Services
Alertmanager/Общая информация
Дашборд предназначен для мониторинга состояния Alertmanager. Он обеспечивает визуализацию данных о полученных и отправленных уведомлениях. Дашборд отображает информацию общего количества уведомлений, интенсивности их получения и отправки, а также метрики задержки обработки уведомлений.
Скриншот
Структура дашборда
-
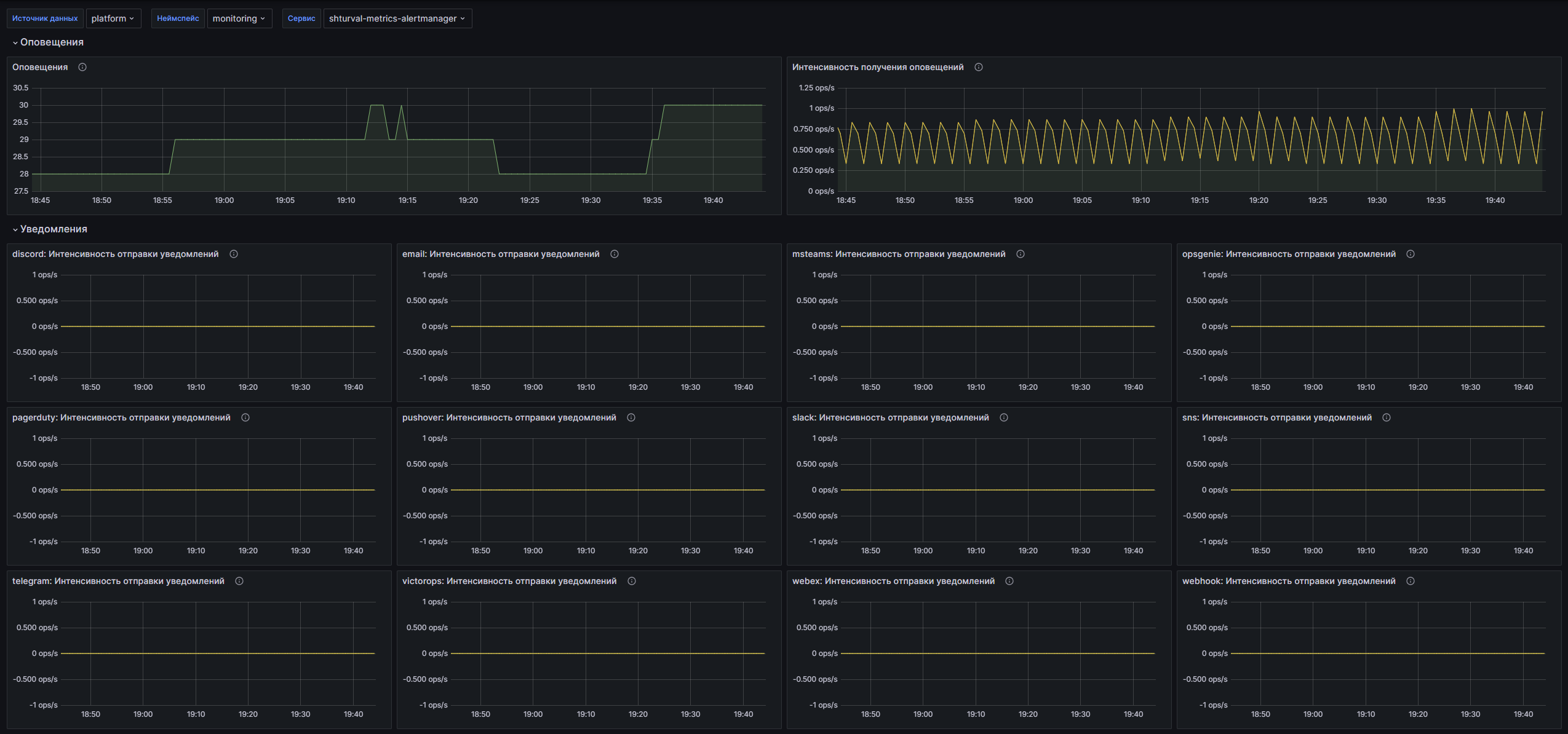
Оповещения:
- Оповещения: Временной график, показывающий общее количество оповещений, полученных Alertmanager.
- Интенсивность получения оповещений: Временной график, показывающий количество успешно полученных и недействительных уведомлений.
-
Уведомления:
- $integration: Интенсивность отправки уведомлений: Временной график, показывающий интенсивность отправки уведомлений, включая успешные и неудачные отправки, для выбранной интеграции.
- $integration: Длительность уведомлений: Отображает метрики задержки отправки уведомлений, отображающие 99-й процентиль, медиану и среднее время отправки уведомлений.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для отображения информации.
- namespace: Позволяет выбрать пространство имен Kubernetes, данные которого будут отображены. Включает опцию выбора всех пространств имен.
- service: Позволяет выбрать конкретный сервис для анализа метрик уведомлений.
Certificates Expiration
Дашборд предназначен для мониторинга состояния сертификатов, предоставляя обширную информацию о сроках их действия. Он включает в себя данные по Kubernetes Secrets, сертификатам на узлах, а также на любых серверах. Он позволяет быстро оценить количество сертификатов, выявить просроченные, а также сертификаты, срок действия которых истекает в ближайшее время, а также проанализировать ошибки загрузчиков сертификатов.
Скриншот
Структура дашборда
-
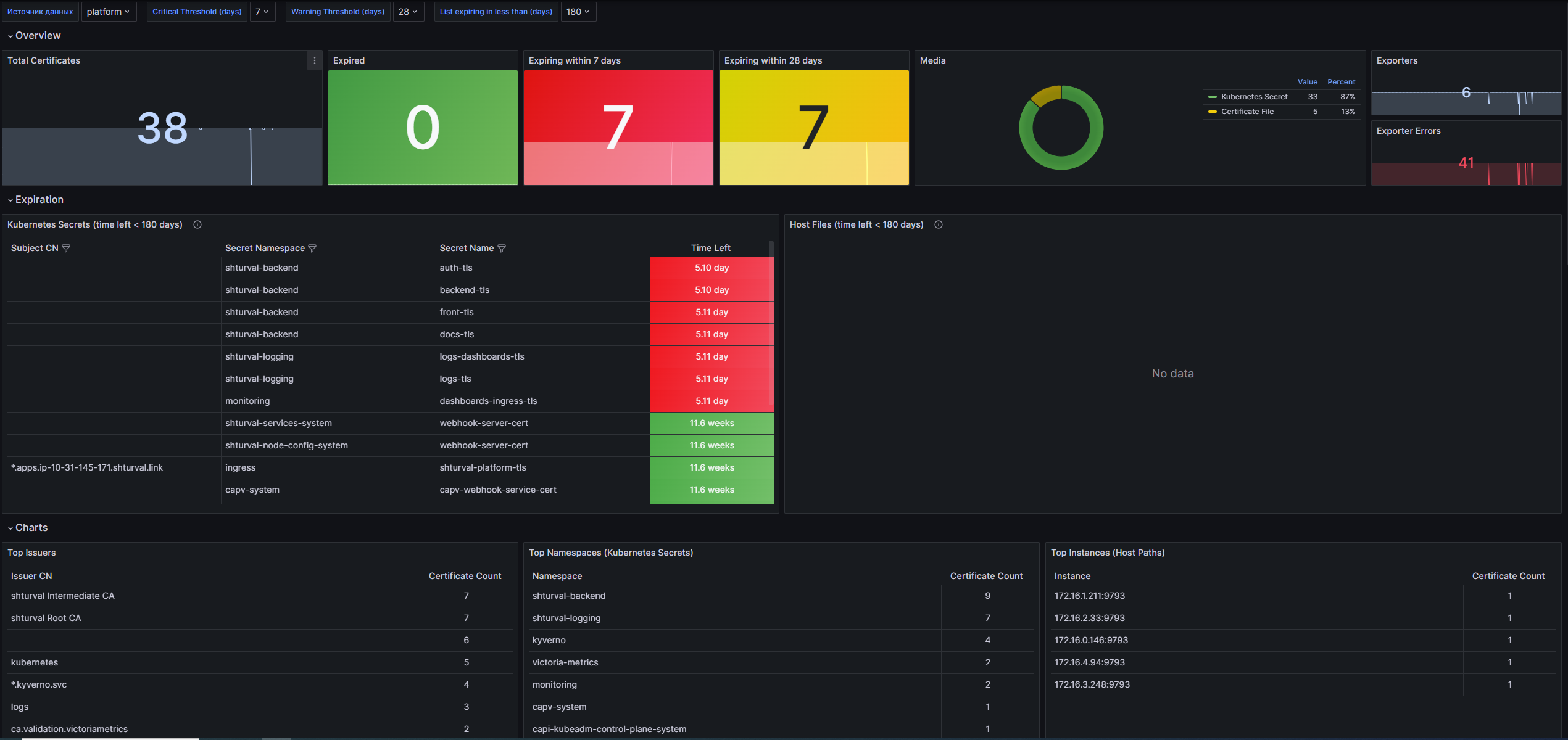
Overview:
- Total Certificates: Отображает общее количество сертификатов, подсчитываемое на основе метрики
x509_cert_not_after. - Expired: Показывает количество сертификатов, срок действия которых истек.
