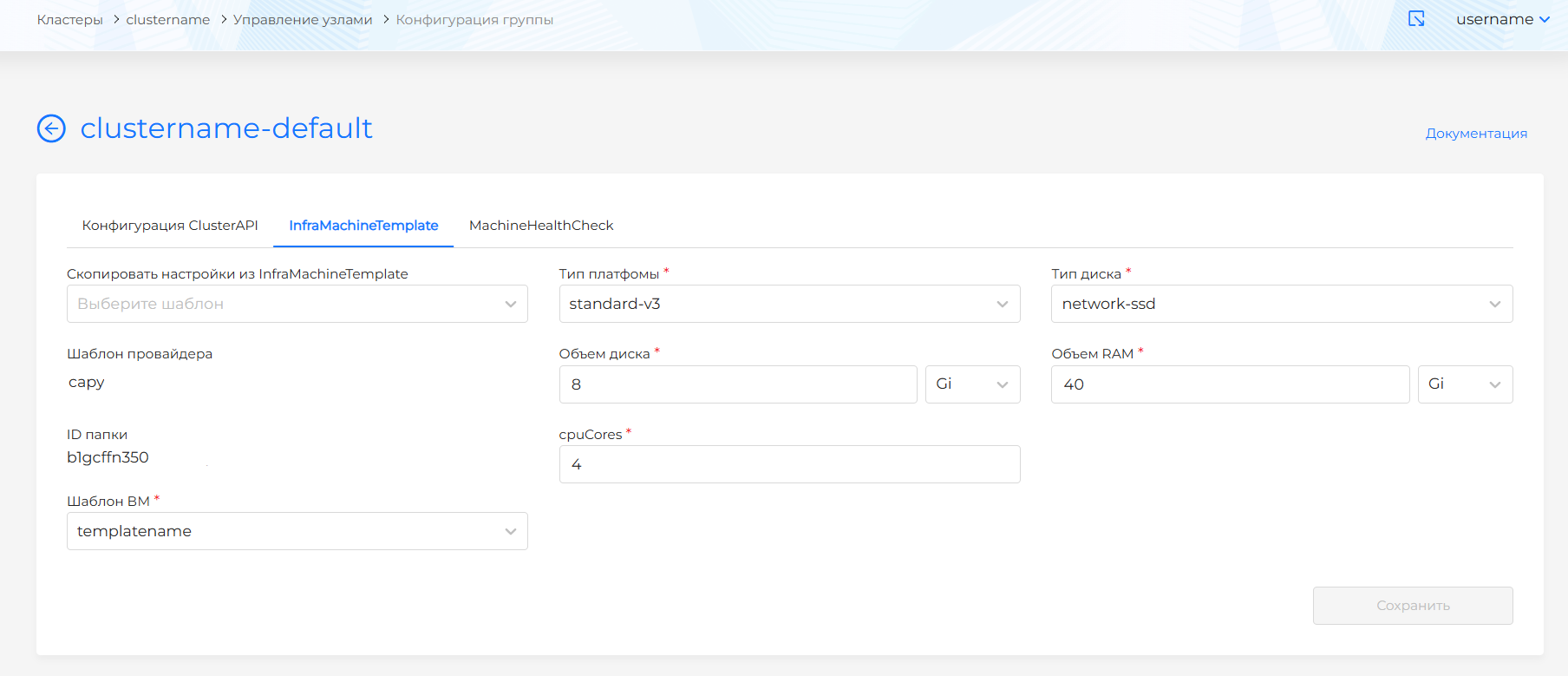
Для YandexMachineTemplate доступны для конфигурации параметры:
- Тип платформы;
- Тип диска;
- Объем RAM. Доступен выбор единицы измерения: Gi, Mi;
- Объем диска. Доступен выбор единицы измерения: Gi, Mi;
- cpuCores;
- Шаблон ВМ (template): доступны шаблоны ВМ экземпляра провайдера, на котором развернут кластер. Подробнее о создании шаблона ВМ здесь.
Скриншот
MachineHealthCheck
Скриншот
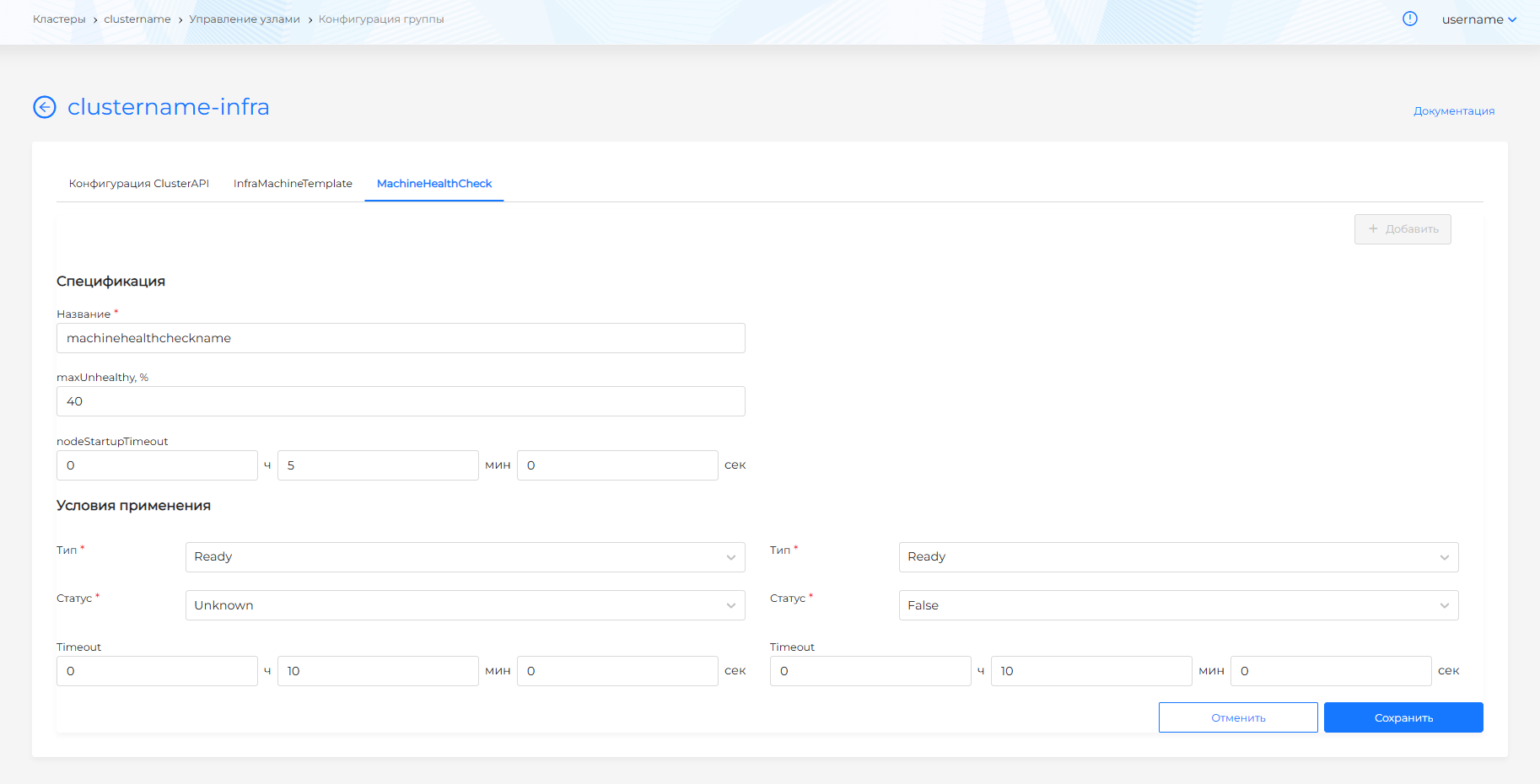
На вкладке MachineHealthCheck можно:
- настроить разные конфигурации MachineHealthCheck для проверки работоспособности машин. При инсталляции клиентского кластера монтируется дефолтная MachineHealthCheck для каждой группы Worker-узлов. Для конфигурации дополнительных MachineHealthChecks, нажмите + Добавить. Когда создано несколько конфигураций, на вкладке отображается список MachineHealthChecks.
- перейти к просмотру и редактированию конфигурации MachineHealthCheck.
Чтобы настроить конфигурацию MachineHealthCheck:
- задайте название MachineHealthCheck. После сохранения название нельзя изменить.
- можно задать maxUnhealthy в %. Параметр определяет максимальный процент нездоровых узлов в группе.
