VictoriaMetrics и VictoriaLogs
VictoriaMetrics/vmagent
Дашборд предоставляет обширный обзор работы VictoriaMetrics vmagent версии 1.102.0 и выше. Он предназначен для мониторинга различных метрик, связанных с процессом сбора и обработки данных, а также выявления ошибок и производительности компонентов системы. Основные возможности дашборда включают отображение статистики о числе извлеченных образцов, уровнях загрузки ресурсов, ошибках и задержках при записи данных, что позволяет оперативно реагировать на возможные проблемы в инфраструктуре.
Структура дашборда
-
Stats:
- Samples scraped/s: Отображает частоту извлечения образцов из настроенных источников.
- Samples ingested/s: Показывает скорость обработки образцов в систему.
- Targets scraped/s: Отображает информацию о количестве целевых метрик, извлекаемых в секунду.
- Scrape targets: Отображает общее количество всех настроенных целей для извлечения метрик и состояние их работы (включено или выключено).
- Log errors (30m): Отображает количество ошибок, сгенерированных в логах за последние 30 минут.
- Persistent queue size: Отображает размер ожидающих образцов в байтах, которые не были отправлены в удаленное хранилище. Увеличение этого значения может указывать на проблемы с подключением.
- Uptime: Временной график, показывающий время работы экземпляров системы.
-
Overview:
- Samples rate ($instance): Временной график, показывающий скорость ввода и вывода образцов, включая модели push и pull.
- Persistent queue size ($instance) to ($url): Временной график, показывающий размер постоянной очереди ожидающих образцов, которые еще не были отправлены в удаленное хранилище, с акцентом на значения выше 2MB.
- Logging rate: Временной график, показывающий частоту логирования сообщений по уровню серьезности.
- Requests rate ($instance): Временной график, показывающий частоту запросов, обрабатываемых HTTP сервером vmagent.
- Errors rate ($instance):Временной график, показывающий частоту ошибок для различных метрик, что может указывать на проблемы с сетью или форматированием данных.
-
Resource usage:
- CPU ($instance): Временной график, показывающий использование процессора экземпляра.
- RSS memory % usage ($instance): Временной график, показывающий процент использования резидентной памяти (RSS) экземпляра.
- Disk writes/reads ($instance): Временной график, отображающий показатели записи/чтения данных из хранилища.
- Network usage ($instance): Временной график, показывающий скорость передачи данных, принимаемых и отправляемых vmagent.
- Open FDs usage % ($instance): Временной график, показывающий процент открытых дескрипторов файлов в ОС для каждого экземпляра.
- Goroutines ($instance): Временной график, показывающий количество горутин, выполняемых в экземпляре.
- CPU spent on GC ($instance): Временной график, показывающий процент использования процессора, занимаемого сборщиком мусора.
- Threads ($instance): Временной график, показывающий количество потоков, запущенных в экземпляре.
-
Troubleshooting:
- Top 10 jobs by unique samples: Временной график, показывающий 10 основных jobs по количеству новых зарегистрированных сервисов за последние 5 минут.
- Top 10 instances by unique samples: Временной график, показывающий 10 основных экземпляров по количеству новых зарегистрированных сервисов за последние 5 минут.
- Persistent queue write saturation ($instance): Временной график, показывающий показатели насыщения очереди записи для экземпляра.
- Persistent queue read saturation ($instance): Временной график, показывающий показатели насыщения очереди чтения для экземпляра.
- Data blocks dropped ($instance) to ($url): Отображает частоту сброшенных блоков данных при получении
400 Bad Requestи409 Conflictответов от удаленного хранилища. - Non-default flags: Таблица нестандартных флагов конфигурации, установленных для jobs и экземпляров.
-
Scraping:
- Scrape targets UP(By Type): Временной график, показывающий количество действующих целевых метрик по типам.
- Scrape targets DOWN(By Type): Временной график, показывающий количество недоступных целевых метрик по типам.
- Scrape rate ($instance): Временной график, показывающий число запросов на извлечение метрик в секунду.
- Scraped datapoints rate ($instance): Временной график, показывающий количество извлеченных данных в секунду.
- Scrape response size 0.99 quantile ($instance): Временной график, показывающий 99-й процентиль размера ответов на запросы.
- Scrape duration 0.99 quantile ($instance): Временной график, показывающий 99-й процентиль времени, необходимого для извлечения метрик.
- Scrape fails ($instance): Временной график, показывающий частоту сбоев при извлечении метрик.
-
Ingestion:
- Requests rate ($instance): Временной график, показывающий частоту запросов на запись данных в ingestserver и HTTP сервер.
- Rows rate ($instance): Временной график, показывающий частоту строк, загружаемых в vmagent через push-протоколы.
- Concurrent inserts ($instance): Временной график, показывающий количество одновременных вставок данных в систему.
- Error rate ($instance): Временной график, показывающий частоту ошибок при записи в ingestserver и HTTP Сервер.
-
Streaming aggregation:
- Matched samples ($instance): Отображает количество образцов, соответствующих правилам агрегации.
- Ignored samples ($instance): Отображает частоту игнорируемых образцов во время агрегации.
- Produced samples ($instance): Отображает количество созданных образцов по правилам агрегации.
- Flush timeouts ($instance): Отображает показатели таймаутов, возникающих во время дедупликации или агрегации.
- Samples lag 0.99 quantile ($instance): Отображает задержку между временными метками образцов внутри одной группы.
- Dedup flush duration 0.99 quantile ($instance): Отображает 99-й процентиль продолжительности очистки для агрегированных данных.
- Labels compressor ($instance): Временной график, показывающий размер компрессора меток по количеству записей.
-
Remote write:
- Requests rate ($instance) to ($url): Временной график, показывающий частоту запросов к удаленным конечным точкам.
- Bytes write rate ($instance): Временной график, показывающий глобальную скорость записи байтов через удаленные соединения.