- Expiring within $critical_threshold days: Отображает число сертификатов, срок действия которых истекает в течение критического порога, заданного пользователем.
- Expiring within $warning_threshold days: Показывает число сертификатов, срок действия которых истекает в пределах порога предупреждения.
- Media: Пироговая диаграмма, показывающая распределение сертификатов по типам: Kubernetes Secret, Kubeconfig Embedded и Certificate File.
- Exporters: Показывает общее количество ошибок загрузчиков сертификатов.
- Exporter Errors: Отображает сумму ошибок загрузчиков сертификатов.
- Total Certificates: Отображает общее количество сертификатов, подсчитываемое на основе метрики
-
Expiration:
- Kubernetes Secrets (time left < $list_threshold days): Таблица, отображающая Kubernetes Secrets, срок действия которых истекает меньше чем за заданное количество дней. Обратите внимание, что для окраски столбца Time Left необходимо вручную настраивать пороги в параметрах переопределения этого виджета.
- Host Files (time left < $list_threshold days): Таблица, аналогичная предыдущей, но для сертификатов файлохранителей.
-
Charts:
- Top Issuers: Таблица, показывающая 10 наиболее распространённых удостоверяющих компаний (issuer) на основании количества сертификатов.
- Top Namespaces (Kubernetes Secrets): Таблица, отображающая 10 неймспейсов, в которых находятся Kubernetes Secrets, с наибольшим количеством сертификатов.
- Top Instances (Host Paths): Таблица, показывающая 10 экземпляров (instance) с наибольшим количеством сертификатов файлового хранилища.
- Kubernetes Secrets : Shortest Validity Period: Таблица, отображающая 10 Kubernetes Secrets с наименьшим оставшимся сроком действия.
- Host Paths : Shortest Validity Period: Таблица, показывающая 10 файловых пути с наименьшим оставшимся сроком действия.
- Kubernetes Secrets : Longest Validity Period: Таблица, отображающая 10 Kubernetes Secrets с наибольшим сроком действия.
- Host Paths : Longest Validity Period: Таблица, показывающая 10 файловых пути с наибольшим сроком действия.
-
Exporters:
- Reporting Exporters: График, показывающий количество ошибок загрузчиков.
- Exporters with Errors: График, отображающий количество загрузчиков с ошибками.
- Error Rate: График, показывающий частоту ошибок в загрузчиках за последние 15 минут.
- Cumulative Errors: График, показывающий общее количество ошибок на сегодняшний день.
- Top Exporters by Error Rate: Таблица с 10 загрузчиками с наивысшим уровнем ошибок.
- Top Exporters by Cumulative Errors: Таблица, показывающая 10 загрузчиков с наибольшим числом накопленных ошибок.
Настраиваемые параметры
- Источник данных: Позволяет выбрать источник данных для отображения информации.
- Critical Threshold (days): Критический порог (в днях). Позволяет определить, когда сертификаты должны быть отмечены как требующие внимания.
- Warning Threshold (days): Порог предупреждения (в днях). Позволяет установить временные рамки для раннего оповещения о сертификатах.
- List expiring in less than (days): Позволяет определить список сертификатов, срок действия которых истекает менее чем через заданное количество дней.
Cilium Agent
Дашборд предоставляет возможность отслеживать различные показатели производительности, такие как использование ресурсов, задержки API, управление политикам и сетевую активность в кластере Kubernetes. Набор панелей помогает быстро идентифицировать проблемы и оптимизировать работу сетевых компонентов приложения.
Скриншот
Структура дашборда
-
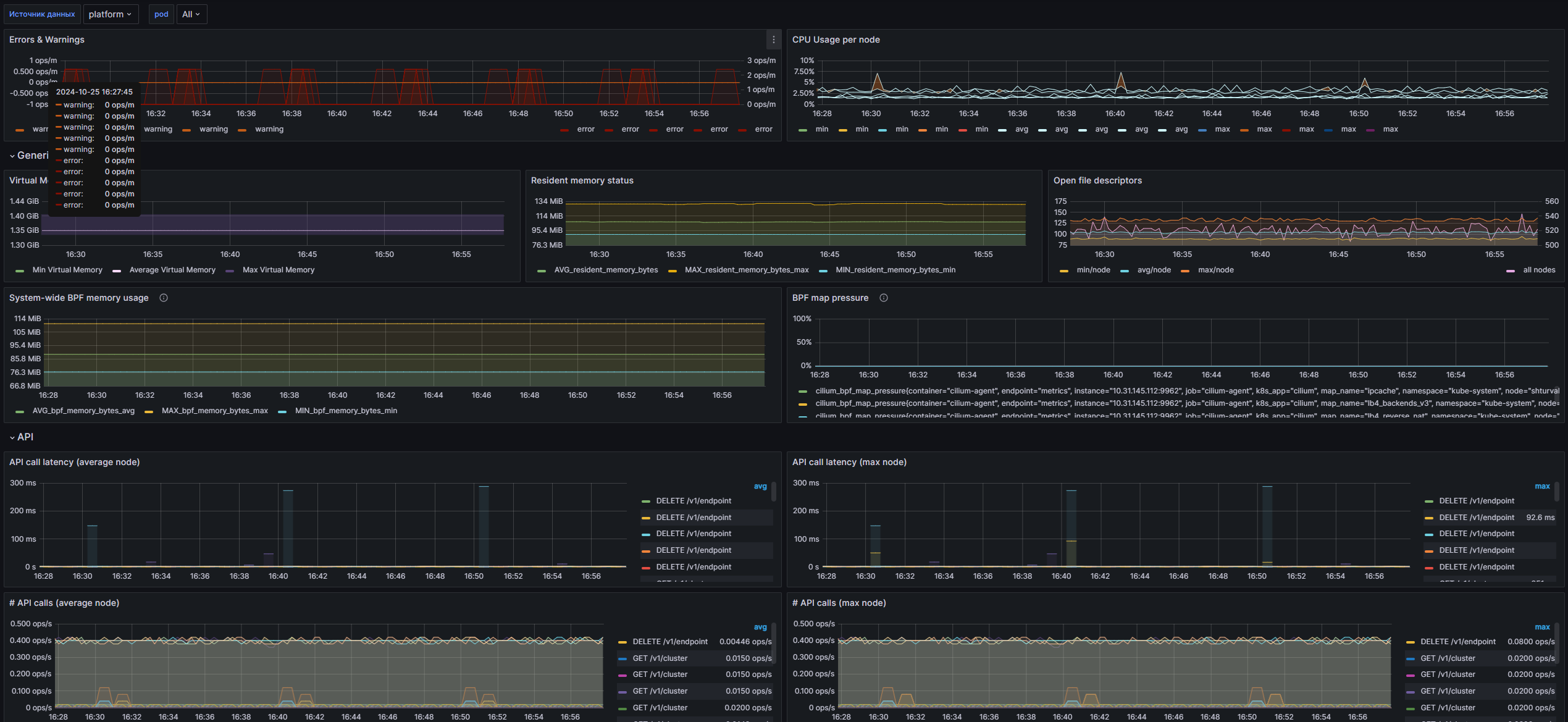
Errors & Warnings: Временной график, показывающий количество ошибок и предупреждений, возникших в кластере Cilium, с разбивкой по уровням.
-
CPU Usage per node: Временной график, показывающий использование CPU на каждом узле, включая минимальные, средние и максимальные значения.
-
Generic:
- Virtual Memory Bytes: Временной график, отображающий показатели виртуальной памяти, включая минимальные, средние и максимальные значения для каждого пода.
- Resident memory status: Временной график, показывающий статус резидентной памяти с минимальными, средними и максимальными значениями.
- Open file descriptors: Временной график, показывающий использование открытых дескрипторов файлов в кластере с минимальными, средними и максимальными значениями.
- System-wide BPF memory usage: Временной график, показывающий использование памяти BPF в системе, включая минимальные, средние и максимальные значения.
- BPF map pressure: Временной график, показывающий процент заполнения карт BPF, помеченных по имени карты.
-
API:
- API call latency (average node): Временной график, показывающий среднее время ожидания вызовов API по каждому узлу.
- API call latency (max node): Временной график, показывающий максимальное время ожидания вызовов API по каждому узлу.
- # API calls (average node): Временной график, показывающий среднее количество вызовов API по каждому узлу.
- # API calls (max node): Временной график, показывающий максимальное количество вызовов API по каждому узлу.
- API return codes (average node): Временной график, показывающий среднее количество кодов возврата вызовов API по каждому узлу.
- API return codes (sum all nodes): Временной график, показывающий суммарное количество кодов возврата вызовов API по всем узлам.
