Управление узлами
На странице Управление узлами доступно управление группами узлов, конфигурацией групп узлов, а также управлением объектами healthchecks для групп узлов кластера.
На странице есть вкладки:
Вкладка Группы узлов
Страница разделена на блоки:
- Control Plane, в которую входят Control Plane узлы;
- Workers, в которую входят группы Worker-узлов.
Для группы Control Plane узлов и каждой группы Worker-узлов отображено:
- количество узлов в группе;
- количество работающих узлов в группе (узлы со статусом ready).
Скриншот
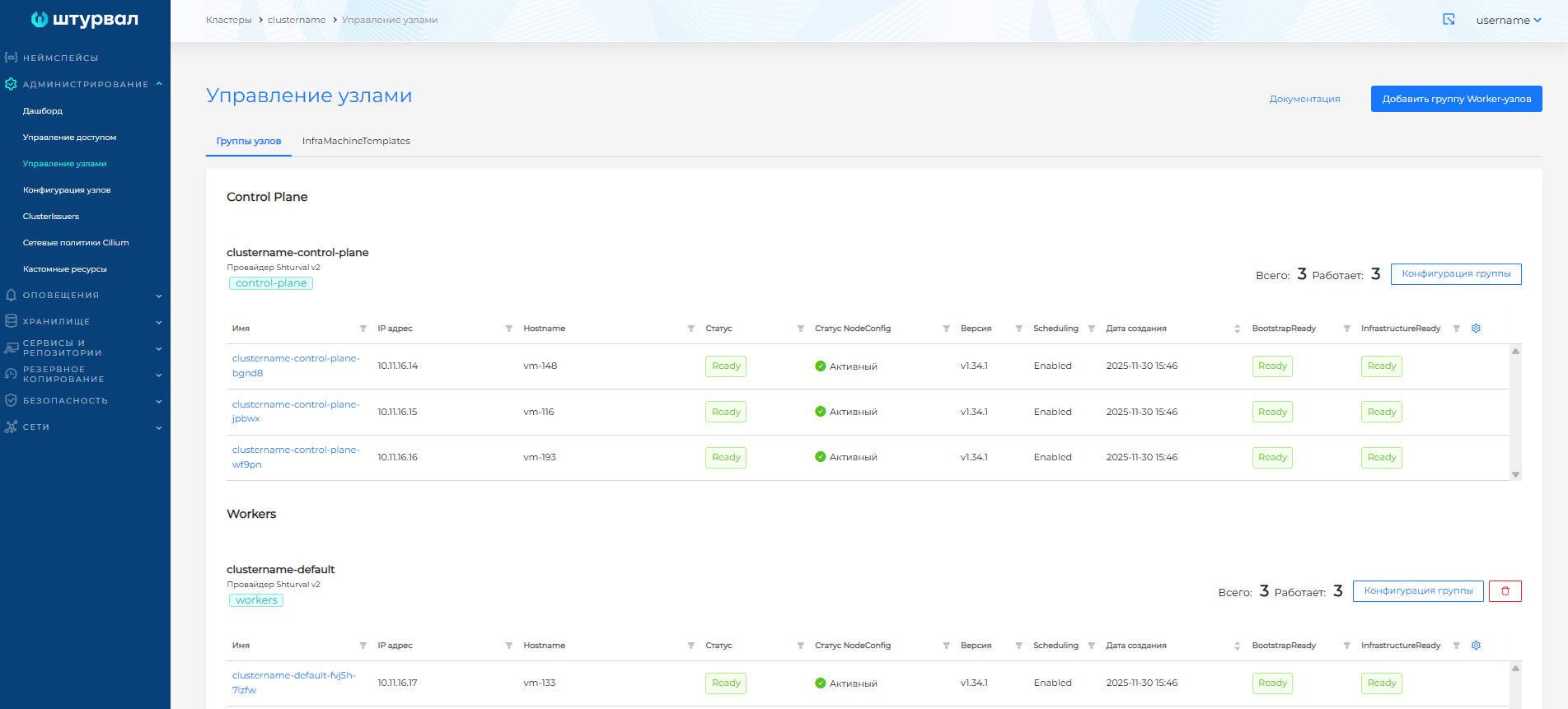
В таблицах для Control Plane и Workers вы можете настроить параметры отображения. Для этого нажмите на шестеренку в правом верхнем углу таблицы отображения узлов и выберите необходимые параметры.
Группам узлов присваивается провайдер, выбранный при создании кластера.
Нажатие на имя узла приводит к переходу на страницу узла.