- Retry rate ($instance) to ($url): Временной график, показывающий частоту повторных попыток запросов к удаленным конечным точкам.
- Connections ($instance): Временной график, показывающий текущее количество установленных соединений с удаленными конечными точками.
- Hourly series limit: Временной график, показывающий использование предела уникальных серий за час.
- Remote write connection saturation ($instance): Временной график, показывающий показатели насыщения соединений с удаленными хранилищами.
- Daily series limit: Временной график, показывающий использование предела уникальных серий за день.
-
Drilldown:
- CPU usage ($instance): Временной график, показывающий использование процессора экземпляра.
- RSS memory usage ($instance): Временной график, показывающий использование резидентной памяти экземпляра.
- Persistent queue size ($instance) to ($url): Временной график, показывающий размер постоянной очереди ожидающих образцов.
- Samples rate ($instance): Временной график, показывающий скорость ввода и вывода образцов для экземпляра.
- Disk writes/reads ($instance): Временной график, отображающий показатели Чтение/запись данных для экземпляра.
Настраиваемые параметры
- ds: Позволяет выбрать источник данных для использования в графиках.
- job: Позволяет выбрать конкретную задачу для фильтрации метрик на дашборде.
- instance: Позволяет выбрать конкретные экземпляры для отображения метрик.
- url: Позволяет выбрать URL для удаленной записи данных.
- adhoc: Позволяет добавить произвольные переменные для фильтрации данных.
VictoriaMetrics/vmalert
Дашборд предназначен для мониторинга системы управления оповещениями vmalert, которая входит в состав VictoriaMetrics. Он предоставляет обзор состояния и производительности различных правил оповещения и записи, а также ресурсных метрик, таких как использование памяти и процессоров. Дашборд позволяет пользователю отслеживать ошибки в выполнении правил, а также эффективность отправки оповещений в Alertmanager, что критически важно для обеспечения корректной работы системы оповещений.
Структура дашборда
-
Stats:
- Config update: Отображает статус последнего обновления конфигурации. Значение “Not Ok” указывает на наличие ошибок при обновлении.
- Alerting rules: Отображает общее количество загруженных правил оповещения для выбранных экземпляров и групп.
- Recording rules: Отображает общее количество загруженных правил записи для выбранных экземпляров и групп.
- Errors: Отображает общее количество ошибок, возникших в результате выполнения правил оповещения и записи.
- No data errors: Отображает количество правил записи, которые не выдают данные, что может указывать на ошибочную конфигурацию.
- Uptime: Временной график, показывающий статус доступности экземпляров vmalert.
-
Overview ($instance):
- Alerts fired total ($instance): Временной график, показывающий общее количество сработавших оповещений по каждой работе.
- Top $topk groups avg evaluation duration ($group): Временной график, показывающий топ $topk групп по времени выполнения оценок.
- Rules execution rate ($instance): Временной график, показывающий скорость выполнения запросов кDatasource.
- Rules execution errors ($instance): Временной график, показывающий частоту ошибок при выполнении правил.
-
Resource usage:
- Memory usage % ($instance): Временной график, показывающий процент использования памяти.
- Memory usage ($instance): Временной график, показывающий объем используемой памяти.
- CPU usage %($instance): Временной график, показывающий процент использования процессора.
- CPU usage ($instance): Временной график, показывающий максимальное количество используемых ядер.
- Open FDs usage % ($instance): Временной график, показывающий процент открытых дескрипторов файлов в операционной системе.
- Goroutines ($instance): Временной график, показывающий общее количество активных горутин.
-
Troubleshooting:
- Non-default flags: Таблица использования нестандартных флагов в системе.
- Missed evaluations ($instance): Временной график, показывающий количество пропущенных оценок, что может вызвать проблемы с уведомлениями.
- Restarts ($instance): Отображает количество перезапусков по каждому заданию, позволяя выявлять периодические проблемы.
-
Alerting rules ($instance):
- Top $topk active alerts ($group): Временной график, показывающий топ $topk активных правил срабатывания оповещений.
- Errors ($group): Временной график, показывающий события, когда выполнение правил привело к ошибкам.
- Pending ($group): Временной график, показывающий количество текущих ожидающих правил оповещения.
- Errors rate to Alertmanager: Временной график, показывающий частоту ошибок при отправке оповещений в Alertmanager.
- Requests rate to Alertmanager by job ($group): Временной график, показывающий количество оповещений, отправляемых в Alertmanager.
-
Recording rules ($instance):
- Top $topk rules by produced samples ($group): Временной график, показывающий топ $topk правил, генерирующих наибольшее количество образцов.
- Rules with 0 produced samples ($group): Временной график, показывающий правила, которые не генерируют образцы.
- Errors ($group): Временной график, показывающий ошибки, возникшие во время выполнения правил записи.
-
Remote write:
- Datapoints send rate ($instance): Временной график, показывающий скорость отправки данных через удаленные подключения.
- Datapoints drop rate ($instance): Временной график, показывающий количество точек данных, отбрасываемых при отправке.
- Connections ($instance): Временной график, показывающий количество установленных соединений с удаленными конечными точками.
- Bytes write rate ($instance): Временной график, показывающий глобальную скорость записи байтов через удаленные подключения.
Настраиваемые параметры
- ds: Позволяет выбрать источник данных для использования в графиках.
- job: Позволяет выбрать конкретную задачу для фильтрации метрик на дашборде.
- instance: Позволяет выбрать конкретные экземпляры для отображения метрик.
- group: Позволяет выбрать группу, чтобы отобразить метрики только для определенных групп.
- topk: Позволяет определить количество топовых метрик, отображаемых в некоторых панелях.
- adhoc: Позволяет добавить произвольные переменные для фильтрации данных.