-
Cilium:
-
BPF Функционал не входит в поставку из коробки:
- # system calls (average node): Отображает среднее количество системных вызовов по каждому узлу.
- # system calls (max node): Отображает максимальное количество системных вызовов по каждому узлу.
- system call latency (avg node): Отображает среднюю задержку системных вызовов по каждому узлу.
- system call latency (max node): Отображает максимальную задержку системных вызовов по каждому узлу.
- map ops (average node): Временной график, показывающий средние операции с картами BPF по каждому узлу.
- map ops (max node): Временной график, показывающий максимальные операции с картами BPF по каждому узлу.
- map ops (sum failures): Временной график, показывающий суммарное количество операций с картами BPF, завершившихся неудачно.
-
kvstore Функционал не входит в поставку из коробки:
- # operations (sum all nodes): Отображает суммарное количество операций с хранилищем по всем узлам.
- # operations (max node): Отображает максимальное количество операций с хранилищем по каждому узлу.
- latency (average node): Отображает среднюю задержку операций с хранилищем по каждому узлу.
- latency (max node): Отображает максимальную задержку операций с хранилищем по каждому узлу.
- Events received (average node): Отображает среднее количество полученных событий по каждому узлу.
-
Cilium network information:
- Forwarded Packets: Временной график, показывающий количество пересланных пакетов по направлениям.
- Forwarded Traffic: Временной график, показывающий объем пересланного трафика по направлениям.
- IPv4 Conntrack TCP: Временной график, показывающий статистику TCP соединений для IPv4.
- IPv6 Conntrack TCP: Временной график, показывающий статистику TCP соединений для IPv6.
- IPv4 Conntrack Non-TCP: Временной график, показывающий статистику не-TCP соединений для IPv4.
- IPv6 Conntrack Non-TCP: Временной график, показывающий статистику не-TCP соединений для IPv6.
- Allocated Addresses: Временной график, показывающий количество выделенных IP-адресов.
- Datapath Conntrack Dump Resets: Временной график, показывающий статистику сбросов похищения контракта.
- Service Updates: Временной график, показывающий частоту обновлений сервисов со средними значениями по действиям.
- Connectivity Health: Временной график, показывающий статус доступности узлов и конечных точек здоровья.
- Dropped Egress Packets: Временной график, показывающий количество сброшенных пакетов маршрутизации.
- Node Events: Временной график, показывающий количество событий на узлах со средними значениями по типам событий.
- Dropped Egress Traffic: Временной график, показывающий объем сброшенного исходящего трафика.
- Nodes: Временной график, показывающий количество узлов в кластере с минимальными, средними и максимальными значениями.
-
Policy Функционал не входит в поставку из коробки:
- L7 forwarded request: Отображает количество пересланных, полученных и отклоненных запросов на уровне L7.
- Cilium drops Ingress: Временной график, показывающий количество сброшенных входящих пакетов с разбивкой по причинам.
-
Endpoints:
- Endpoint regeneration time (90th percentile): Временной график, показывающий время регенерации конечных точек (90-й процентиль).
- Endpoint regeneration time (99th percentile): Временной график, показывающий время регенерации конечных точек (99-й процентиль).
- Endpoint regenerations: Временной график, показывающий общее количество регенераций конечных точек с разбивкой по итоговому результату.
- Cilium endpoint state: Временной график, показывающий статус конечных точек в кластере с разбивкой по состояниям.
-
Controllers:
- Controllers: Временной график, показывающий выполнение контроллеров и число возникающих ошибок.
- Controller Durations: Временной график, показывающий среднюю продолжительность выполнения контроллеров с разбивкой по статусам.
-
Kubernetes integration:
- apiserver latency (average node): Временной график, показывающий среднюю задержку API сервера для каждого узла.
- apiserver latency (max node): Временной график, показывающий максимальную задержку API сервера для каждого узла.
- apiserver #calls (sum all nodes): Временной график, показывающий общее количество вызовов API сервера для всех узлов.
- apiserver calls (sum all nodes): Временной график, показывающий общее количество вызовов API сервера по всем узлам.
- Valid, Unnecessary K8s Events Received: Временной график, показывающий количество валидных, но ненужных событий Kubernetes.
- Invalid, Unnecessary K8s Events Received: Временной график, показывающий количество недопустимых и ненужных событий Kubernetes.
- Valid, Necessary K8s Events Received: Временной график, показывающий количество валидных и необходимых событий Kubernetes.
- Invalid, Necessary K8s Events Received: Временной график, показывающий количество недопустимых, но необходимых событий Kubernetes.
- CiliumNetworkPolicy Events: Временной график, показывающий количество событий, связанных с политиками CiliumNetworkPolicy.
- NetworkPolicy Events: Временной график, показывающий количество событий, связанных с политиками NetworkPolicy.
- Pod Events: Временной график, показывающий события, связанные с подами.
- Node Events: Временной график, показывающий события, связанные с узлами.
- Service Events: Временной график, показывающий события, связанные с сервисами.
- Endpoints Events: Временной график, показывающий события, связанные с конечными точками.
- Namespace Events: Временной график, показывающий события, связанные с неймспейсами.
-
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для отображения информации.
- pod: Позволяет выбрать pod для более точного мониторинга и анализа данных.
Cilium Operator
Дашборд предназначен для мониторинга метрик оператора Cilium версии 1.12, который использует наблюдение за сетевыми взаимодействиями, управлением IP-адресами и производительностью. Он предоставляет информацию о таких метриках, как использование CPU, статус резидентной памяти, взаимодействия с API EC2 и создание интерфейсов. Дашборд позволяет отслеживать здоровье и производительность системы в реальном времени.
Скриншот

Структура дашборда
-
CPU Usage per node: Временной график, показывающий использование CPU для каждого узла в процентах. График включает минимальные, средние и максимальные значения метрик.
-
Resident memory status: Временной график, показывающий статус резидентной памяти для оператора, включая средние, максимальные и минимальные значения в байтах.
-
IPAM Функционал не входит в поставку из коробки:
- IP Addresses: Временной график, показывающий среднее количество IP-адресов по типу, обеспечивая информацию о распределении адресов.
- EC2 API Interactions: Панель визуализирует взаимодействия с EC2 API, отображая время отклика для различных операций и кодов ответов.
- Number of nodes: Панель показывает текущее количество узлов, управляемых оператором, с метриками по категориям.
- Interfaces with addresses available: Панель отображает количество интерфейсов, к которым доступны адреса, что помогает в управлении IP-адресами.
- Metadata Resync Operations: Панель отображает частоту операций синхронизации метаданных, подсчитывая количество операций за минуту.
- EC2 client side rate limiting: Панель показывает показатели ограничения на стороне клиента EC2, отображая среднее время реакции на операции.
- Interface Creation: Панель визуализирует операции создания интерфейсов, отображая среднее количество операций по статусу и идентификатору подсети.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для отображения информации.
Kyverno
Дашборд предназначен для мониторинга политики управления Kubernetes. Он обеспечивает визуализацию ключевых метрик, связанных с выполнением политик, их состоянием и эффективность работы. Дашборд предоставляет возможность отслеживать актуальные результаты выполнения политик, уровень успешности проверок, а также использование ресурсов (ЦПУ и памяти) как по запросам, так и по лимитам. Дашборд помогает быстро идентифицировать проблемы с политиками и оптимизировать ресурсы кластера.
Скриншот
Структура дашборда
-
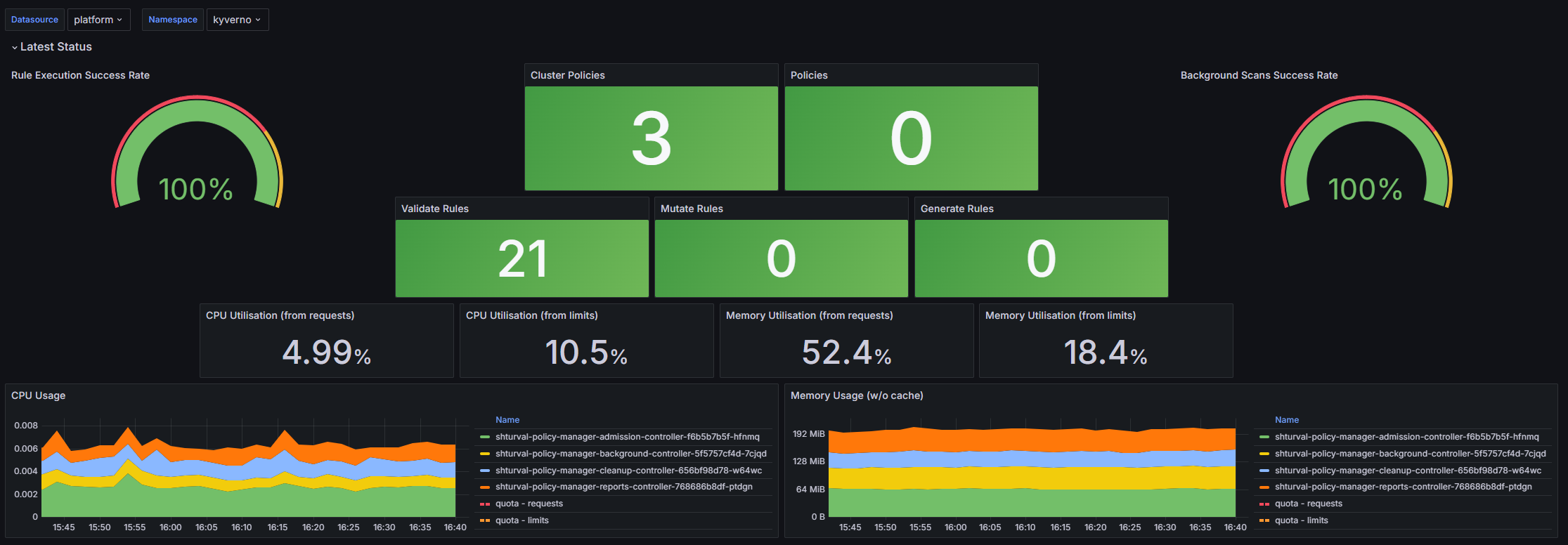
Latest Status:
- Rule Execution Success Rate: Отображает процент успешного выполнения правил политик.