Обратите внимание! MachineHealthCheck не будет восстанавливать узлы, если количество нездоровых Worker-узлов в группе больше, чем задано в maxUnhealthy.
Примеры
1. Значение maxUnhealthy - 90%:
В группе 2 Worker-узла, где 1 узел нездоров. Следовательно, количество нездоровых узлов = 50%, что меньше установленного значения *maxUnhealthy*. В этом случае узел будет восстановлен.
2. Значение maxUnhealthy - 40%:
В группе 2 Worker-узла, где 1 узел нездоров. Следовательно, количество нездоровых узлов = 50%, что больше установленного значения *maxUnhealthy*. В этом случае узел не будет восстановлен.
- можно задать nodeStartupTimeout время ожидания присоединения узла к кластеру. Слишком маленькое значение может привести к тому, что виртуальной машине не хватит времени для создания и присоединения, попытки присоединить узел уйдут в цикл.
Пример
Значение nodeStartupTimeout - 10 мин:
В этом случае, прежде чем считать узел нездоровым, должно пройти 10 минут.
Ожидается, что этого времени достаточно для присоединения узла к кластеру.
- в блоке Условия применения (unhealthyConditions) настройте параметры проверки узлов, при соблюдении которых узел будет считаться нездоровым:
- выберите Тип состояния узла. Доступные типы: NetworkUnavailable, DiskPressure, MemoryPressure, PIDPressure, Ready.
- выберите Статус состояния узла: True, False, Unknown.
- задайте Timeout - время ожидания, по истечению которого статус узла будет считаться действительным. Рекомендуется не устанавливать слишком короткий период Timeout, чтобы не происходило ложного перезапуска, пока узел переходит в исправное состояние. Длительный период Timeout может привести к простоям рабочей нагрузки на неработоспособном узле.
Пример
Условия применения:
Тип - Ready
Статус - Unknown
Timeout - 5 мин
Тип - Ready
Статус - False
Timeout - 5 мин
MachineHealthCheck сработает, если при проверке выявлено, что по истечении 5 минут наступит хотя бы одно из условий:
- узел находится в состоянии Ready-Unknown;
- узел в состоянии Ready-False.
После создания MachineHealthCheck будет добавлен в список проверок на вкладке MachineHealthCheck.
Чтобы перейти к просмотру и редактированию, нажмите на строчку с названием MachineHealthCheck. В открывшемся окне можно изменить параметры maxUnhealthy, nodeStartupTimeout и Timeout в условиях применения MachineHealthCheck.
По завершению внесения изменений нажмите Сохранить.
Узел
Переход на страницу узла доступен по нажатию на имя узла в списке узлов на странице “Управление узлами”.
Вкладка Узел
Скриншот
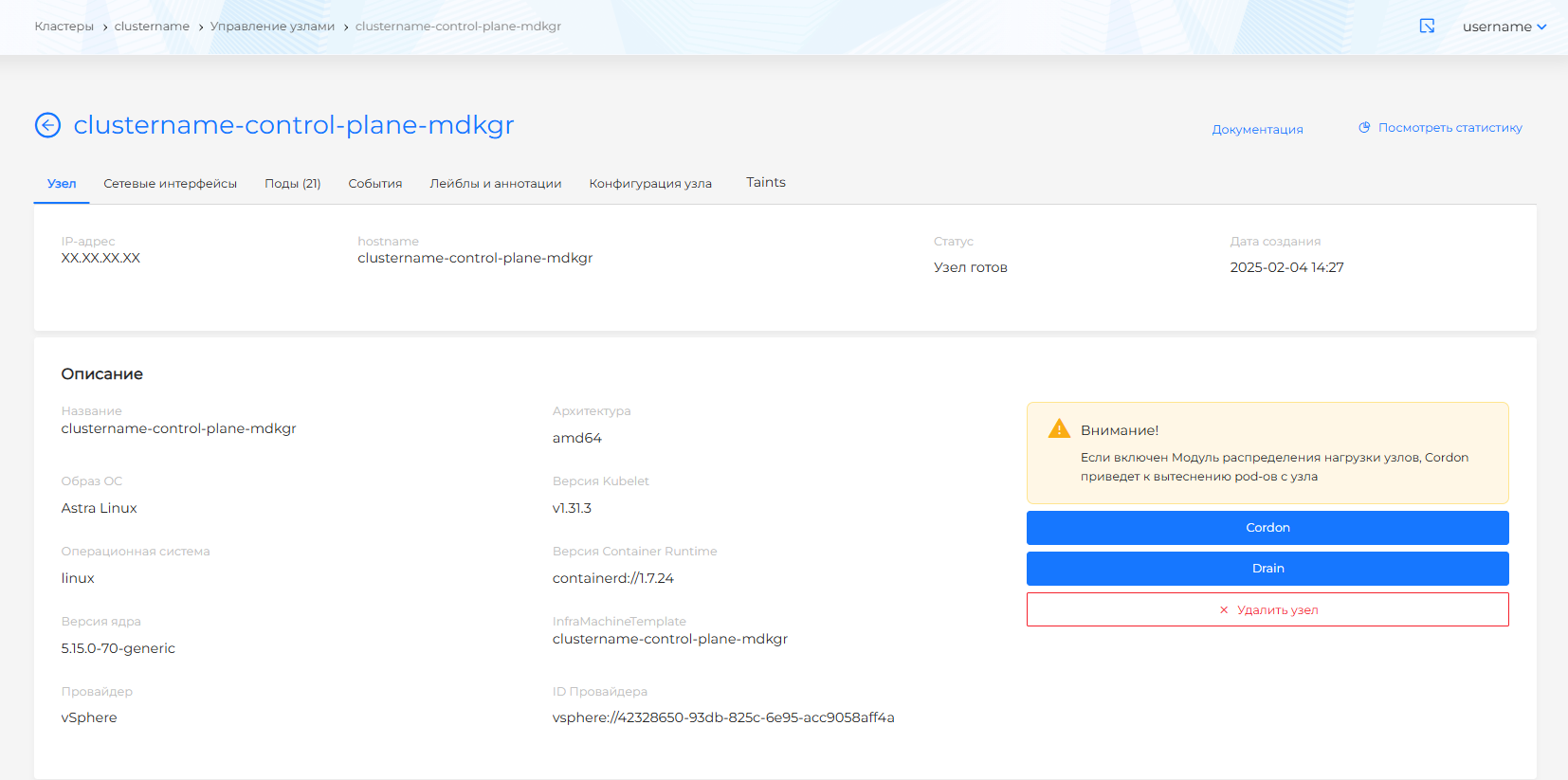
На вкладке доступно описание узла, состояние ClusterAPI, инфраструктуры и самого узла. Страница доступна для просмотра с момента запроса на добавление узла и позволяет отследить этапы создания узла.
Скриншот

Когда узел будет доступен, на странице отобразятся вычислительные ресурсы. Если в клиентском кластере и кластере управления установлен и включен модуль графического отображения метрик, будет доступна кнопка для перехода на дашборд Grafana.
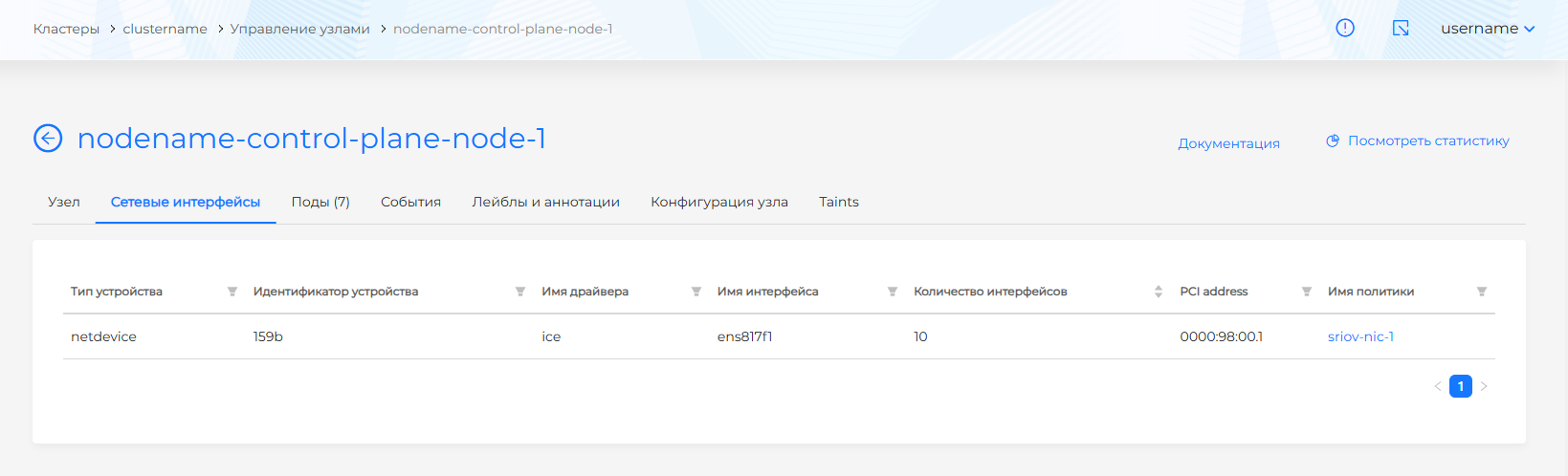
Если в кластере настроен SR-IOV Network Operator и созданы виртуальные машины, то на вкладке Сетевые интерфейсы будет доступна информация:
- Тип устройства (доступна фильтрация);
- Идентификатор устройства (доступна фильтрация);
- Имя драйвера (доступна фильтрация);
- Имя интерфейса (доступна фильтрация);
- Количество интерфейсов (доступна сортировка);
- PCI address (доступна фильтрация);
- Имя политики (доступна фильтрация). Нажатие на имя политики открывает страницу просмотра Sriov Network Policy.