VictoriaMetrics/vmauth
Дашборд предоставляет обзор работы системы аутентификации для VictoriaMetrics (vmauth) версии 1.80.0 и выше. Он предназначен для мониторинга ключевых метрик, связанных с работой и эффективностью системы аутентификации. Интеграция с VM Agent позволяет отслеживать состояние и производительность, обеспечивая возможность настраивания различных параметров для более детального анализа.
Структура дашборда
-
Stats:
- Uptime: Временной график, показывающий суммарное время работы, позволяя видеть зависимость от заданного интервала.
- Config update: Показывает успешность последнего обновления конфигурации, где “Not Ok” указывает на ошибку при обновлении.
- Requests rate: Отображает скорость обработки запросов в системе.
- Users count: Показывает общее количество пользователей, определенных в конфигурационном файле.
- Errors rate: Отображает частоту ошибок в обработке запросов.
- Version: Таблица с версиями приложения.
-
Overview:
- Requests rate: Временной график, отображающий скорость поступления запросов с разбивкой по пользователям.
- User concurrent requests usage: Временной график, отображающий процент использования разрешенных параллельных запросов по пользователям.
- Requests rejected rate: Временной график, отображающий скорость отклоненных запросов с указанием причины.
- Concurrent limit reached: Отображает случаи, когда количество параллельных соединений достигло лимита, с рекомендациями по действиям.
- User requests duration: Временной график, показывающий продолжительность запросов пользователей по квантилям.
-
Resource usage:
- RSS memory % usage ($instance): Временной график, показывающий процент использования резидентной памяти, критичный для производительности.
- CPU % usage ($instance): Временной график, показывающий процент использования CPU, показывающий загруженность системы.
- Memory usage ($instance): Временной график, показывающий различные показатели использования памяти.
- CPU ($instance): Временной график, показывающий использование CPU и доступные лимиты.
- TCP connections ($instance): Временной график, показывающий количество активных TCP соединений.
- TCP connections rate ($instance): Временной график, показывающий скорость нового подключения по TCP.
- Open FDs ($instance): Временной график, показывающий процент открытых файловых дескрипторов по отношению к установленному лимиту.
- Goroutines ($instance): Временной график, показывающий количество горутин в системе.
- Threads ($instance): Временной график, показывающий количество потоков.
-
Troubleshooting:
- Non-default flags: Таблица, отображающая флаги, не установленные по умолчанию.
- Log errors: Временной график, показывающий количество ошибок и предупреждений в логах, что может указывать на проблемы с соединением или неправильную конфигурацию.
Настраиваемые параметры
- ds: Позволяет выбрать источник данных для использования в графиках.
- job: Позволяет выбрать конкретную задачу для фильтрации метрик на дашборде.
- instance: Позволяет выбрать конкретные экземпляры для отображения метрик.
- user: Позволяет выбрать пользователя из списка для дальнейшего анализа запросов.
- adhoc: Позволяет добавить произвольные переменные для фильтрации данных.
VictoriaMetrics/cluster
Дашборд предоставляет обширные возможности для отслеживания производительности и состояния компонентов кластера, включая статистику о потреблении ресурсов, частоту запросов, метрики ингрессии данных и уровень ошибок. Дашборд поддерживает гибкость в выборе источников данных, что способствует глубинному анализу работы системы.
Структура дашборда
-
Stats:
- Total datapoints: Отображает общее количество данных, хранящихся в системе.
- Ingestion rate: Показывает скорость поступления данных, включая коэффициент репликации.
- Read requests: Отображает частоту HTTP-запросов на чтение.
- Available CPU: Показывает общее количество доступных процессоров для всех компонентов VictoriaMetrics.
- Active series: Отображает количество активных временных рядов с новыми данными за последний час.
- Disk space usage: Отображает информацию о занимаемом дисковом пространстве.
- Bytes per point: Отображает среднее значение дискового пространства, занимаемого одним временным рядом.
- Available memory: Отображает общее количество доступной оперативной памяти для всех компонентов VictoriaMetrics.
- Uptime ($job): Временной график, показывающий время работы компонента.
-
Overview:
- Datapoints ingestion rate ($instance): Временной график, показывающий количество данных, поступающих в кластер в секунду.
- Requests rate ($instance): Временной график, показывающий различные метрики, включая команды на вставку и чтение.
- Active time series ($instance): Временной график, показывающий количество активных временных рядов за последний час.
- Query duration 0.99 quantile ($instance): Временной график, показывающий время обработки запросов на чтение.
- Requests error rate ($instance): Временной график, показывающий уровень ошибок при выполнении запросов.
- Logging rate: Временной график, показывающий частоту логирования сообщений по уровням.
-
Resource usage ($job):
- RSS memory % usage ($instance): Временной график, показывающий условие использования RSS (резервной) памяти.
- RSS anonymous memory % usage ($instance): Временной график, показывающий использование анонимной памяти.
- CPU ($instance): Временной график, показывающий использование процессора.
- Disk writes/reads ($instance): Временной график, показывающий данные по чтениям и записям на диск.
- Open FDs usage % ($instance): Временной график, показывающий процент используемых дескрипторов файлов.
- Disk write/read calls ($instance): Временной график, показывающий количество системных вызовов на чтение/запись.
- Goroutines ($instance): Временной график, показывающий использование горутин в приложении.
- TCP connections ($instance): Временной график, показывающий текущее количество TCP-соединений.
- Threads ($instance): Временной график, показывающий текущее количество потоков приложения.
- CPU pressure: Временной график, показывающий нагрузки на CPU. Разработка функционала запланирована
- Memory pressure: Временной график, показывающий нагрузки на память. Разработка функционала запланирована
- IO pressure: Временной график, показывающий нагрузки на ввод-вывод. Разработка функционала запланирована
- CPU spent on GC ($instance): Временной график, показывающий процент CPU, затраченный на сборку мусора.
- TCP connections rate ($instance): Временной график, показывающий частоту новых TCP соединений.