- Cluster Policies: Отображает количество активных кластерных политик.
- Policies: Отображает количество активных политик с неймспейсами.
- Background Scans Success Rate: Отображает уровень успешности фоновых проверок политик.
- Validate Rules: Отображает информацию о количестве правил верификации.
- Mutate Rules: Отображает информацию о количестве правил изменения.
- Generate Rules: Отображает информацию о количестве правил генерации.
- CPU Utilisation (from requests): Отображает использование ЦПУ по запросам политик, в пределах заданного неймспейса.
- CPU Utilisation (from limits): Отображает использование ЦПУ по лимитам политик, в пределах заданного неймспейса.
- Memory Utilisation (from requests): Отображает использование памяти по запросам политик, в пределах заданного неймспейса.
- Memory Utilisation (from limits): Отображает использование памяти по лимитам политик, в пределах заданного неймспейса.
- CPU Usage: Временной график, показывающий использование ЦПУ по подам, с учетом запросов и лимитов.
- Memory Usage (w/o cache): Временной график, показывающий использование памяти по подам без кэша.
-
Policy-Rule Results:
- Admission Review Results (per-rule): Временной график, показывающий результаты проверки запросов на основе каждого правила.
- Background Scan Results (per-rule): Временной график, показывающий результаты фоновых проверок на основе каждого правила.
- Policy Failures: Отображает количество сбоев политик, сгруппированных по типу.
- Admission Review Results (per-policy): Временной график, показывающий результаты проверки запросов на основе каждой политики.
- Background Scan Results (per-policy): Временной график, показывающий результаты фоновых проверок на основе каждой политики.
- Cluster Policies and Namespaces w/Failed: Отображает информацию о кластерных политиках и неймспейсах, где произошли сбои.
-
Policy-Rule Info:
- Active Policies (by policy type): Временной график, показывающий количество активных политик, сгруппированных по типу.
- Active Policies (by policy validation action): Временной график, показывающий количество активных политик, сгруппированных по действию проверки.
- Active Policies running in background mode: Временной график, показывающий количество активных политик, работающих в фоновом режиме.
- Active Namespaced Policies (by namespaces): Временной график, показывающий количество активных пространственно-зависимых политик, сгруппированных по неймспейсу.
- Active Rules (by rule type): Временной график, показывающий количество активных правил, сгруппированных по типу.
-
Policy-Rule Execution Latency:
- Average Rule Execution Latency: Временной график, показывающий среднюю задержку выполнения правил.
- Average Policy Execution Latency: Временной график, показывающий среднюю задержку выполнения политик.
- Overall Average Rule Execution Latency: Отображает общее среднее значение задержки выполнения правил.
- Overall Average Policy Execution Latency: Отображает общее среднее значение задержки выполнения политик.
-
Admission Review Latency:
- Avg - Admission Review Duration (by operation): Временной график, показывающий среднюю продолжительность проверки admission по операциям.
- Avg - Admission Review Duration (by resource kind): Временной график, показывающий среднюю продолжительность проверки admission по видам ресурсов.
- Rate - Incoming Admission Requests (last 5m): Отображает скорость входящих запросов на admission за последние 5 минут.
- Avg - Overall Admission Review Duration: Отображает среднюю продолжительность всех проверок admission.
-
Policy Changes:
- Policy Changes (by change type): Временной график, показывающий изменения политик, сгруппированные по типу изменений.
- Policy Changes (by policy type): Временной график, показывающий изменения политик, сгруппированные по типу политики.
- Total Policy Changes: Отображает общее количество изменений политик.
- Rate - Policy Changes Happening (last 5m): Отображает скорость изменений политик за последние 5 минут.
-
Admission Requests:
- Admission Requests (by operation): Временной график, показывающий количество запросов на admission по операциям.
- Admission Requests (by resource kind): Временной график, показывающий количество запросов на admission по видам ресурсов.
- Total Admission Requests: Отображает общее количество запросов на admission.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для отображения информации.
- namespace: Позволяет фильтровать метрики по определенному неймспейсу в Kubernetes, используя значения метки
kube_namespace_status_phase.
Go Runtime Exporter
Дашборд предназначен для мониторинга параметров производительности приложений, написанных на языке Go. Он позволяет отслеживать использование памяти, количество объектов в памяти и характеристики сборщика мусора в реальном времени. Дашборд предлагает предварительно сконфигурированные графики и правила оповещения для быстрого анализа и диагностики работы приложений.
Скриншот
Структура дашборда
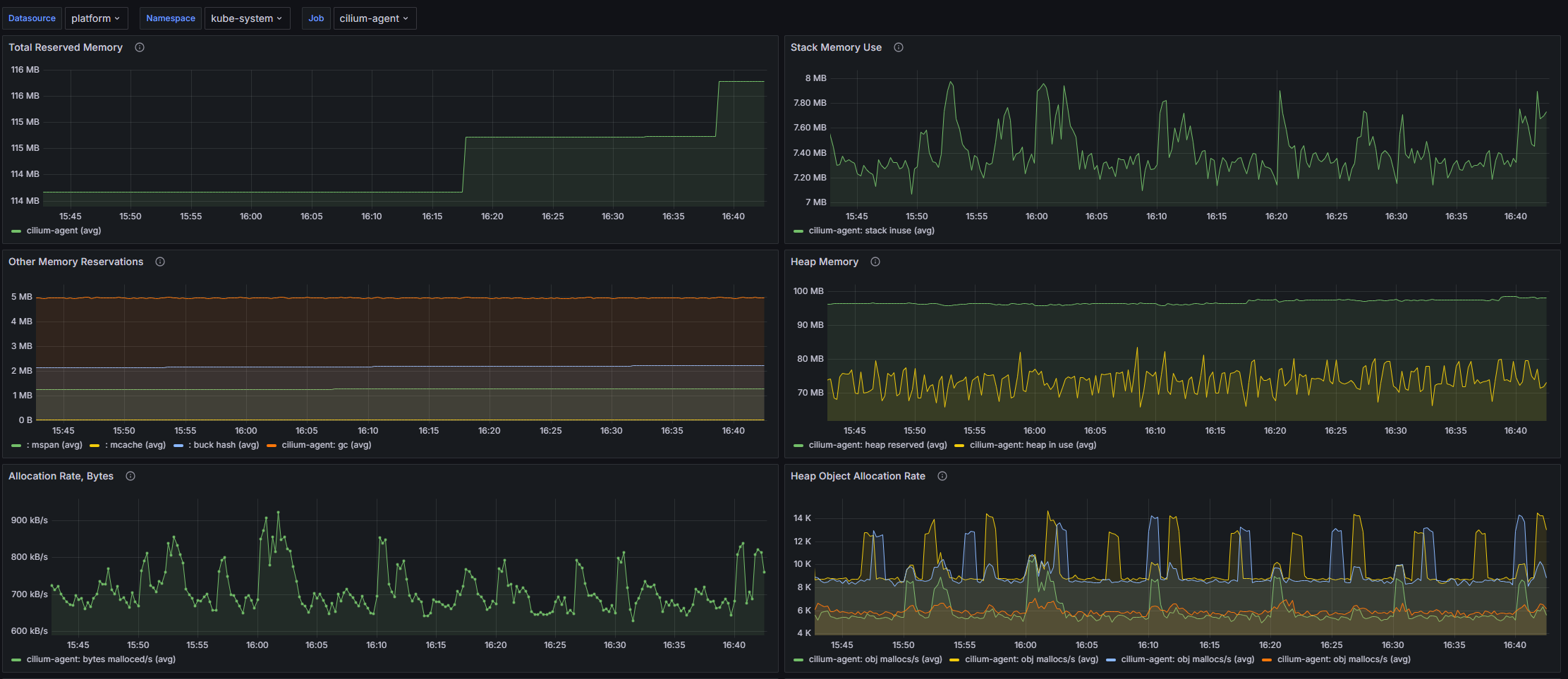
- Total Reserved Memory: Временной график, показывающий среднее значение общего объема зарезервированной памяти во всех неймспейсах приложения.