Скриншот
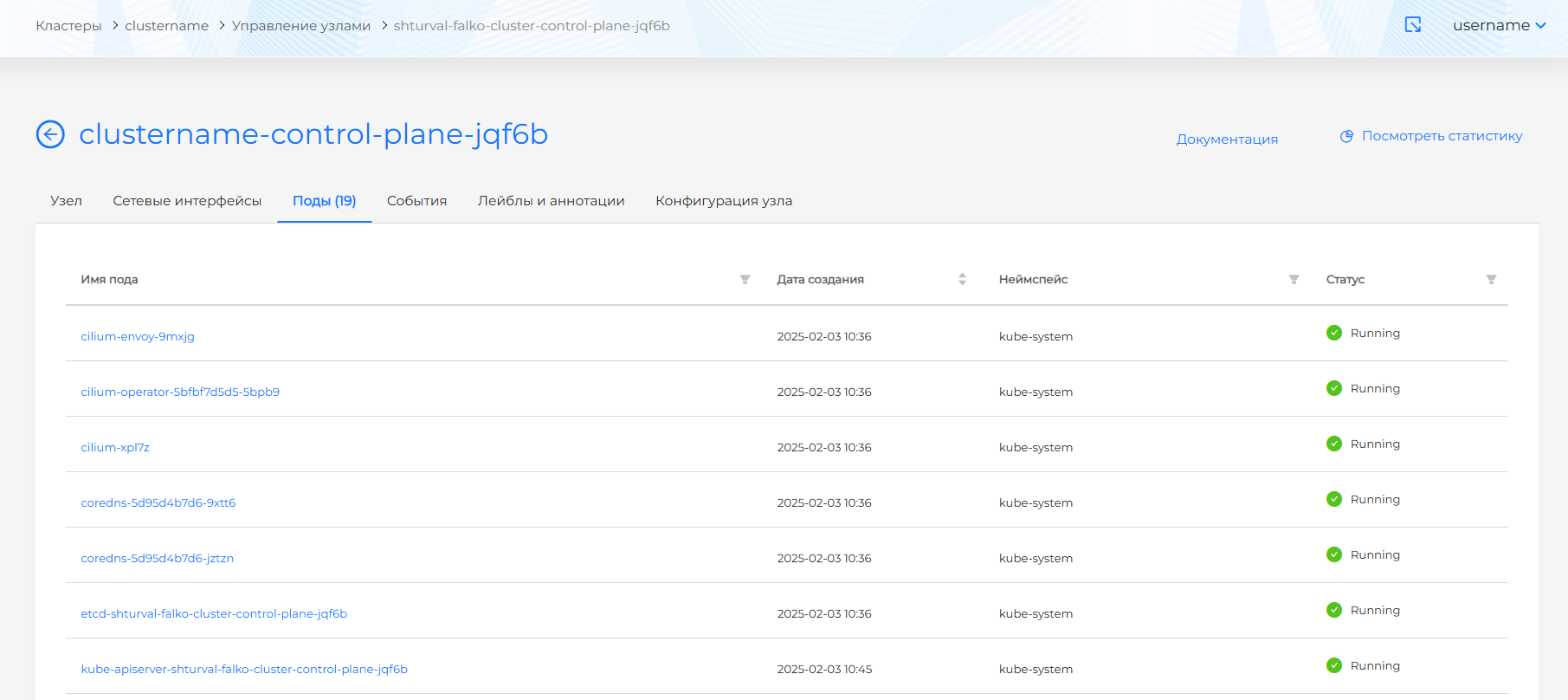
Вкладка Поды
Вкладка Поды представляет собой таблицу со списком подов выбранного узла, содержащую колонки:
- Имя пода (доступна фильтрация). Нажатие на имя открывает страницу просмотра пода.
- Дата создания (доступна сортировка).
- Неймспейс (доступна фильтрация). Вы можете ввести значение для фильтрации подов по неймспейсам. Для отмены фильтрации по неймспейсам, в фильтре нажмите Отменить и далее Применить.
- Статус (доступна фильтрация). Возможные значения для выбора в фильтре: Running, Pending, Terminating, CrashLoopBackOff, Completed, Failed, Unknown.
На вкладке Поды можно отследить перераспределение подов при Drain узла.
Скриншот
Вкладка События
На вкладке События отображаются стандартные события Kubernetes для ClusterAPI, инфраструктуры и самого узла. На вкладке отображается индикация количества событий.
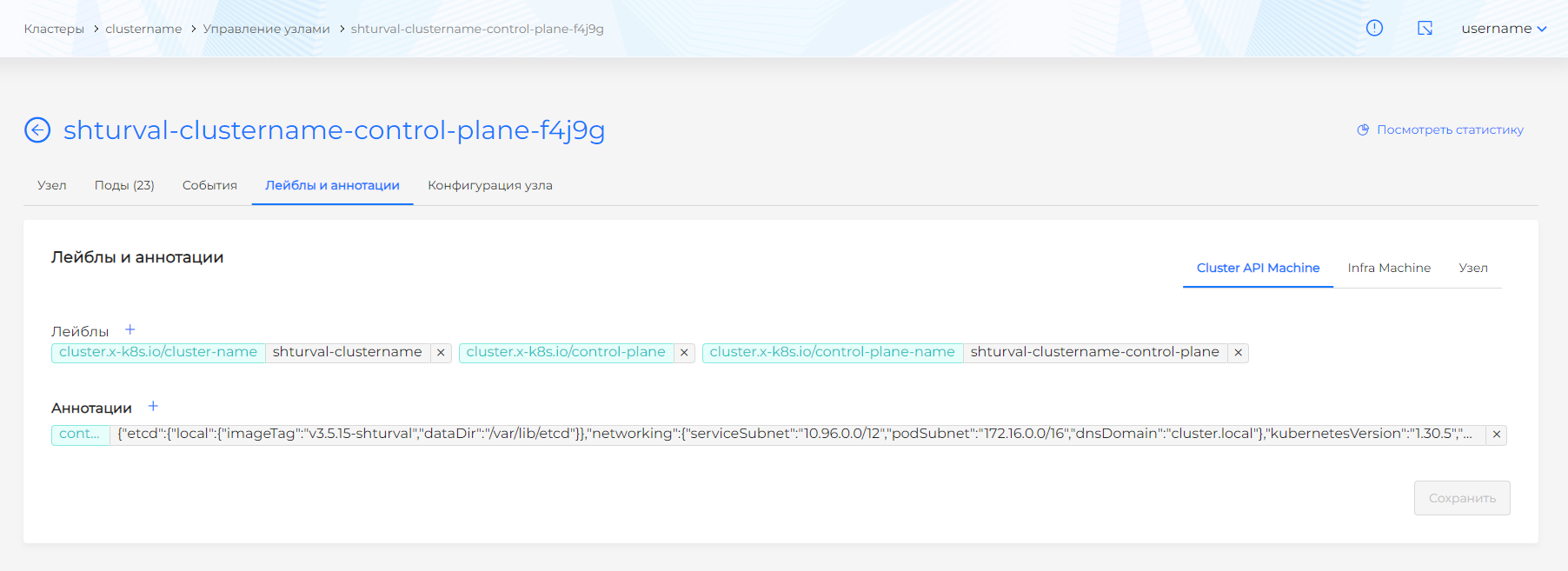
Вкладка Лейблы и аннотации
На вкладке Лейблы и аннотации при необходимости можно присвоить лейблы и аннотации для ClusterAPI, инфраструктуры и самого узла.