- Go scheduling latency: Время, которое горутины (goroutines) проводят в состоянии ожидания запуска. Повышенные значения могут указывать на нехватку CPU или процессорное троттлирование.
- Memory allocations rate: Временной график, показывающий скорость аллокации памяти.
-
Troubleshooting:
- Churn rate ($instance): Временной график, показывающий частоту создания новых рядов за последние 24 часа.
- Slow inserts: Временной график, показывающий процент медленных вставок относительно общего числа вставок.
- Storage in readonly status for vminsert ($instance): Отображает статус доступности vmstorage.
- Slow queries % ($instance): Временной график, показывающий процент медленных запросов.
- Assisted merges ($instance): Временной график, показывающий количество ассистированных слияний данных в хранилище.
- Cache usage % by type ($instance): Временной график, показывающий использование кэша по типам.
- Cache miss ratio ($instance): Временной график, показывающий отношение пропусков кэша.
- Deduplication rate ($instance) : Показывает скорость устранения дубликатов данных в процессе обработки.
- Samples dropped for last 1h ($instance): Отображает количество отбрасываемых образцов данных с разбивкой по причинам.
- Partial query results ($instance): Отображает количество частичных результатов запросов из-за недоступности некоторых узлов.
- Restarts ($instance): Отображает количество рестартов процессов.
-
Interconnection ($job):
- Rows ($instance): Показывает количество строк, переданных и полученных.
- RPC errors ($instance): Отображает ошибки связи между узлами.
- Rows ($instance) rerouted to: Отображает количество переадресованных строк.
- Pending: Временной график, показывающий состояние текущих активных запросов.
- Rows ($instance) rerouted from: Показывает количество строк, переадресованных с vmstorage.
- RPC network usage ($instance): Отображает сетевую активность, связанную с протоколами внутреннего RPC.
-
vmstorage ($instance):
- Ingestion rate ($instance): Временной график, показывающий скорость поступления данных в узлы хранилища.
- CPU usage % ($instance): Временной график, показывающий использование CPU для компонента хранилища.
- Memory (anon) usage % ($instance): Временной график, показывающий использование оперативной памяти для компонентов хранилища.
- Concurrent selects ($instance): Временной график, показывающий одновременное число запросов на чтение.
- Concurrent flushes on disk ($instance): Временной график, показывающий текущий и максимальный уровень параллельных операций записи на диск.
- Merge speed: Временной график, показывающий скорость слияния данных на узлах хранения.
- Active merges ($instance): Временной график, показывающий максимальное количество слияний, происходящих в данный момент.
- LSM parts max by type ($instance): Временной график, показывающий максимальное количество частей LSM-дерева для разных типов данных.
- Disk space usage % ($instance): Временной график, показывающий процент использования дискового пространства.
- Pending datapoints ($instance): Временной график, показывающий количество отложенных для записи данных и индексных записей.
- Disk space usage % by type ($instance): Временной график, показывающий процент использования дискового пространства по типам (data points и indexdb).
- Readonly mode: Отображает статус режима “только чтение” для хранилища.
- Network usage ($instance): Временной график, показывающий сетевую активность хранилища по чтению и записи.
- Number of snapshots: Временной график, показывающий количество сделанных снимков данных.
-
vmselect ($instance):
- Requests rate ($instance): Временной график, показывающий частоту запросов, принятых узлами vmselect.
- Concurrent selects ($instance): Временной график, показывающий текущее и максимальное количество параллельных запросов.
-
vminsert ($instance):
- Requests rate ($instance): Временной график, показывающий частоту запросов для узлов vminsert.
- Concurrent inserts ($instance): Временной график, показывающий количество параллельных вставок.
- CPU usage % ($instance): Временной график, показывающий использование CPU vminsert.
- Memory (anon) usage % ($instance): Временной график, показывающий использование анонимной памяти процессом vminsert.
- Storage connection saturation ($instance): Временной график, показывающий уровень насыщения соединений между vminsert и vmstorage.
- Storage reachability ($instance): Временной график, показывающий доступность узлов vmstorage для vminsert.
- Network usage: clients ($instance): Временной график, показывающий сетевую нагрузку между vminsert и клиентами.
- Network usage: vmstorage ($instance): Временной график, показывающий сетевую нагрузка между vminsert и vmstorage.
- Rows per insert ($instance): Временной график, показывающий максимальное число рядов, вставляемых за один запрос.
-
Drilldown:
- RSS memory usage ($instance): Временной график, показывающий использование памяти (резервной).
- Storage full ETA ($instance): Временной график, показывающий приблизительное время, необходимое для достижения 100% дискового пространства.
- RSS anonymous memory usage ($instance): Временной график, показывающий использование анонимной памяти (резервной).
- CPU usage ($instance): Временной график, показывающий суммарное использование CPU.
- Storage full ETA ($instance): Временной график, показывающий приблизительное время до заполнения диска до 100% с учётом скорости вставки и компрессии.
- Disk space usage ($instance): Временной график, показывающий занятое дисковое пространство.
- Disk space usage by type ($instance): Временной график, показывающий использования дискового пространства по типу данных.
- Logging rate: Временной график, показывающий скорость записи логов по уровням и местоположению.
Настраиваемые параметры
- ds: Позволяет выбрать источник данных для использования в графиках.
- job: Позволяет выбрать конкретную задачу для фильтрации метрик на дашборде.
- job_insert: Позволяет фильтровать выборку данных для операций вставки.
- job_select: Позволяет фильтровать выборку данных для операций выборки.
- job_storage: Позволяет фильтровать выборку данных для операций с хранилищем.
- instance: Позволяет выбрать конкретные экземпляры для отображения метрик.
- adhoc: Позволяет добавить произвольные переменные для фильтрации данных.