- Stack Memory Use: Временной график, показывающий среднее значение использования стековой памяти во всех неймспейсах приложения.
- Other Memory Reservations: Временной график, показывающий среднее значение резервирования памяти для других нужд, не включая стек и кучу, во всех неймспейсах приложения.
- Heap Memory: Временной график, показывающий среднее значения, связанные с памятью кучи, включая зарезервированную, используемую и выделенную память.
- Allocation Rate, Bytes: Временной график, показывающий среднюю скорость выделения памяти в байтах в секунду во всех неймспейсах приложения.
- Heap Object Allocation Rate: Временной график, показывающий среднюю скорость выделения объектов в куче во всех неймспейсах приложения.
- Number of Live Objects: Временной график, показывающий среднее количество живых объектов в памяти во всех неймспейсах приложения.
- Goroutines: Временной график, показывающий среднее количество Go-рутин во всех неймспейсах приложения.
- GC min & max duration: Временной график, показывающий средние минимальную и максимальную длительность сборки мусора (GC).
- Next GC, Bytes: Временной график, показывающий среднее количество байт, используемых до следующей сборки мусора.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для отображения информации.
- namespace: Позволяет выбрать пространство имен Kubernetes, данные которого будут отображены. Включает опцию выбора всех пространств имен.
- job: Позволяет выбрать конкретную задачу, по которой будут отображаться метрики, фильтруя результаты согласно выбранной задаче и неймспейсу.
Vector Cluster Monitoring
Дашборд предназначен для мониторинга кластеров Kubernetes с использованием Vector.dev. Он предоставляет информацию о загрузке процессора, использовании памяти, сетевой активности и состоянии служб. Дашборд помогает отслеживать различные метрики и показатели производительности как на уровне управления (control plane), так и на уровне приложений, работающих в контейнерах.
Скриншот
Структура дашборда
-
Overview:
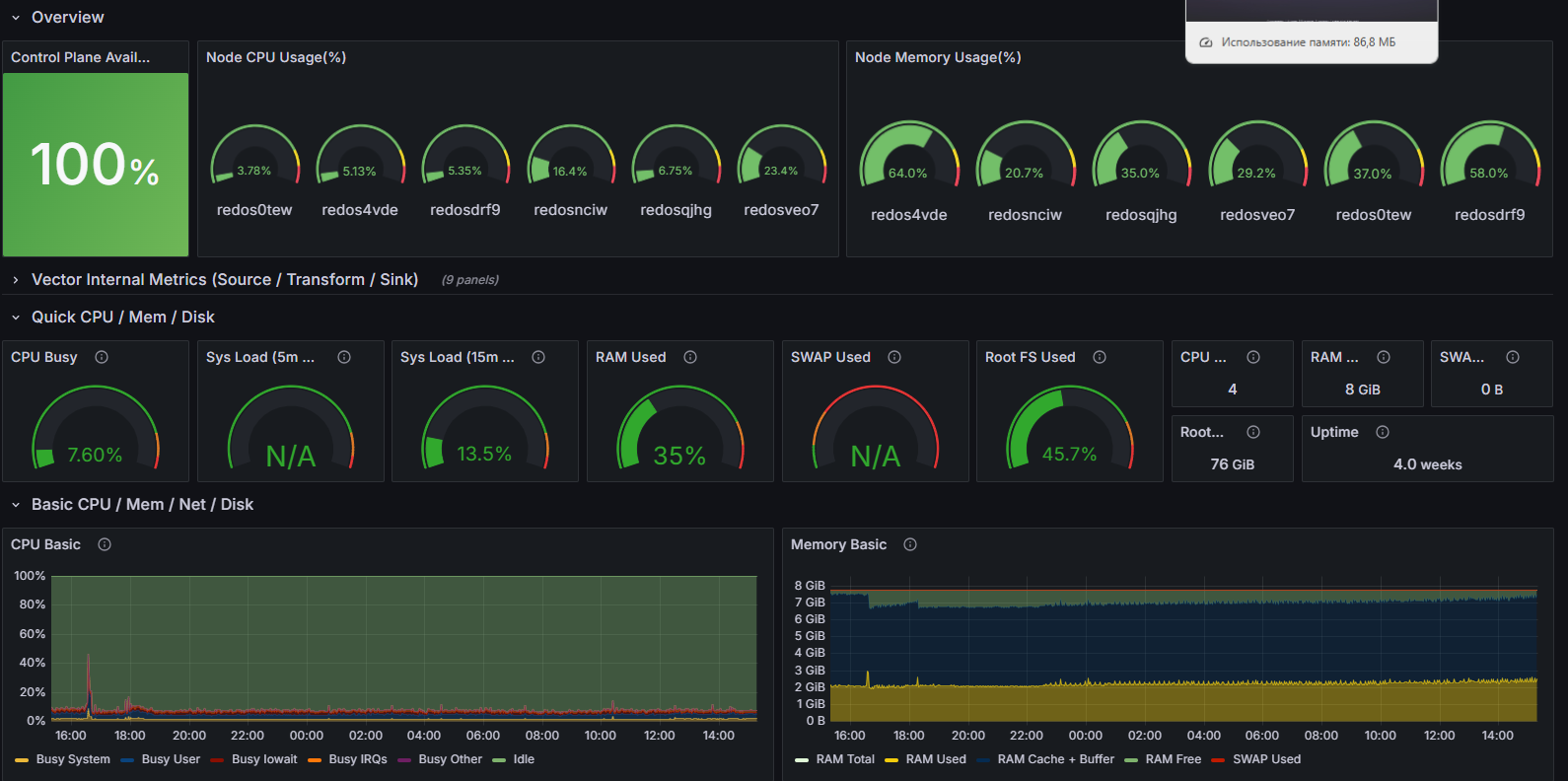
- Control Plane Availability: Отображает доступность управляющей плоскости кластера, измеряясь по количеству готовых контейнеров в пространстве имен “kube-system”.
- Vector pod count per Node: Отображает количество подов Vector на каждом узле в кластере.
- Node CPU Usage(%): Отображает отношение использованных ресурсов процессора на узлах.
- Node Memory Usage(%): Отображает процент использования памяти на узлах.
- Vector Namespace Pods: Отображает количество подов Vector в выбранном пространстве имен.
-
Vector Internal Metrics (Source / Transform / Sink):
- Input events count (events/sec): Временной график, показывающий количество входящих событий в секунду для компонентов типа “source”.
- Input events bytes rate (bytes/sec): Временной график, показывающий скорость обработки байтов входящих событий.
- Transform events count (events/sec): Пироговая диаграмма, показывающая количество событий, обрабатываемых компонентами типа “transform”.
- Transform events bytes rate (bytes/sec): Временной график, показывающий скорость обработки байтов для событий, которые были преобразованы.
- Transform utilization: Временной график, показывающий коэффициент загрузки компонентов типа “transform”.
- Output events bytes count (events/sec): Временной график, показывающий общее количество байтов, обработанных компонентами типа “sink”.
- Output events count (events/sec): Пироговая диаграмма, показывающая количество выходящих событий в секунду.
- Output events bytes rate (bytes/sec): Временной график, показывающий скорость обработки байтов выходящих событий.
- Output utilization: Временной график, показывающий коэффициент загрузки для компонентов типа “sink”.
-
Quick CPU / Mem / Disk:
- CPU Busy: Отображает загрузку всех ядер процессора.
- Sys Load (5m avg): Отображает среднюю загрузку за последние 5 минут.
- Sys Load (15m avg): Отображает среднюю загрузку за последние 15 минут.
- RAM Used: Отображает используемую память.
- SWAP Used: Отображает использование swap-памяти.
- Root FS Used: Отображает использование корневой файловой системы.
- CPU Cores: Отображает общее количество ядер CPU.
- RAM Total: Отображает общее количество оперативной памяти.
- SWAP Total: Отображает общее количество swap-памяти.
- RootFS Total: Отображает общее количество файловой системы корневого раздела.
- Uptime: Отображает отображает время работы системы.
-
Basic CPU / Mem / Net / Disk:
- CPU Basic: Временной график, показывающий базовую информацию о загрузке CPU, включая времени в разных режимах работы.
- Memory Basic: Временной график, показывающий общее и используемое количество оперативной памяти.
- Network Traffic Basic: Временной график, показывающий информацию о сетевом трафике по каждому интерфейсу.
- Disk Space Used Basic: ПВременной график, показывающий процент использования дискового пространства для всех примонтированных файловых систем.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для отображения информации.
- node: Позволяет пользователю выбрать конкретный узел для мониторинга.
- job: Позволяет выбрать конкретную задачу, по которой будут отображаться метрики, фильтруя результаты согласно выбранной задаче и неймспейсу.
- namespace: Позволяет выбрать пространство имен Kubernetes, данные которого будут отображены. Включает опцию выбора всех пространств имен.