Скриншот
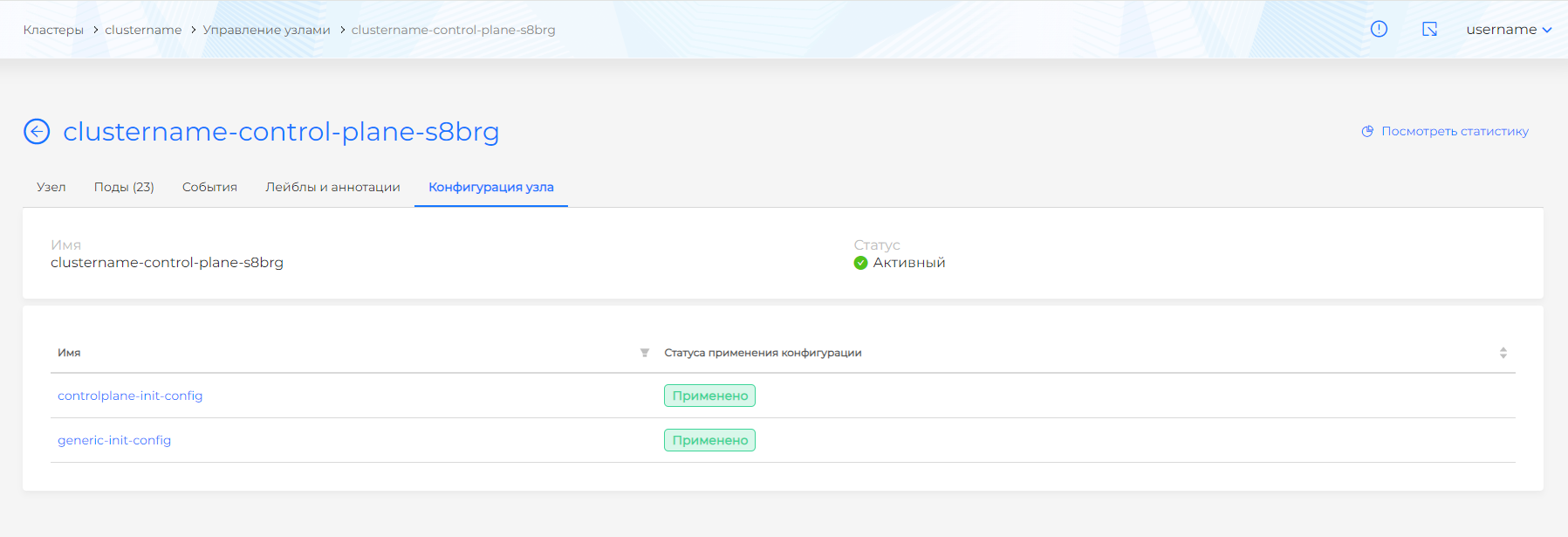
Вкладка Конфигурация узла
Вкладка Конфигурация узла отображает информацию ресурса Node Config и содержит перечень конфигураций узла (Node Config Item (NCI)) кластера, запланированных к применению на узле. В случае возникновения ошибки применения NCI на узле, статус примет значение Не применено. Также, на вкладке доступна информация о статусе перезагрузки узла, когда:
- требуется перезагрузка (reboot required);
- перезагрузка запланирована (reboot scheduler);
- перезагрузка разрешена (reboot allowed).
Скриншот
Для просмотра настроек конфигурации NCI нажмите на название NCI в перечне.
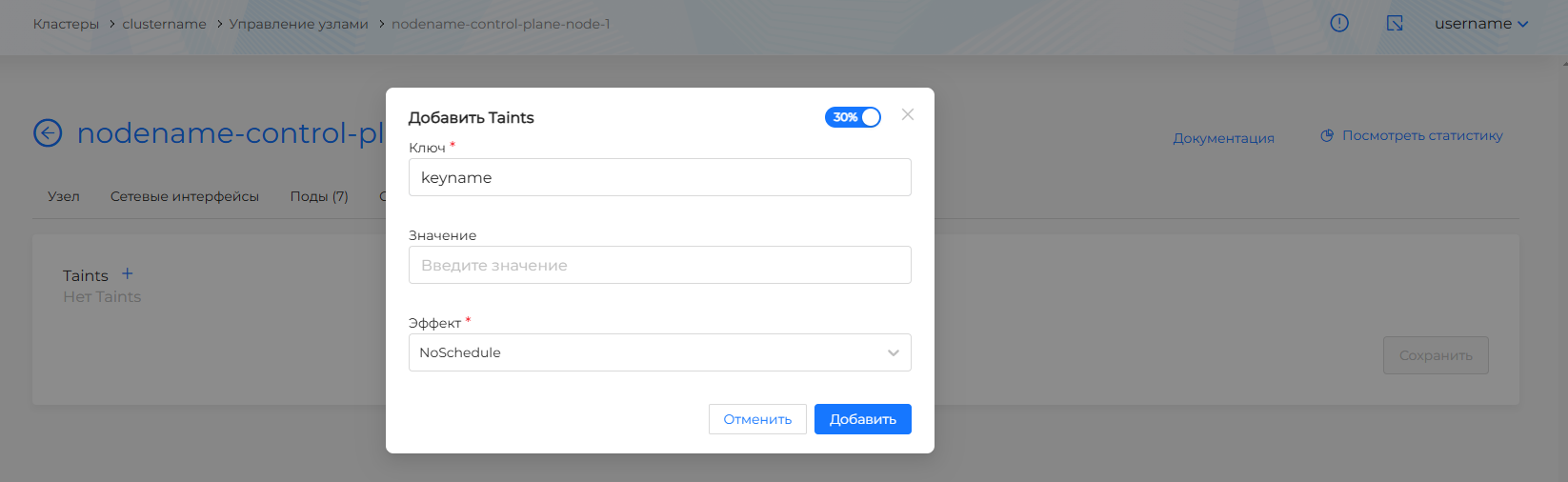
На вкладке Taints отображается перечень Taints (ограничения), запрещающих размещения подов на узле. При необходимости можно присвоить новый Taint узлу, изменить или удалить существующий.
Чтобы добавить Taint нажмите на + и в открывшемся окне требуется:
- задать ключ для Taint (key);
- при необходимости указать значение (value);
- выбрать Эффект для ограничения размещения подов на узле (effect). Чтобы ни один под не был запланирован на узле без соответствующего Toleration (разрешения), выберите NoSchedule. Если не требуется строгое ограничение для размещения подов без соответствующего Toleration (разрешения), выберите PreferNoSchedule. При необходимости вытеснения уже запущенных подов на узле, выберите NoExecute, в этом случае:
- Поды без соответствующего Toleration немедленно вытесняются.
- Поды с соответствующим Toleration остаются на узле навсегда.
- Поды с соответствующим Toleration и заданным периодом разрешения (tolerationSeconds) остаются на узле в течении указанного времени, после чего вытесняются.
Скриншот
Когда необходимо разместить под на узле с Taints, задайте поду Toleration (разрешение), соответствующее конфигурации Taint.
Пример
# Заданный Taint на узле
spec:
taints:
- effect: NoSchedule
key: key1
value: value1
# Toleration для размещения пода на узле с Taint
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
Обратите внимание! Когда узел имеет несколько Taints (ограничений), для размещения пода на узле необходимо задать Toleration, соответствующие каждому Taint.