VictoriaMetrics/Cluster Per Tenant Statistic
Дашборд предоставляет возможность отслеживать и анализировать данные по каждому арендатору. Основные возможности дашборда включают мониторинг скорости инжекции данных, частоты запросов чтения, активности временных рядов и использования дискового пространства. Это является важным инструментом для выявления узких мест, оптимизации работы кластера и поддержки принятия оперативных решений в области хранения и обработки данных.
Структура дашборда
Не полностью использован функционал тенантов
-
Statistics:
- Datapoints ingestion rate: Временной график, показывающий количество точек данных, вставляемых в хранилище в секунду с разбивкой по accountID и projectID.
- Read query rate: Временной график, показывающий частоту запросов, принимаемых узлами vmselect для каждого арендатора.
- Active time series: Отображает количество активных временных рядов с новыми данными, вставленными в течение последнего часа. Высокое значение может указывать на замедление процесса инжекции данных.
- Time spent on queries, seconds: Временной график, показывающий потраченное время на выполнение запросов для каждого арендатора в секунду.
- Disk space usage (datapoints only): Показывает объем дискового пространства, занимаемого только точками данных. Нет возможности различить статистику по арендаторам для indexdb.
- New series over 24h: Отображает количество новых временных рядов, созданных за последние 24 часа.
-
Billing:
- Ingestion Rate Top 5, by account id: Круговая диаграмма, показывающая топ-5 аккаунтов по скорости инжекции данных.
- Read query rate, Top 5, by account id: Круговая диаграмма, показывающая топ-5 аккаунтов по частоте запросов чтения.
- Time spent on queries, seconds, Top 5, by account id: Круговая диаграмма, показывающая топ-5 аккаунтов по времени, проведенному на запросах.
- Active time series, Top 5, by account id: Круговая диаграмма, показывающая топ-5 аккаунтов по количеству активных временных рядов.
- Disk space usage, Top 5, by account id: Круговая диаграмма, показывающая топ-5 аккаунтов по использованию дискового пространства.
- New series over 24h, Top 5, by account id: Круговая диаграмма, показывающая топ-5 аккаунтов по количеству новых временных рядов, созданных за последние 24 часа.
Настраиваемые параметры
- ds: Позволяет выбрать источник данных для использования в графиках.
- account: Позволяет выбрать фильтровать данные по идентификатору аккаунта. Пользователь может выбрать один или несколько аккаунтов для анализа.
- project: Позволяет фильтровать данные по идентификатору проекта для выбранного аккаунта. Опция включает возможность выбора нескольких проектов.
- adhoc: Позволяет добавить произвольные переменные для фильтрации данных.
VictoriaMetrics/operator
Дашборд позволяет отслеживать ключевые метрики производительности и состояния, относящиеся к управлению объектами в кластере Kubernetes. С помощью этого дашборда пользователи могут быстро оценить общее состояние системы, а также выявить и диагностировать проблемы на уровне контроллеров и ресурсов.
Структура дашборда
-
Overview:
- Version: Отображает текущую версию оператора.
- CRD Objects count by controller: Панель типа “stat”, показывающая количество объектов в кластере Kubernetes для каждого контроллера.
- Uptime: Панель типа “stat”, отображающая время работы системы на каждом экземпляре.
- Reconciliation rate by controller: Панель типа “timeseries”, отображающая скорость выполнения операций согласования для каждого контроллера.
- Log message rate: Панель типа “timeseries”, показывающая частоту логирования сообщений в зависимости от уровня логирования.
- Prometheus Objects watchers: Отображает суммарное количество watchers, отслеживающих объекты Prometheus Operator (например, ServiceMonitors, PodMonitors) по неймспейсам.
- Elected Leaders: Показывает количество экземпляров оператора, которые получили статус лидера. Значение выше 1 указывает на возможные проблемы с поведением операторов и требует проверки логов.
- Active workers: Показывает количество активных воркеров, выполняющих reconcile задачи.
- Prometheus Converter Watch events: Временной график количества событий обработки объектов Prometheus Operator оператором, разбитый по типам событий и типам объектов.
-
Troubleshooting:
- reconcile errors by controller: Панель типа “timeseries”, отображающая ошибки согласования по контроллерам. Ненулевые значения указывают на проблемы с определением объектов CR или с подключением к API Kubernetes.
- throttled reconcilation events: Панель типа “timeseries”, показывающая количество событий согласования, которые были ограничены. Это помогает снизить нагрузку на кластер Kubernetes и повысить производительность оператора.
- Working queue depth: Панель типа “timeseries”, отображающая количество объектов, ожидающих обработки в очереди. Ненулевые значения указывают на трудности оператора в обработке изменений объектов CR.
- Reconcilation latency by controller: Панель типа “timeseries”, показывающая задержку согласования для каждого контроллера. Высокая задержка может указывать на проблемы с производительностью оператора.
- reconcile errors by controller: Временной график, показывающий количество ошибок reconcile для каждого контроллера. Ненулевые значения свидетельствуют о проблемах с определением CR объектов или о проблемах взаимодействия с Kubernetes API.
- throttled reconciliation config events: Отображает количество событий конфигурации reconcile, которые были ограничены оператором для предотвращения перегрузки (по умолчанию до 5 событий на 2 секунды).
- Working queue depth: Временной график, показывающий глубину очереди объектов, ожидающих обработки reconcile. Ненулевые значения могут указывать на недостаток ресурсов оператора.
- Reconciliation latency by controller: Латентность выполнения reconcile операций (99-й процентиль) по контроллерам. Для stateful контроллеров латентность до 3 секунд допускается, для остальных - выше 2 секунд может свидетельствовать о проблемах.
- Rest client requests: Временной график, показывающий количество HTTP-запросов к Kubernetes API с разбивкой по методам и кодам ответов.
- Concurrent reconcile ($instance): Показывает текущее и максимальное число одновременных reconcile задач для каждого инстанса оператора. Постоянное достижение максимума сигнализирует о необходимости увеличения ресурсов или параметров конфигурации.