Обзор Grafana
Дашборд предназначен для мониторинга и анализа данных, связанных с производительностью и работоспособностью системы Grafana. Он позволяет отслеживать метрики, такие как количество предупреждений, общее количество дашбордов, информацию о сборках, запросах к Grafana и их продолжительности. Дашборд помогает в быстрой идентификации проблем в работе приложения и оптимизации производительности.
Скриншот
Структура дашборда
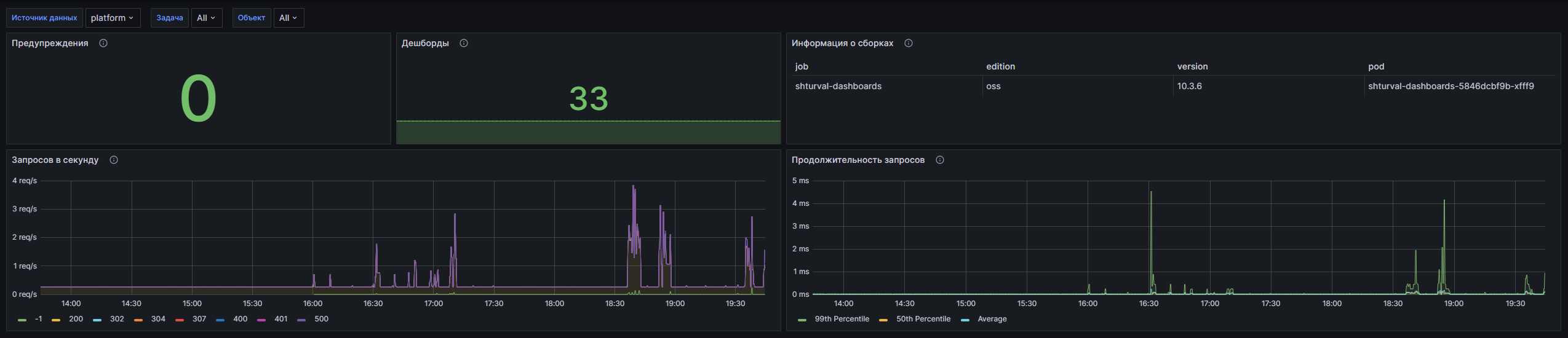
- Предупреждения: Отображает суммарное количество всех предупреждений в системе в текущий момент.
- Дашборды: Отображает суммарное количество дашбордов, доступных в системе.
- Информация о сборках: Отображает сводную информацию о сборках Grafana, включая ключевые метрики.
- Запросов в секунду: Временной график, показывающий суммарное количество запросов к Grafana в секунду. Помогает отслеживать нагрузку на систему в реальном времени.
- Продолжительность запросов: Временной график, показывающий процентильные значения (99-й и 50-й) продолжительности HTTP-запросов к Grafana, а также среднее время выполнения запросов.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для отображения информации.
- job: Позволяет выбрать конкретную задачу, по которой будут отображаться метрики, фильтруя результаты согласно выбранной задаче и неймспейсу.
- pod: Позволяет выбрать pod для более точного мониторинга и анализа данных.
Trivy Operator - Vulnerabilities
Дашборд предназначен для мониторинга уязвимостей в Kubernetes-кластерах с помощью Trivy Operator от Aqua Security. Он реализует современные функции Grafana, предоставляя пользователям централизованное представление информации о состоянии безопасности образов, конфигураций и RBAC-оценок. Дашборд помогает в выявлении уязвимостей различной степени серьезности (Critical, High, Medium, Low и Unknown) и представляет информацию в удобной для анализа форме.
Скриншот
Структура дашборда
-
Vulnerabilities:
- CRITICAL: Отображает общее количество уязвимостей с уровнем серьезности “Critical” в выбранных пространстве имен и кластере.
- HIGH: Отображает общее количество уязвимостей с уровнем серьезности “High” в выбранных пространстве имен и кластере.
- MEDIUM: Отображает общее количество уязвимостей с уровнем серьезности “Medium” в выбранных пространстве имен и кластере.
- LOW: Отображает общее количество уязвимостей с уровнем серьезности “Low” в выбранных пространстве имен и кластере.
- UNKNOWN: Отображает общее количество уязвимостей с уровнем серьезности “Unknown” в выбранных пространстве имен и кластере.
- TOTAL: Отображает общее количество всех уязвимостей в выбранных пространстве имен и кластере.
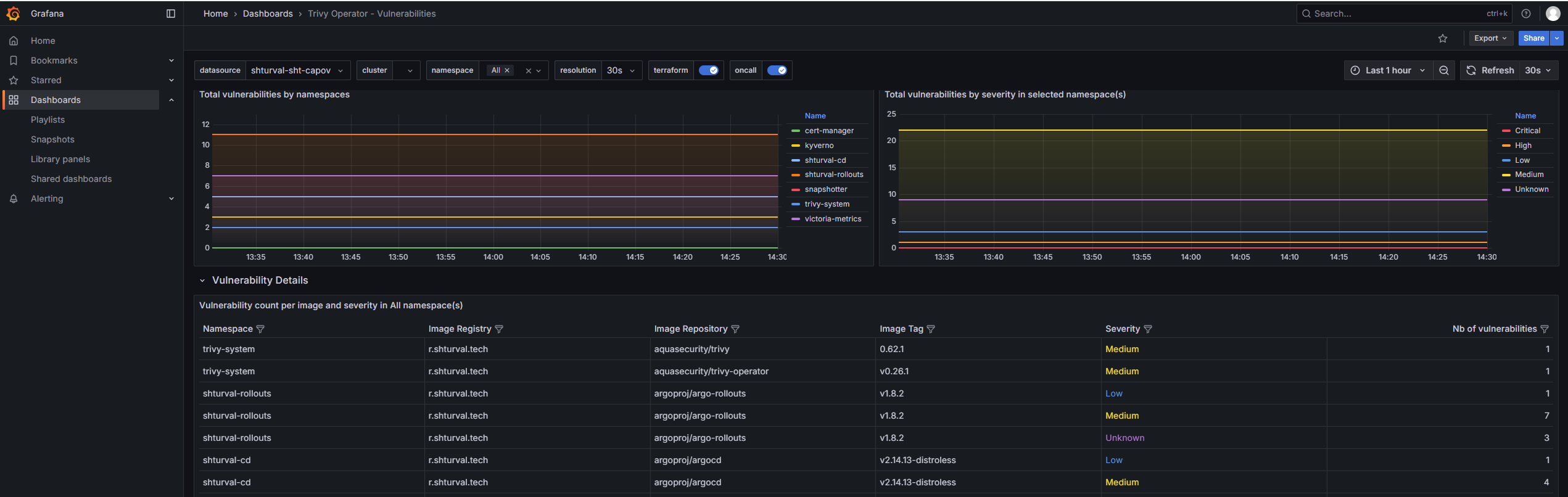
- Total vulnerabilities by namespaces: Временной график, показывающий общее количество уязвимостей в образах по пространствам имен.
- Total vulnerabilities by severity in selected namespace(s): Временной график, показывающий распределение уязвимостей по степеням серьезности в выбранных пространствах имен.
-
Vulnerability Details:
- Vulnerability count per image and severity in $namespace namespace(s): Таблица, показывающая количество уязвимостей по изображениям и степеням серьезности в выбранных пространствах имен.
- Detailed CVE vulnerabilities in $namespace namespace(s): Таблица, представляющая детальную информацию о CVE-вызванных уязвимостях в выбранных пространствах имен. Отключен в операторе
-
Config Audit Reports:
- CRITICAL: Отображает количество критических аудитов конфигураций в выбранных пространстве имен и кластере.
- HIGH: Отображает количество высоких аудитов конфигураций в выбранных пространстве имен и кластере.
- MEDIUM: Отображает количество средних аудитов конфигураций в выбранных пространстве имен и кластере.
- LOW: Отображает количество низких аудитов конфигураций в выбранных пространстве имен и кластере.
- TOTAL: Отображает общее количество аудитов конфигураций в выбранных пространстве имен и кластере.
- Total config audit report by namespaces: Временной график, показывающий общее количество аудитов конфигураций по пространствам имен.
- Total config audit report by severity: Временной график, показывающий распределение аудитов конфигураций по степеням серьезности.
-
RBAC Assessments Не используется:
- CRITICAL: Отображает количество критических оценок RBAC в выбранных пространстве имен и кластере.
- HIGH: Отображает количество высоких оценок RBAC в выбранных пространстве имен и кластере.
- MEDIUM: Отображает количество средних оценок RBAC в выбранных пространстве имен и кластере.
- LOW: Отображает количество низких оценок RBAC в выбранных пространстве имен и кластере.
- TOTAL: Отображает общее количество оценок RBAC в выбранных пространстве имен и кластере.
- Total RBAC Assessments by namespaces: Временной график, показывающий общее количество оценок RBAC по пространствам имен.
- Total RBAC Assessments by severity: Временной график, показывающий распределение оценок RBAC по степеням серьезности.