Действия с узлами
Cordon
На странице узла доступны кнопка Cordon. При нажатии на кнопку Cordon:
Скриншот
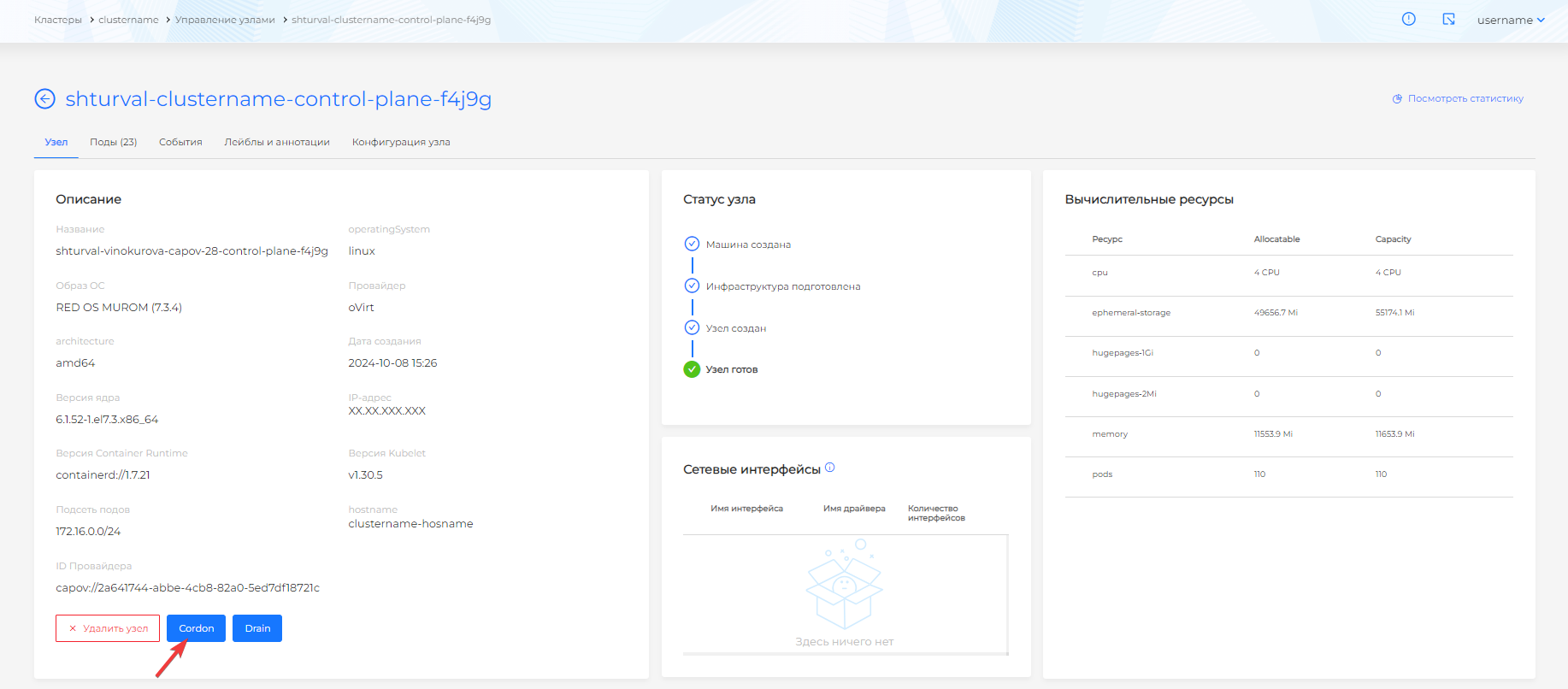
- узел блокируется для распределения новых подов;
- работа существующих на узле подов не прерывается;
- узел, заблокированный для распределения новых подов помечается в колонке “Scheduling” таблице узлов на странице “Управление узлами” признаком “Disabled”;
- название кнопки подменяется на Uncordon, отменяющую действие.
Скриншот
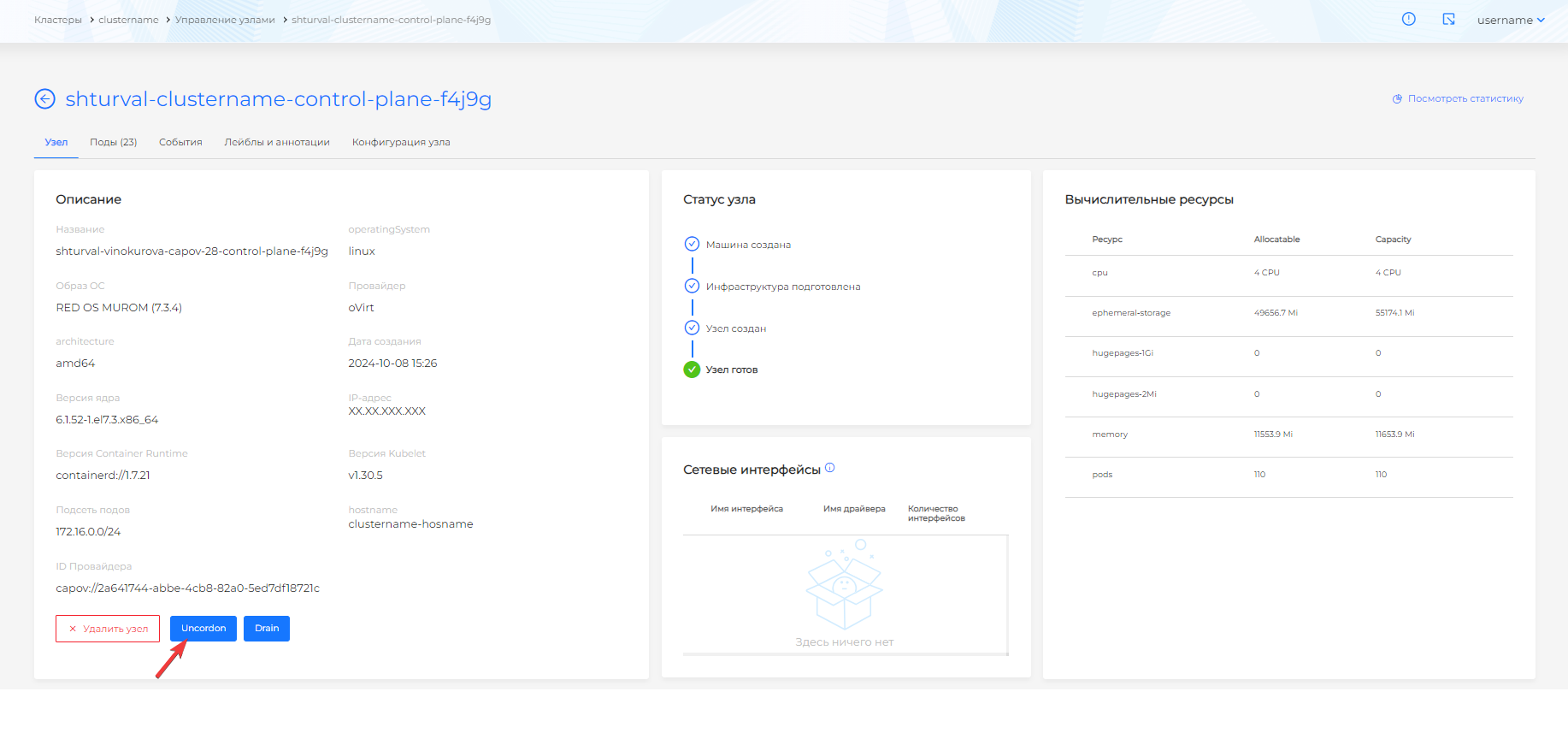
После нажатия на кнопку Uncordon признак снимается с узла и не отображается в таблице.
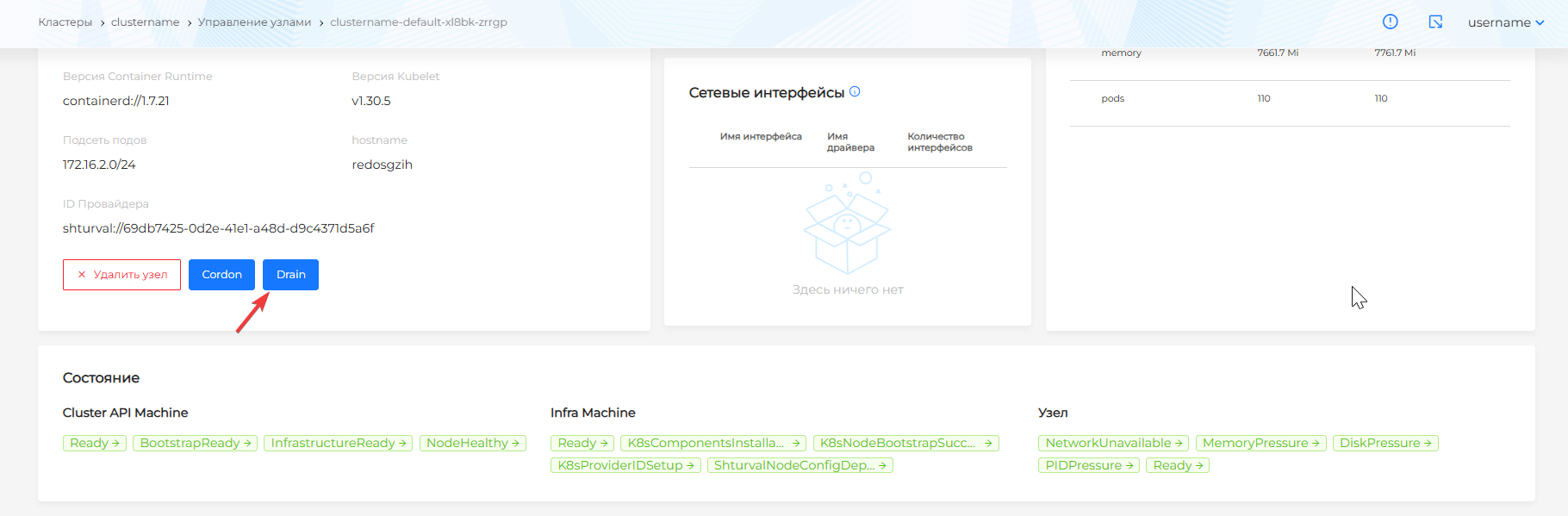
Drain
На странице узла доступны кнопка Drain. Нажатие на Drain открывает модальное окно с доступными настройками Drain узла. По умолчанию все настройки отключены. Чтобы запустить Drain узла с дефолтными настройками, в окне настроек Drain узла нажмите Запустить Drain.