- Go scheduling latency: Время, которое горутины (goroutines) проводят в состоянии ожидания запуска. Повышенные значения могут указывать на нехватку CPU или процессорное троттлирование.
- rest client latency: Латентность HTTP-запросов к Kubernetes API, разбитая по методам и API.
-
resources:
- Memory usage ($instance): Временной график, показывающий использование памяти для каждого экземпляра, включая запрашиваемую системную память, память, находящуюся в использовании, и резидентную память.
- CPU ($instance): Временной график, показывающий использование CPU для каждого экземпляра.
- Goroutines ($instance): Временной график, показывающий количество горутин для каждого экземпляра.
- GC duration ($instance): Временной график, показывающий среднюю длительность сборки мусора для каждого экземпляра.
Настраиваемые параметры
- ds: Позволяет выбрать источник данных для использования в графиках.
- job: Позволяет выбрать конкретную задачу для фильтрации метрик на дашборде.
- instance: Позволяет выбрать конкретные экземпляры для отображения метрик.
- version: Позволяет выбрать версию приложения для анализа метрик.
VictoriaLogs/cluster
Дашборд предназначен для мониторинга кластера версии VictoriaLogs v1.22.0 и выше. Он предоставляет обзор статистики и показателей производительности системы логирования, включая количество записей, скорость их обработки, использование ресурсов и метрики производительности. Основные возможности дашборда включают отслеживание инджестирования логов, использования дискового пространства, доступных ресурсов (CPU и памяти) и анализ производительности запросов.
Скриншот
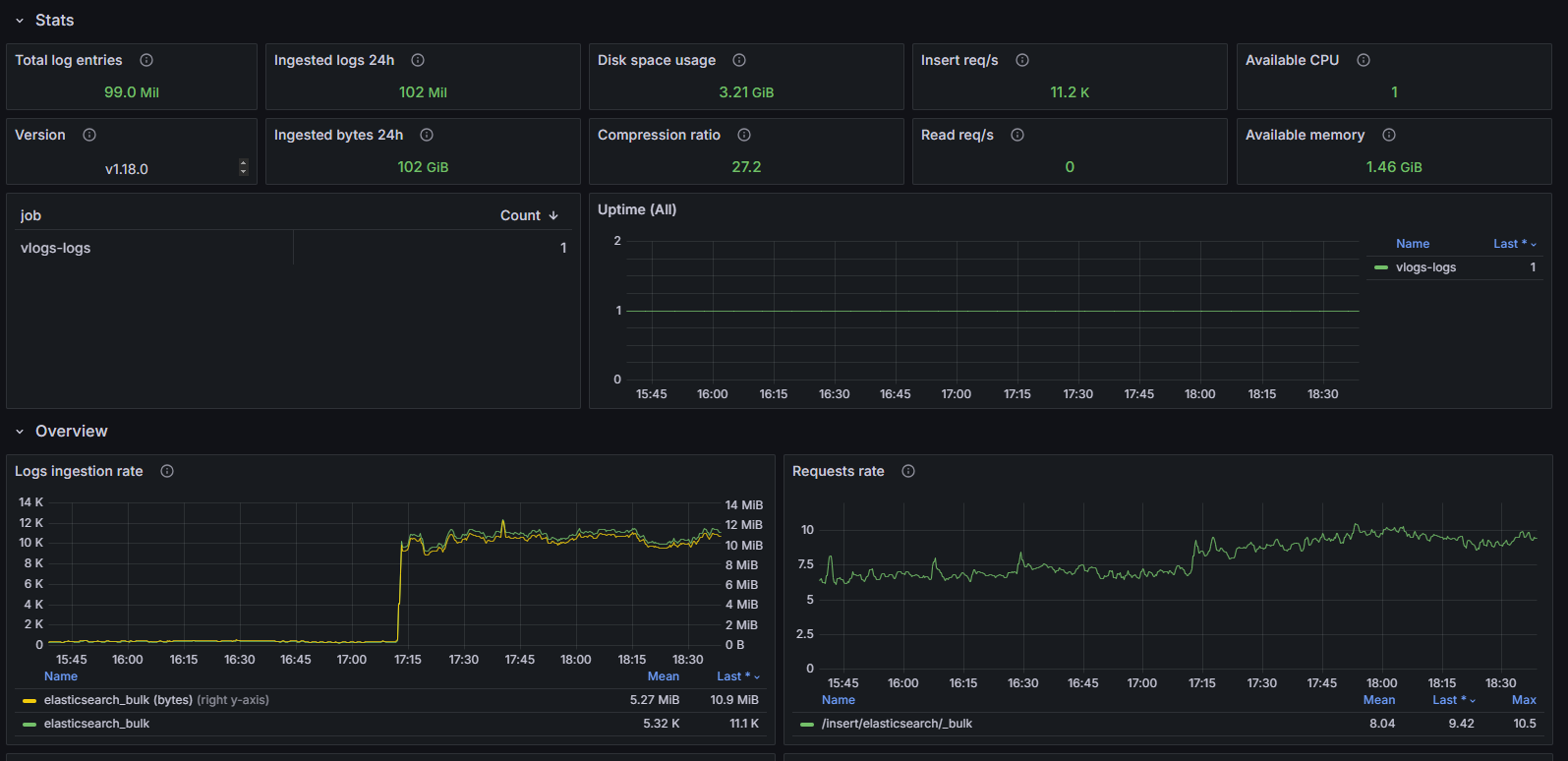
Структура дашборда
-
Stats:
- Total log entries: Отображает общее количество записей логов в хранилище.
- Ingested logs 24h: Отображает показатель накопленного количества записей логов, инджестированных за последние 24 часа.
- Disk space usage: Отображает общий объем используемого дискового пространства, учитывая все сжатые записи логов и размер индексов.
- Insert req/s: Отображает среднюю скорость инджестирования записей логов.
- Available CPU: Отображает общее количество доступных процессоров для процесса VictoriaLogs.