-
Exposed Secrets Не используется:
- Total Exposed Secrets by namespaces: Временной график, показывающий общее количество открытых секретов по пространствам имен.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных для отображения информации.
- cluster: Позволяет выбрать кластер Kubernetes, данные которого будут отображены.
- namespace: Позволяет выбрать пространство имен Kubernetes, данные которого будут отображены. Включает опцию выбора всех пространств имен.
- resolution: Настройка временного интервала для данных, предоставляемых дашбордом (доступные значения: 1s, 15s, 30s, 1m, 3m, 5m).
Backend API Monitoring
Дашборд предназначен для мониторинга производительности и состояния Backend API. Он предоставляет комплексный обзор ключевых метрик, включая использование памяти, время отклика, размеры запросов и ответов, количество и успешность запросов, а также статистику по наиболее загруженным эндпоинтам. Используются технические показатели из системы мониторинга Prometheus, что позволяет оценивать эффективность работы API и выявлять узкие места в его производительности в реальном времени.
Скриншот
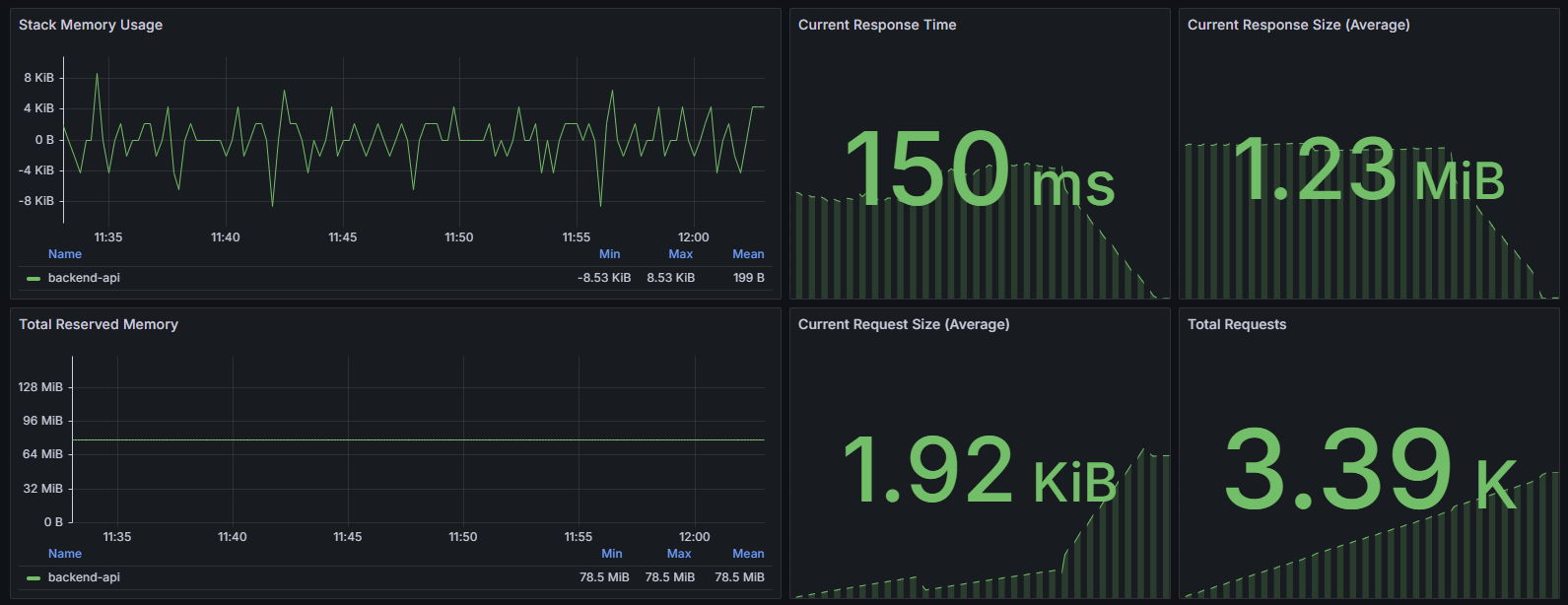
Структура дашборда
- Stack Memory Usage: Отображает производную по времени использования памяти (stack_inuse_bytes) для контейнера backend-api, что позволяет отслеживать, как меняется стековая память во времени.
- Current Response Time: Показывает текущие средние время отклика API путём деления суммы длительности всех запросов на количество запросов за выбранный интервал.
- Current Response Size (Average): Средний размер ответов API, вычисляемый как отношение суммарного размера ответов к их количеству за интервал.
- Total Reserved Memory: Временной график, показывающий среднее системное выделение памяти (sys_bytes) для backend-api, что отражает общее количество выделенной памяти под процесс.
- Current Request Size (Average): Средний размер входящих запросов, рассчитанный как отношение суммарного размера запросов к их количеству.
- Total Requests: Общее число запросов к API за период, агрегированное по контейнеру.
- Go Runtime Metrics: Временной график количества горутины в Go-приложении backend-api, что является индикатором загрузки исполнителя.
- Success Rate (non-4|5xx responses): Доля успешных ответов, не относящихся к ошибкам клиентской (4xx) и серверной (5xx) категории, по каждому URL.
- Client requests: Временной график, показывающий топ-10 чередующихся по интенсивности запросов с разбивкой по URL, методам и кодам ответов.
- Top Endpoints by Requests: Таблица, отображающая топ-10 эндпоинтов по количеству запросов с детализацией по URL, методу и коду ответа.
Настраиваемые параметры
- Datasource: Позволяет выбрать источник данных, используемый для получения метрик.
- job: Позволяет фильтровать по значению лейбла
jobв метриках Prometheus. Используется для выбора набора данных, относящихся к нужному процессу или сервису.
Cluster API Controller Manager
Дашборд предназначен для мониторинга работы Cluster API Controller Manager в Kubernetes-кластере. Он предоставляет комплексный обзор состояния подключения к кластерам, здоровья кластеров, производительности контроллеров и ключевых метрик, связанных с их работой. Используются метрики Prometheus, отражающие такие показатели, как ошибки согласования, время выполнения операций, глубина рабочих очередей и статус лидерства. Это позволяет специалистам по DevOps и SRE оперативно выявлять и реагировать на проблемы в системе управления кластерами.
Скриншот
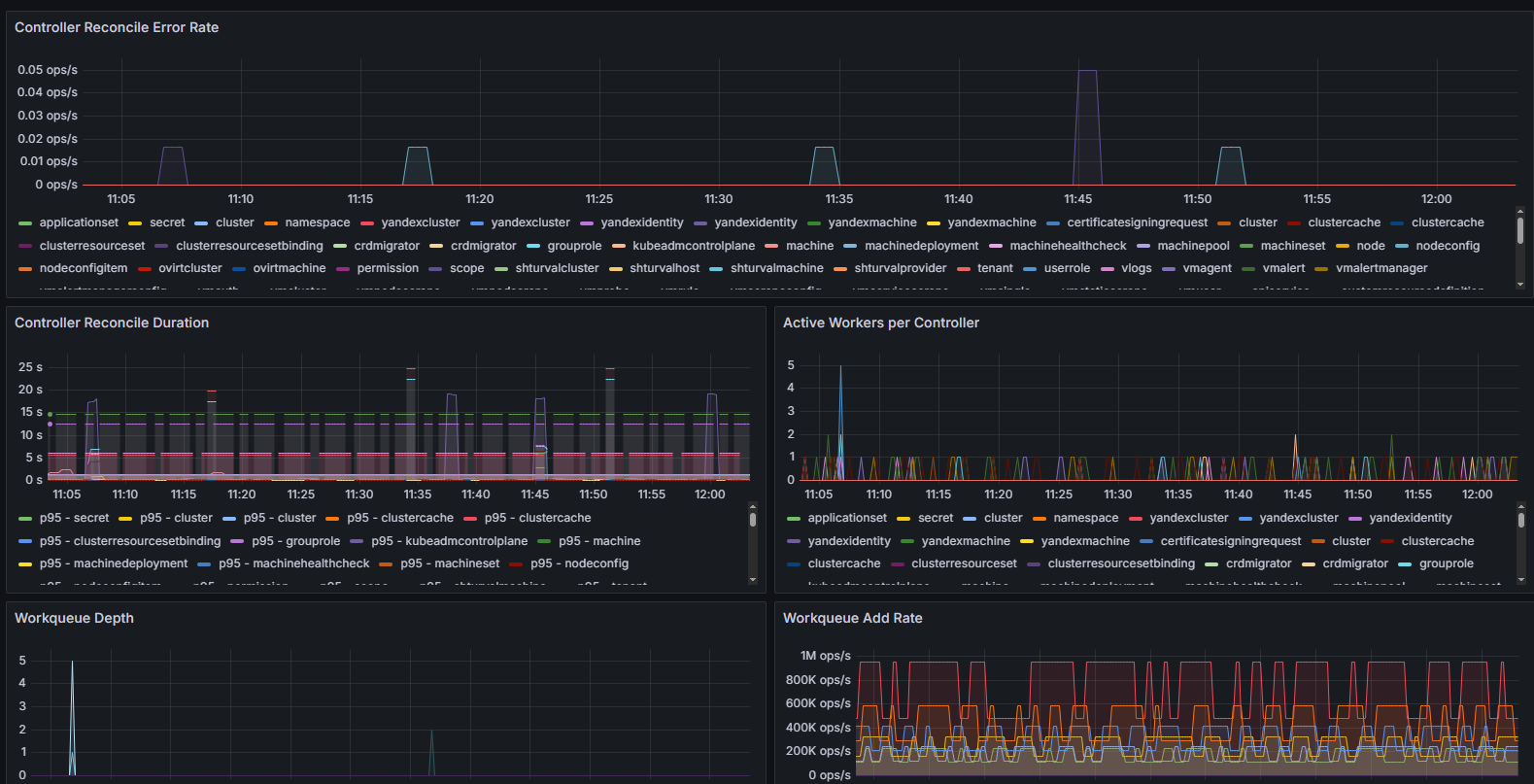
Структура дашборда
Метрики только на Control Plane
- Cluster Connection Status: Круговая диаграмма, отображающая состояние подключения к каждому кластеру. Использует минимальное значение метрики
capi_cluster_cache_connection_upпо именам и пространствам имен кластеров. Позволяет быстро определить, какие подключения активны. - Cluster Health Status: Отображает агрегированное состояние здоровья каждого кластера. Использует минимальное значение метрики
capi_cluster_cache_healthcheckс группировкой по имени и пространству имен кластера. - Controller Reconcile Error Rate: Временной график, показывающий скорость возникновения ошибок при согласовании контроллеров (