Скриншот
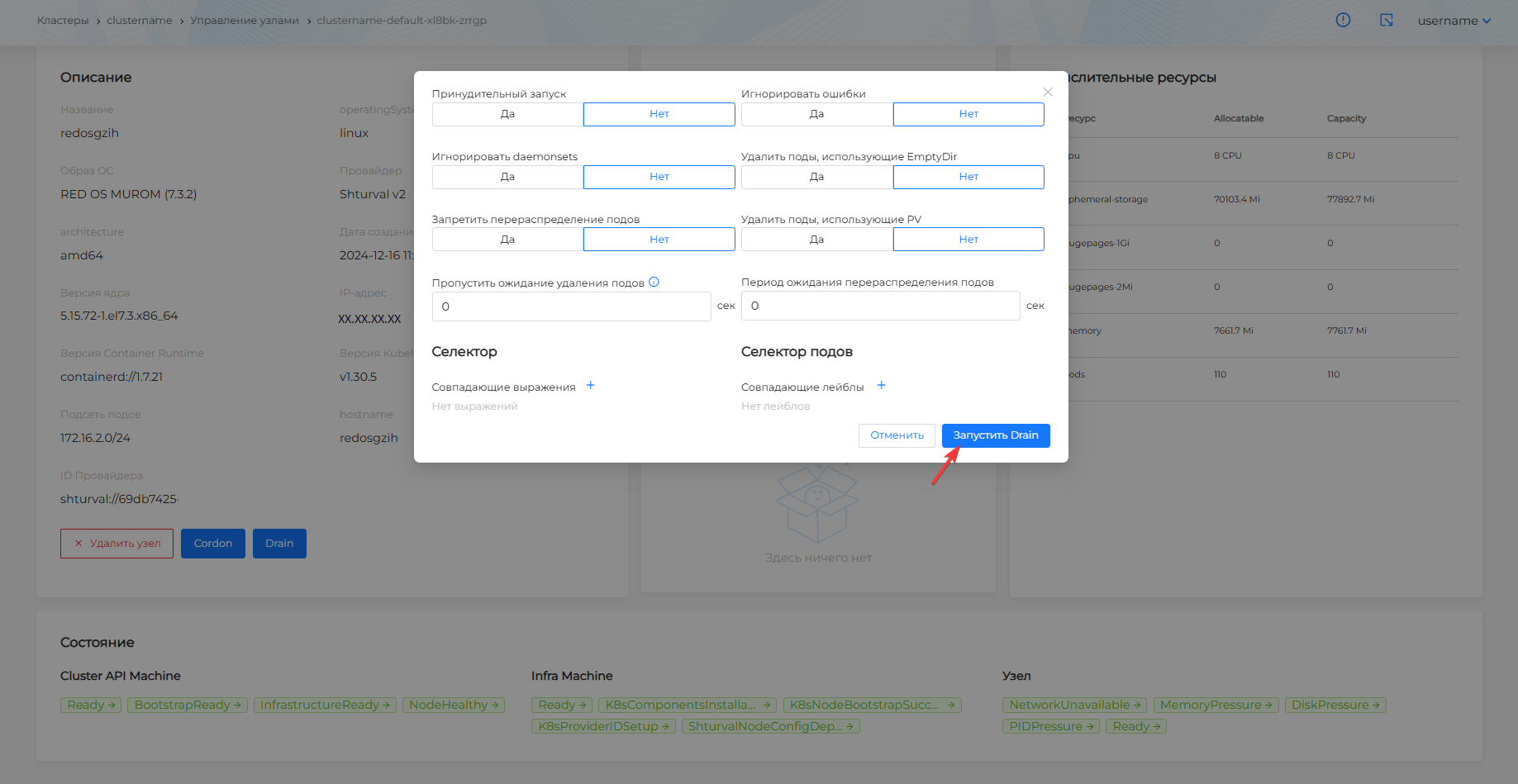
При необходимости возможно задать следующие настройки Drain узла:
- Принудительный запуск Drain узла. Приведет к немедленному завершению подов, игнорируя любые ошибки и предупреждения. Обратите внимание! При принудительном запуске могут быть потеряны данные.
- Игнорировать daemonsets. Чтобы было проигнорировано завершение и перераспределение подов, подчиненных Daemonsets, выберите “Да”.
- Запретить перераспределение подов. При включении запрета поды не будут перераспределены, ресурс контролируемого завершения работы подов (Eviction) не будет запущен, настройки PodDisruptionBudget и terminationGracePeriodSeconds будут проигнорированы.
- Пропустить ожидание удаления подов. Задайте время в секундах, необходимое для ожидания удаления подов. Если период времени после установки DeletionTimestamp превысит заданное время, ожидание удаления будет пропущено. Значение 0 отключает настройку пропуска ожидания.
- Игнорировать ошибки. При включении настройки будут проигнорированы ошибки, возникающие между узлами в группе.
- Удалять ли поды, использующие EmptyDir. В случае удаления подов, данные EmptyDir также будут удалены.
- Удалять ли поды, использующие PV. В случае удаления подов, данные PV также будут удалены.
- Период ожидания перераспределения подов. По истечению периода ожидания перераспределения подов Drain узла завершится. Значение 0 не ограничивает время ожидания перераспределения подов.
- Селектор. Для определения скоупа применения настроек Drain узла можно задать совпадающие выражения. Нажмите +, укажите ключ, выберите операцию сравнения (= и == соответствуют “равенству”,!= соответствует “неравенству”), укажите значение ключа.
- Селектор подов. Вы можете добавить лейблы подов, к которым необходимо применить настройки Drain узла. Нажмите на +, задайте ключ, при необходимости значение.
Скриншот
При запуске Drain:
- узел блокируется для распределения новых подов узла (получает признак “Cordoned”);
- поды принудительно завершаются и перераспределяются на другие узлы. Все поды кроме жизненно важных принудительно завершаются и будут перераспределены на другие узлы кластера (если такие узлы есть);
- узел, заблокированный для распределения подов помечается в колонке “Scheduling” таблице узлов на странице “Управление узлами” признаком “Disabled”.
- кнопка Cordon подменяется на Uncordon.
Отследить ход Drain узла можно на вкладке Поды узла.
Скриншот
После нажатия на кнопку “Uncordon” признак снимается с узла и не отображается в таблице.
Чтобы защитить узлы от автоматического перезапуска во время изменения конфигурации или обновления используйте инструкцию.
Удаление узла
Для удаления узла на странице Worker-узла нажмите на кнопку Удалить узел. В открывшемся окне необходимо выбрать, требуется удалить узел с последующим пересозданием или удалить узел без пересоздания.