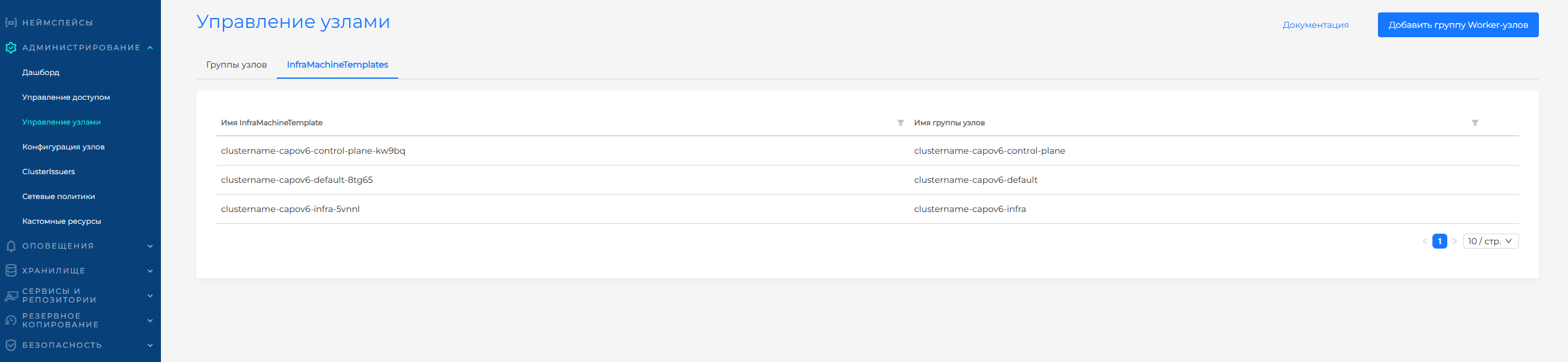
Вкладка InfraMachineTemplates
При изменении инфраструктурного шаблона в конфигурации группы узлов кластера происходит создание нового инфраструктурного шаблона (InfraMachineTemplate). Все инфраструктурные шаблоны для этого кластера доступны на вкладке InfraMachineTemplates страницы Управление узлами. Доступно удаление шаблонов, не привязанных к группам узла.
Скриншот
Вкладка Неопознанные узлы
Вкладка Неопознанные узлы доступна в случае, если в кластере были выявлены узлы без связи с машинами. Вы можете удалить неопознанный узел из кластера.
Поведение системы при отказе/недоступности узла
В случае отказа/недоступности узла кластер начинает перераспределять нагрузку с этого узла на другие только спустя 30-60 секунд. Это связано с настройками мониторинга здоровья узлов в kube-controller-manager, а так же настройкой kubelet.
Kubelet периодически уведомляет Kube-APIserver о своём статусе с интервалом, заданным в параметре --node-status-update-frequency. Значение по умолчанию 10 секунд.
Controller manager проверяет статус Kubelet каждые –-node-monitor-period. Значение по умолчанию 5 секунд.
Если Kubelet сообщит статус в пределах установленного значения --node-monitor-grace-period, то Controller manager считает, что узел исправен.
В случае отказа узла кластера происходит следующий алгоритм:
-
Kubelet отправляет свой статус Kube-APIserver в соответствии с параметром
nodeStatusUpdateFrequency= 10 сек. -
Допустим, узел выходит из строя.
-
Controller manager будет пытаться проверить статус узла (от Kubelet) каждые 5 сек (согласно параметру
--node-monitor-period). -
Controller manager определит, что узел не отвечает, и даст ему тайм-аут
--node-monitor-grace-periodв 40 сек. Если за это время Controller manager не сочтет узел исправным, он установит статус NotReady.
В этом сценарии будут возможны ошибки при обращении к Pods, работающим на этом узле, потому что Pods будут продолжать получать трафик до тех пор, пока узел не будет считаться неработающим (NotReady) через 45 сек.
Чтобы увеличить скорость реакции Kubernetes на отказ узлов кластера, вы можете изменить параметры:
-
--nodeStatusUpdateFrequency(по умолчанию 10 сек) в конфиге Kubelet /var/lib/kubelet/config.yaml; -
--node-monitor-period(по умолчанию 5 сек ); -
--node-monitor-grace-period(по умолчанию 40 сек).
Обратите внимание! При уменьшении этих показателей вы увеличиваете риск ложного срабатывания недоступности узла, например, при высокой загрузке узла или временной сетевой недоступности узла. Это может привести к тому, что приложения и нагрузка в кластере будут перераспределяться на другие узлы без действительной необходимости.
Подробнее в официальной документации Kubernetes.