controller_runtime_reconcile_errors_total). Позволяет отслеживать стабильность работы контроллеров. - Controller Reconcile Duration: Временной график, отображающий 95-й и 50-й процентили длительности операций согласования для каждого контроллера, на основе гистограмм с Prometheus (
controller_runtime_reconcile_time_seconds_bucket). Это помогает анализировать производительность и задержки. - Active Workers per Controller: Временной график, отображающий количество активных воркеров (рабочих потоков) на каждый контроллер (
controller_runtime_active_workers), что позволяет оценить нагрузку и параллелизм выполнения. - Workqueue Depth: Временной график, показывающий глубину рабочих очередей контроллеров (
workqueue_depth), что помогает выявить потенциальные узкие места в обработке задач. - Workqueue Add Rate: Отображает скорость добавления новых задач в рабочие очереди контроллеров (
workqueue_adds_total), показывая уровень активности работы. - Webhook Latency (p95): Временной график с 95-м процентилем задержки webhook’ов контроллеров (
controller_runtime_webhook_latency_seconds_bucket), позволяющий выявлять проблемы с внешними вызовами. - SSA Cache Hit Rate: Временной график, отображающий процент попаданий в кэш SSA (Server-Side Apply) по каждому контроллеру и типу ресурса (
kind). Рассчитывается как отношение количества попаданий к общему числу запросов (= попадания + промахи). Важная метрика для оценки эффективности кэширования. - Memory Usage: Статусная панель, отображающая объем используемой памяти процесса в байтах (
go_memstats_alloc_bytes). - Goroutines: Панель, показывающая текущее количество активных горутин в процессе контроллера (
go_goroutines), что помогает отследить нагрузку на Go-рантайм. - Leader Election Status: Статус лидерства в рамках выбора Control Plane среди контроллеров (
leader_election_master_status) с именем лидера. - Certificate Errors: Отображает число ошибок чтения сертификатов (
certwatcher_read_certificate_errors_total), важная метрика для безопасности и корректной работы TLS. - Cluster Connection Details: Таблица с детализацией текущего состояния подключения к кластерам (
capi_cluster_cache_connection_up) с автоматическим форматированием по меткам.
Настраиваемые параметры
- Datasource: Позволяет выбрать источник данных, используемый для получения метрик.
- job: Фильтр по полю
job, который позволяет выбирать метрики по конкретным заданиям (jobs) в Prometheus. Опционально может включать все значения.
Данные параметры обеспечивают гибкую настройку источников данных и возможности фильтрации отображаемой информации по задачам мониторинга в кластерной среде.
Kube-VIP
Дашборд предназначен для мониторинга событий, связанных с работой сервиса Kube-VIP в Kubernetes-кластерах. Он позволяет отслеживать общее количество событий, распределение событий по типам и скорость возникновения событий во времени, что критично для анализа состояния сетевой виртуализации VIP-адресов в кластере. Используются метрики, собираемые Prometheus, что обеспечивает детальный и актуальный мониторинг сетевых сервисов и их событий.
Скриншот
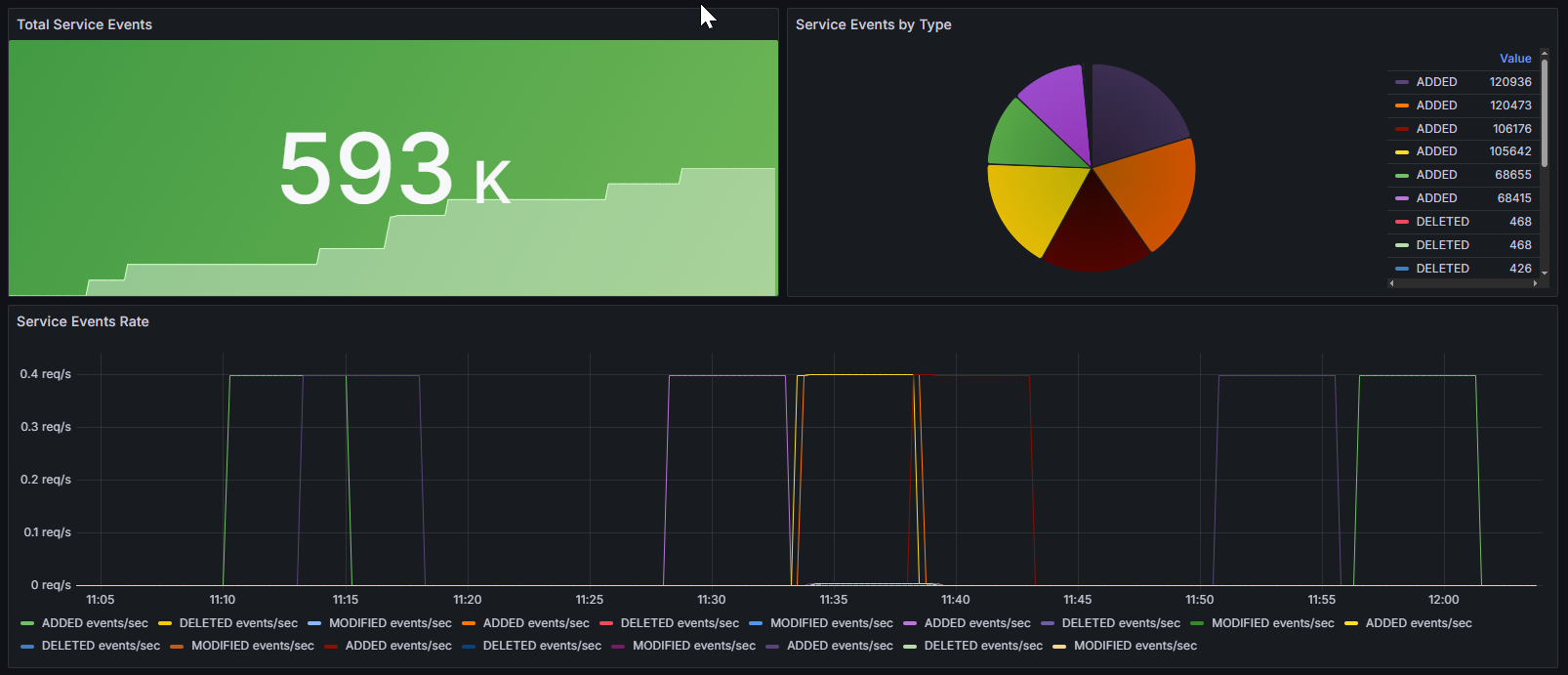
Структура дашборда
- Total Service Events: Отображает общее количество событий сервиса, агрегируя метрику
kube_vip_manager_all_services_events. Позволяет быстро оценить суммарный объём событий, связанных с Kube-VIP. - Service Events by Type: Круговая диаграмма, показывающая распределение всех событий по типам (
type) из метрикиkube_vip_manager_all_services_events. Это помогает визуально определить, какие типы событий преобладают и анализировать их соотношение. - Service Events Rate: Временной график, отображающий скорость возникновения событий различных типов (
type) по метрикеrate(kube_vip_manager_all_services_events[5m]). Позволяет оценить динамику и частоту появления событий, что важно для оперативного реагирования и анализа поведения системы.
Настраиваемые параметры
- datasource: Позволяет выбрать источник данных, используемый для получения метрик.