- Ingested bytes 24h: Отображает показатель накопленного общего объема данных, инджестированных за последние 24 часа, учитываемый до сжатия.
- Compression ratio: Отображает отношение между оригинальным размером данных и сжатыми данными, хранящимися на диске.
- Read req/s: Отображает скорость HTTP-запросов на чтение.
- Available memory: Отображает общий объем доступной памяти для процесса VictoriaLogs.
- Uptime ($job): Отображает показатель времени работы для конкретной задачи.
-
Overview:
- Logs ingestion rate: Временной график, показывающий скорость инджестирования в количестве записей и байтов в секунду.
- Requests rate: Временной график, показывающий частоту HTTP-запросов по различным путям.
- Requests error rate: Временной график, показывающий частоту ошибок HTTP-запросов.
- Query duration 0.99 quantile: Временной график, показывающий время выполнения запросов для 99% наименьших значений.
- Disk space usage: Временной график, показывающий объема дискового пространства, занятого всеми данными в хранилище.
- Logging rate: ПВременной график, показывающий скорость логирования сообщений по уровням.
-
Troubleshooting:
- Restarts: Отображате количество перезапусков для задачи.
- Log stream churn rate: Временной график, показывающий число новых потоков логов, созданных за последние 24 часа.
- Non-default flags: Таблица с флагами, установленными не по умолчанию значения.
- Logs dropped for last 1h: Временной график, показывающий количество записей логов, игнорируемых или отклоняемых при инджестировании.
-
Resource usage:
- RSS memory % usage ($instance): Временной график, показывающий процент использованной оперативной памяти (resident memory) процесса.
- CPU % usage ($instance): Временной график, показывающий процент использования CPU процессом.
- RSS anonymous memory % usage ($instance): Временной график, показывающий долю памяти, выделенной самим процессом.
- CPU pressure: Временной график, показывающий нагрузки на CPU. Разработка функционала запланирована
- Memory pressure: Временной график, показывающий нагрузки на память. Разработка функционала запланирована
- Disk writes/reads ($instance): Временной график, показывающий количество прочитанных и записанных байтов на уровень хранения.
- Open FDs ($instance): Временной график, показывающий процент открытых файловых дескрипторов по отношению к лимиту, установленному в ОС.
- Disk write/read calls ($instance): Временной график, показывающий количество системных вызовов чтения/записи.
- Goroutines ($instance): Временной график, показывающий текущее количество горутин.
- IO pressure: Временной график, показывающий нагрузки на ввод-вывод. Разработка функционала запланирована
- Threads ($instance): Временной график, показывающий текущее количество потоков.
- TCP connections ($instance): Временной график, показывающий количество активных TCP соединений.
- CPU spent on GC ($instance): Временной график, показывающий процент CPU, затраченный на сборку мусора.
- TCP connections rate ($instance): Временной график, показывающий частоту новых TCP соединений.
- Memory allocations rate: Временной график, показывающий скорость аллокации памяти.
- Go scheduling latency: График, показывающий время проведенное горутинами в состоянии ожидания до начала выполнения.
Настраиваемые параметры
- ds: Позволяет выбрать источник данных для использования в графиках.
- job: Позволяет выбрать конкретную задачу для фильтрации метрик на дашборде.
- instance: Позволяет выбрать инстанс, отслеживаемого в рамках задачи.
- version: Позволяет выбрать конкретную версию приложения для анализа.
- adhoc: Позволяет добавить произвольные переменные для фильтрации данных.
VictoriaLogs/single-node
Дашборд представляет собой инструмент для мониторинга производительности и состояния хранения логов в VictoriaLogs. Данный дашборд предоставляет пользователю все необходимые метрики для оценки состояния системы и ее ресурсов, включая количество обрабатываемых логов, использование дискового пространства, а также текущую загрузку CPU и памяти. Он позволяет оперативно выявлять и диагностировать проблемы, обеспечивая высокую доступность и надежность логирования.
Скриншот
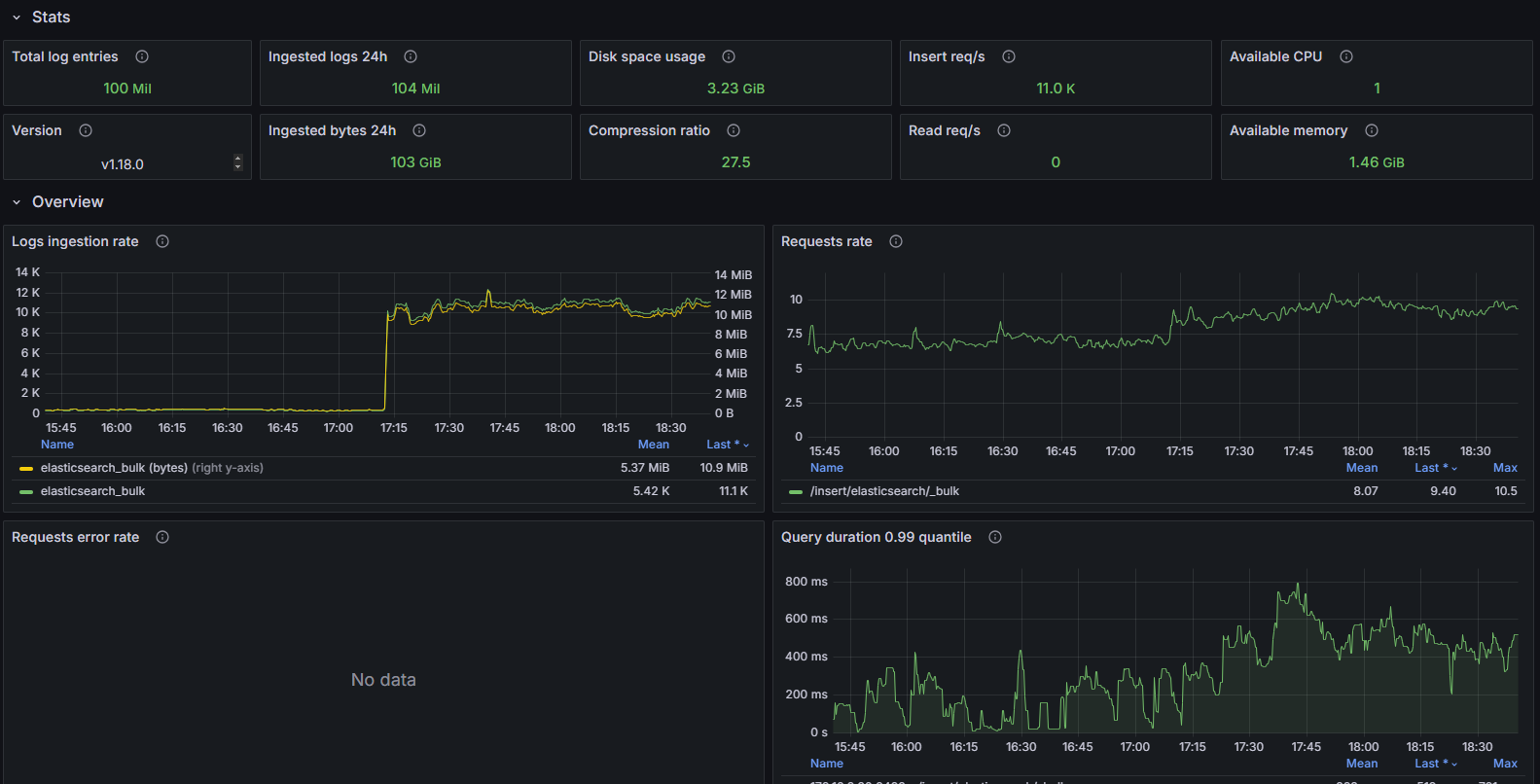
Структура дашборда