Скриншот
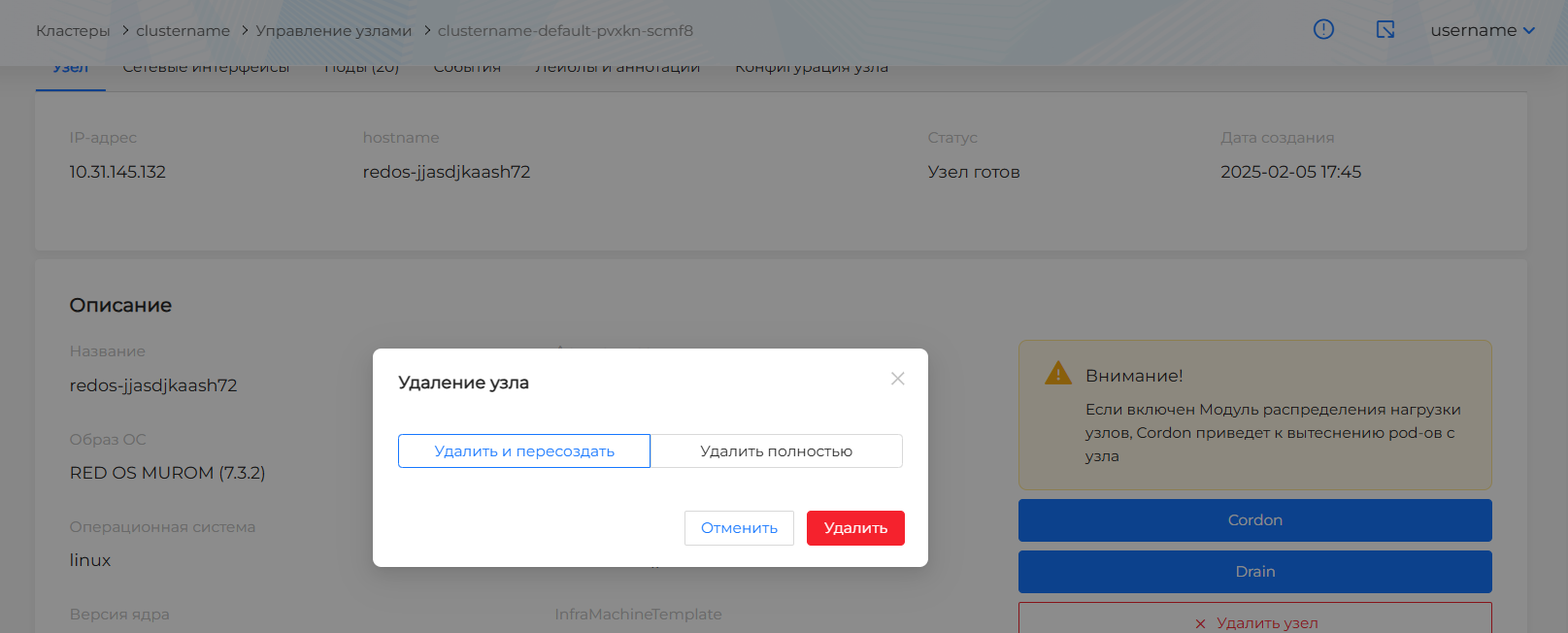
Полное удаление узла доступно только при ручном масштабировании Worker-узлов. Выбор способа масштабирования находится на странице Управление узлами/Конфигурация группы.
Скриншот
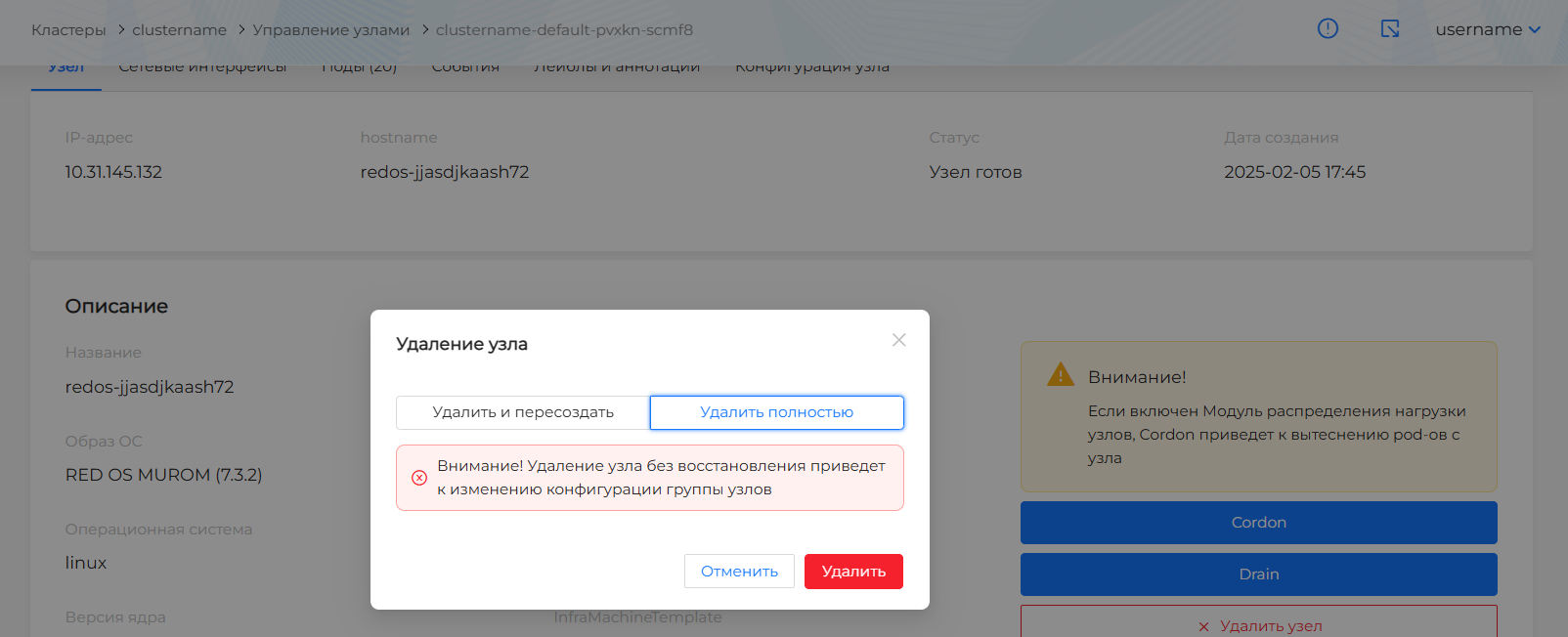
Для узлов группы ControlPlane в интерфейсе можно:
- удалить полностью Master-узел, если после удаления в кластере останется нечетное количество работающих Master-узлов (например: 3 или 1). Наличие работающих узлов проверяется на момент запроса на удаление. В случае несоблюдения условия, запрос на удаление будет недоступен.
Скриншот
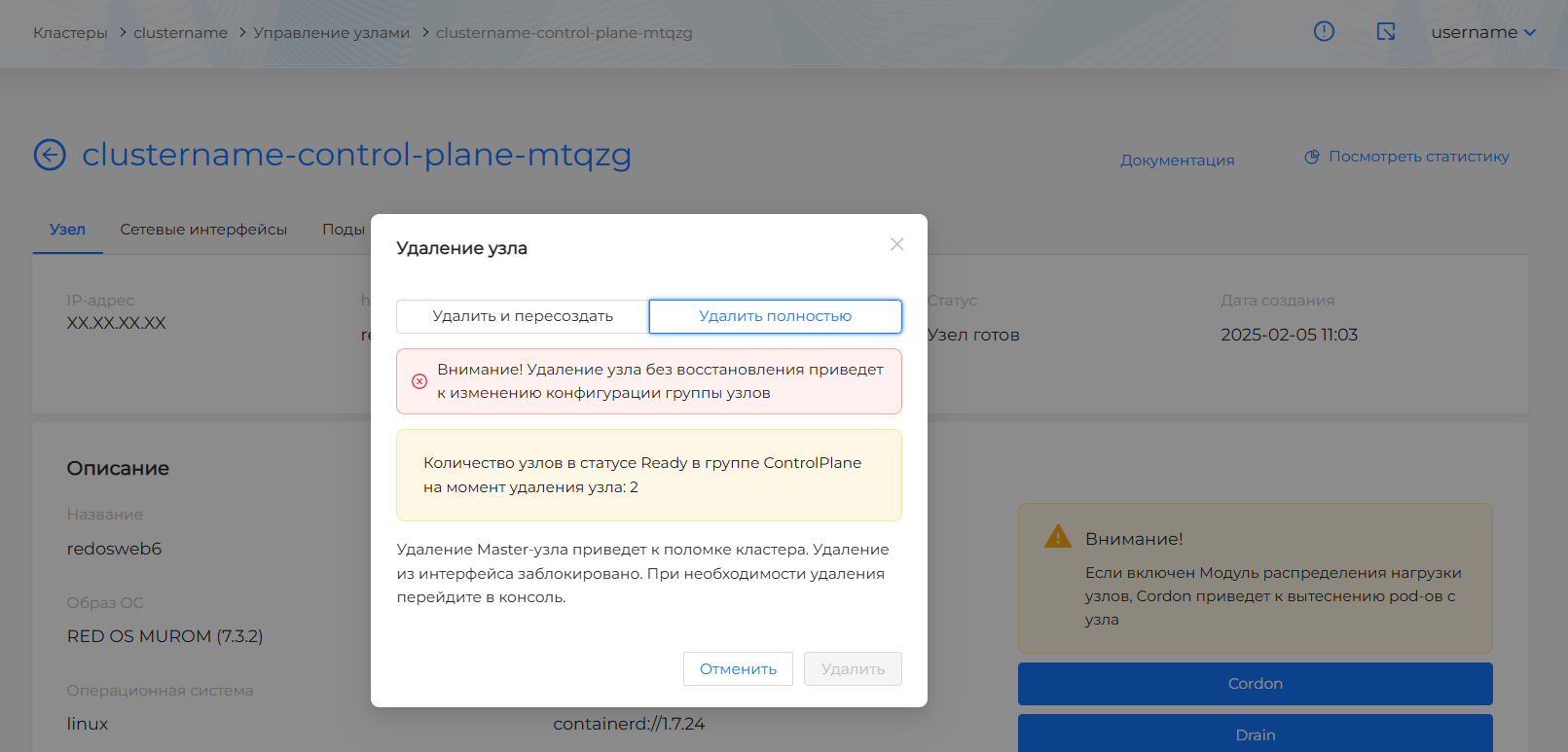
- удалить Master-узел с пересозданием узла при условии, что в результате удаления узла в кластере должно остаться не менее двух работающих Master-узлов. Наличие двух работающих узлов проверяется на момент запроса на удаление. В случае несоблюдения условия, запрос на удаление с пересозданием будет недоступен.