-
Stats:
- Total log entries: Отображает общее количество записей логов в хранилище.
- Ingested logs 24h: Отображает общее количество записей логов, загруженных за последние 24 часа.
- Disk space usage: Отображает общий объем используемого дискового пространства, учитывающий сжатые записи логов и размер индекса.
- Insert req/s: Отображает среднюю скорость загрузки записей логов.
- Available CPU: Отображает общее количество доступных процессоров для процесса VictoriaLogs.
- Ingested bytes 24h: Отображает общее количество байт, загруженных за последние 24 часа до сжатия.
- Compression ratio: Отображает соотношение между оригинальным размером данных и сжатым размером, хранящимся на диске.
- Read req/s: Показывает скорость HTTP-запросов на чтение.
- Available memory: Отображает общий объем доступной памяти для процесса VictoriaLogs.
- Version: Отображает ссылку на последние релизы VictoriaLogs.
-
Overview:
- Logs ingestion rate: Временной график, показывающий скорость загрузки логов в записях и байтах в секунду.
- Requests rate: Временной график, показывающий скорость HTTP-запросов по различным путям.
- Requests error rate: Временной график, показывающий частоту ошибок запросов.
- Query duration 0.99 quantile: Временной график, показывающий время выполнения запросов по 99-му процентилю.
- Disk space usage: Временной график, показывающий объем дискового пространства, занятого всеми данными в хранилище.
- Logging rate: Временной график, показывающий скорость логирования сообщений по уровням.
-
Troubleshooting:
- Restarts: Отображает количество перезапусков по каждому заданию, позволяя выявлять периодические проблемы.
- Log stream churn rate: Временной график, показывающий количество созданных новых потоков логов за последние 24 часа.
- Non-default flags: Таблица с флагами, установленными на значения, отличные от значений по умолчанию.
- Logs dropped for last 1h: Временной график, показывающий количество записей логов, которые были проигнорированы или сброшены при вставке.
-
Resource usage:
- RSS memory % usage ($instance): Временной график, показывающий процент использованной памяти (resident).
- CPU % usage ($instance): Временной график, показывающий процент использования CPU.
- RSS anonymous memory % usage ($instance): Временной график, показывающий процент анонимной памяти, выделенной процессом.
- CPU ($instance): Временной график, показывающий использование CPU и доступные ядра.
- Memory usage ($instance): Временной график, показывающий использование памяти в различных разрезах.
- CPU pressure: Временной график, показывающий давление на CPU на основе информации о давлении (PSI). Разработка функционала запланирована
- Memory pressure: Временной график, показывающий давление на память по данным PSI. Разработка функционала запланирована
- Disk writes/reads ($instance): Временной график, показывающий количество байт, считываемых/записываемых из/в хранилище.
- Goroutines ($instance): Временной график, показывающий общее количество горутин (независимые функции, которые выполняются параллельно).
- Disk write/read calls ($instance): Временной график, показывающий количество вызовов системных вызовов чтения/записи.
- Threads ($instance): Временной график, показывающий общее количество потоков.
- IO pressure: Временной график, показывающий давление на ввод-вывод на основе PSI. Разработка функционала запланирована
- TCP connections rate ($instance): Временной график, показывающий скорость установленных TCP-соединений.
- TCP connections ($instance): Временной график, показывающий общее количество текущих TCP-соединений.
- Go scheduling latency: График, показывающий время, проведенное горутиной в состоянии ожидания.
- Open FDs ($instance): Временной график, показывающий процент открытых файловых дескрипторов по сравнению с установленным лимитом.
Настраиваемые параметры
- ds: Позволяет выбрать источник данных для использования в графиках.
- job: Позволяет выбрать конкретную задачу для фильтрации метрик на дашборде.
- instance: Позволяет выбрать конкретные экземпляры для отображения метрик.
- version: Позволяет выбрать конкретную версию приложения для анализа.
- adhoc: Позволяет добавить произвольные переменные для фильтрации данных.