Скриншот
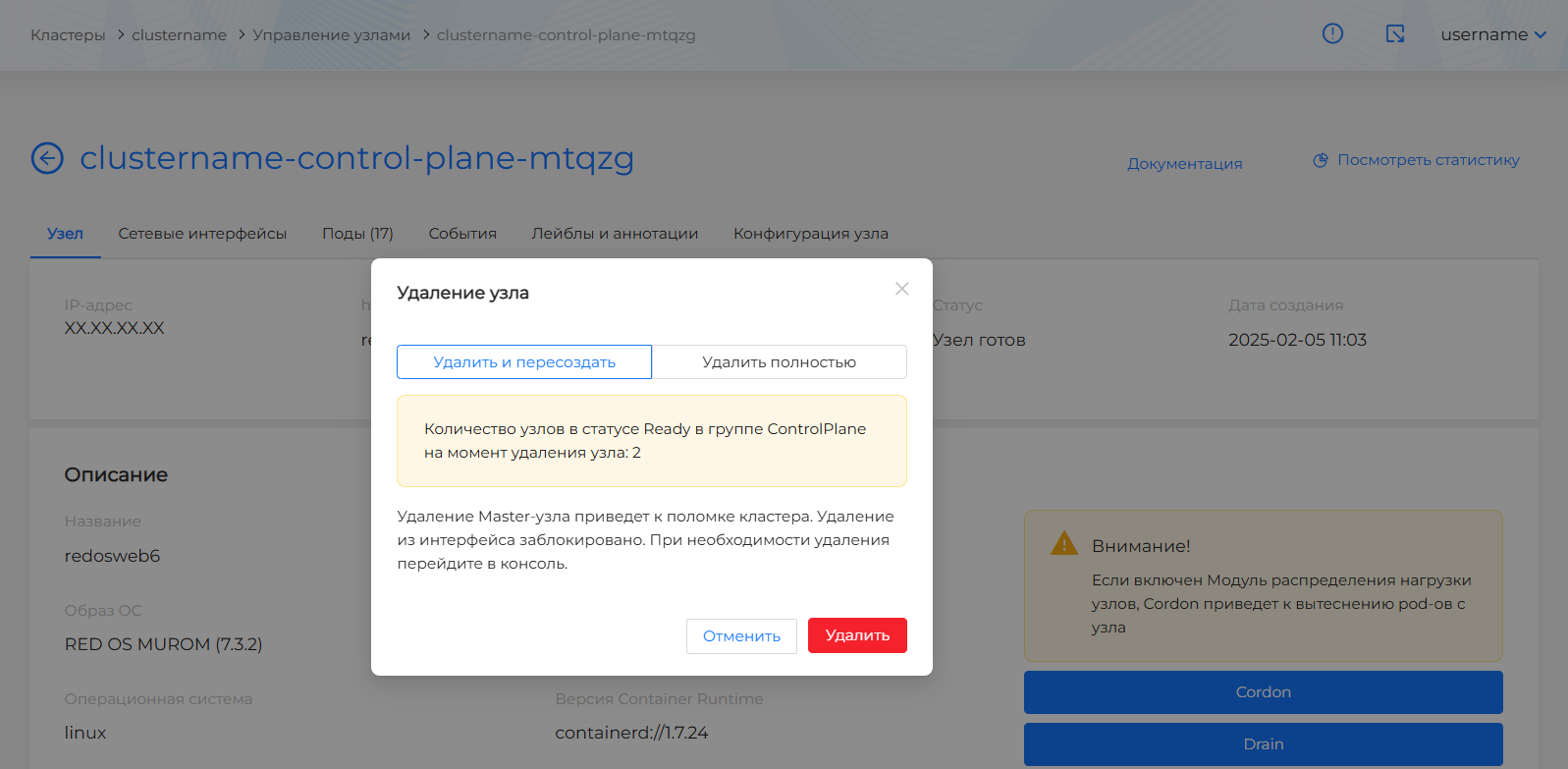
При отправке запроса на удаление Master-узла необходимо ввести названием узла в качестве подтверждения намерения.
В случае, если узел по какой-либо причине выведен из строя и есть необходимость его оперативно удалить без ожидания завершения подов, отсоединения дисков и тп., добавьте такому узлу taint node.kubernetes.io/out-of-service=NoExecute. В таком случае при удалении k8s не будет ожидать стандартного завершения работы узла и в срочном порядке переподнимет поды на другом узле.
Исключение из автоскейлинга
Вы можете защитить узел от удаления в случае автоскейлинга. Для этого на странице узла нажмите на кнопку Исключить из автомасштабирования. Опция доступна только для группы Worker-узлов с включенным автомасштабированием. Исключенные из автоскейлинга узлы будут отмечены на странице “Управление узлами” в колонке “Автомасштабирование” признаком “Запрещено”.
Поведение системы при отказе/недоступности узла
В случае отказа/недоступности узла кластер начинает перераспределять нагрузку с этого узла на другие только спустя 30-60 секунд. Это связано с настройками мониторинга здоровья узлов в kube-controller-manager, а так же настройкой kubelet.
Kubelet периодически уведомляет Kube-APIserver о своём статусе с интервалом, заданным в параметре --node-status-update-frequency. Значение по умолчанию 10 секунд.
Controller manager проверяет статус Kubelet каждые –-node-monitor-period. Значение по умолчанию 5 секунд.
если Kubelet сообщит статус в пределах node-monitor-grace-period, то Controller manager считает что узел исправен
В случае отказа узла кластера происходит следующий алгоритм:
-
Kubelet отправляет свой статус Kube-APIserver в соответствии с параметром nodeStatusUpdateFrequency = 10 сек.
-
Допустим, узел выходит из строя.
-
Controller manager будет пытаться проверить статус узла (от Kubelet) каждые 5 сек (согласно параметру
--node-monitor-period). -
Controller manager определит, что узел не отвечает, и даст ему тайм-аут –node-monitor-grace-period в 40 сек. Если за это время Controller manager не сочтет узел исправным, он установит статус NotReady.
В этом сценарии будут возможны ошибки при обращении к Pods, работающим на этом узле, потому что модули будут продолжать получать трафик до тех пор, пока узел не будет считаться неработающим (NotReady) через 45 сек.
Чтобы увеличить скорость реакции Kubernetes на отказ узлов кластера, вы можете изменить параметры:
-
--nodeStatusUpdateFrequency(по умолчанию 10 сек) в конфиге Kubelet /var/lib/kubelet/config.yaml -
--node-monitor-period(по умолчанию 5 сек ) -
--node-monitor-grace-period(по умолчанию 40 сек)
Обратите внимание, что при уменьшении этих показателей вы увеличиваете риск ложного срабатывания недоступности узла, например, при высокой загрузке узла или временной сетевой недоступности узла. Это может привести к тому, что приложения и нагрузка в кластере будут перераспределяться на другие узлы без действительной необходимости.
Подробнее в официальной документации Kubernetes.
InfraMachineTemplates
При изменении инфраструктурного шаблона в конфигурации группы узлов кластера происходит создание нового инфраструктурного шаблона. Все инфраструктурные шаблоны для этого кластера доступны на вкладке InfraMachineTemplates страницы “Управление узлами”. Доступно удаление шаблонов, не привязанных к группам узлоа.
Скриншот